【转】[翻译] [RabbitMQ+Python入门经典] 兔子和兔子窝
转自 http://blog.ftofficer.com/2010/03/translation-rabbitmq-python-rabbits-and-warrens/
2010年3月14日 Zhang Cong 发表评论 阅读评论
RabbitMQ作为一个工业级的消息队列服务器,在其客户端手册列表的Python段当中推荐了一篇blog,作为RabbitMQ+Python的入门手册再合适不过了。不过,正如其标题Rabbit and Warrens(兔子和养兔场)一样,这篇英文写的相当俏皮,以至于对于我等非英文读者来说不像一般的技术文档那么好懂,所以,翻译一下吧。翻译过了,希望其他人可以少用一些时间。翻译水平有限,不可能像原文一样俏皮,部分地方可能就意译了,希望以容易懂为准。想看看老外的幽默的,推荐去看原文,其实,也不是那么难理解……
原文:http://blogs.digitar.com/jjww/2009/01/rabbits-and-warrens/
兔子和兔子窝
当时我们的动机很简单:从生产环境的电子邮件处理流程当中分支出一个特定的离线分析流程。我们开始用的MySQL,将要处理的东西放在表里面,另一个程序从中取。不过很快,这种设计的丑陋之处就显现出来了…… 你想要多个程序从一个队列当中取数据来处理?没问题,我们硬编码程序的个数好了……什么?还要能够允许程序动态地增加和减少的时候动态进行压力分配?
是的,当年我们想的简单的东西(做一个分支处理)逐渐变成了一个棘手的问题。以前拿着锤子(MySQL)看所有东西都是钉子(表)的年代是多么美好……
在搜索了一下之后,我们走进了消息队列(message queue)的大门。不不,我们当然知道消息队列是什么,我们可是以做电子邮件程序谋生的。我们实现过各种各样的专业的,高速的内存队列用来做电子邮件处理。我们不知道的是那一大类现成的、通用的消息队列(MQ)服务器——无论是用什么语言写出的,不需要复杂的装配的,可以自然的在网络上的应用程序之间传送数据的一类程序。不用我们自己写?看看再说。
让大家看看你们的Queue吧……
过去的4年里,人们写了有好多好多的开源的MQ服务器啊。其中大多数都是某公司例如LiveJournal写出来用来解决特定问题的。它们的确不关心上面跑的是什么类型的消息,不过他们的设计思想通常是和创建者息息相关的(消息的持久化,崩溃恢复等通常不在他们考虑范围内)。不过,有三个专门设计用来做及其灵活的消息队列的程序值得关注:
Apache ActiveMQ 曝光率最高,不过看起来它有些问题,可能会造成丢消息。不可接受,下一个。
ZeroMQ 和 RabbitMQ 都支持一个开源的消息协议,成为AMQP。AMQP的一个优点是它是一个灵活和开放的协议,以便和另外两个商业化的Message Queue (IBM和Tibco)竞争,很好。不过ZeroMQ不支持消息持久化和崩溃恢复,不太好。剩下的只有RabbitMQ了。如果你不在意消息持久化和崩溃恢复,试试ZeroMQ吧,延迟很低,而且支持灵活的拓扑。[特点:支持消息持久化的开源项目]
剩下的只有这个吃胡萝卜的家伙了……

当我读到它是用Erlang写的时候,RabbitMQ震了我一下。Erlang 是爱立信开发的高度并行的语言,用来跑在电话交换机上。是的,那些要求6个9的在线时间的东西。在Erlang当中,充斥着大量轻量进程,它们之间用消息传递来通信。听起来思路和我们用消息队列的思路是一样的,不是么?
而且,RabbitMQ支持持久化。是的,如果RabbitMQ死掉了,消息并不会丢失,当队列重启,一切都会回来。而且,正如在DigiTar(注:原文作者的公司)做事情期望的那样,它可以和Python无缝结合。除此之外,RabbitMQ的文档相当的……恐怖。如果你懂AMQP,这些文档还好,但是有多少人懂AMQP?这些文档就像MySQL的文档假设你已经懂了SQL一样……不过没关系啦。
好了,废话少说。这里是花了一周时间阅读关于AMQP和关于它如何在RabbitMQ上工作的文档之后的一个总结,还有,怎么在Python当中使用。
开始吧
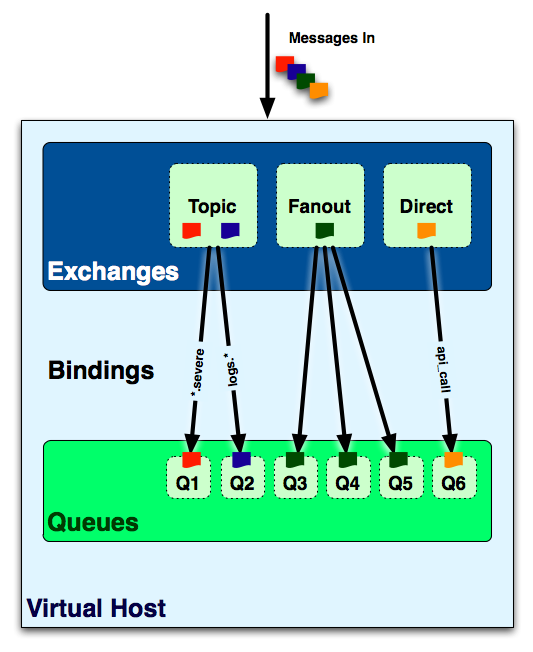
AMQP当中有四个概念非常重要:虚拟主机(virtual host),交换机(exchange),队列(queue)和绑定(binding)。一个虚拟主机持有一组交换机、队列和绑定。为什么需要多个虚拟主机呢?很简单,RabbitMQ当中,用户只能在虚拟主机的粒度进行权限控制。因此,如果需要禁止A组访问B组的交换机/队列/绑定,必须为A和B分别创建一个虚拟主机。每一个RabbitMQ服务器都有一个默认的虚拟主机“/”。如果这就够了,那现在就可以开始了。
交换机,队列,还有绑定……天哪!
刚开始我思维的列车就是在这里脱轨的…… 这些鬼东西怎么结合起来的?
队列(Queues)是你的消息(messages)的终点,可以理解成装消息的容器。消息就一直在里面,直到有客户端(也就是消费者,Consumer)连接到这个队列并且将其取走为止。不过。你可以将一个队列配置成这样的:一旦消息进入这个队列,biu~,它就烟消云散了。这个有点跑题了……
需要记住的是,队列是由消费者(Consumer)通过程序建立的,不是通过配置文件或者命令行工具。这没什么问题,如果一个消费者试图创建一个已经存在的队列,RabbitMQ就会起来拍拍他的脑袋,笑一笑,然后忽略这个请求。因此你可以将消息队列的配置写在应用程序的代码里面。这个概念不错。
OK,你已经创建并且连接到了你的队列,你的消费者程序正在百无聊赖的敲着手指等待消息的到来,敲啊,敲啊…… 没有消息。发生了什么?你当然需要先把一个消息放进队列才行。不过要做这个,你需要一个交换机(Exchange)……
交换机可以理解成具有路由表的路由程序,仅此而已。每个消息都有一个称为路由键(routing key)的属性,就是一个简单的字符串。交换机当中有一系列的绑定(binding),即路由规则(routes),例如,指明具有路由键 “X” 的消息要到名为timbuku的队列当中去。先不讨论这个,我们有点超前了。
你的消费者程序要负责创建你的交换机们(复数)。啥?你是说你可以有多个交换机?是的,这个可以有,不过为啥?很简单,每个交换机在自己独立的进程当中执行,因此增加多个交换机就是增加多个进程,可以充分利用服务器上的CPU核以便达到更高的效率。例如,在一个8 核的服务器上,可以创建5个交换机来用5个核,另外3个核留下来做消息处理。类似的,在RabbitMQ的集群当中,你可以用类似的思路来扩展交换机一边获取更高的吞吐量。
OK,你已经创建了一个交换机。但是他并不知道要把消息送到哪个队列。你需要路由规则,即绑定(binding)。一个绑定就是一个类似这样的规则:将交换机“desert(沙漠)”当中具有路由键“阿里巴巴”的消息送到队列“hideout(山洞)”里面去。换句话说,一个绑定就是一个基于路由键将交换机和队列连接起来的路由规则。例如,具有路由键“audit”的消息需要被送到两个队列,“log-forever”和“alert-the- big-dude”。要做到这个,就需要创建两个绑定,每个都连接一个交换机和一个队列,两者都是由“audit”路由键触发。在这种情况下,交换机会复制一份消息并且把它们分别发送到两个队列当中。交换机不过就是一个由绑定构成的路由表。
现在复杂的东西来了:交换机有多种类型。他们都是做路由的,不过接受不同类型的绑定。为什么不创建一种交换机来处理所有类型的路由规则呢?因为每种规则用来做匹配分子的CPU开销是不同的。例如,一个“topic”类型的交换机试图将消息的路由键与类似“dogs.*”的模式进行匹配。匹配这种末端的通配符比直接将路由键与“dogs”比较(“direct”类型的交换机)要消耗更多的CPU。如果你不需要“topic”类型的交换机带来的灵活性,你可以通过使用“direct”类型的交换机获取更高的处理效率。那么有哪些类型,他们又是怎么处理的呢?
Fanout Exchange – 不处理路由键。你只需要简单的将队列绑定到交换机上。一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。Fanout交换机转发消息是最快的。
Direct Exchange – 处理路由键。需要将一个队列绑定到交换机上,要求该消息与一个特定的路由键完全匹配。这是一个完整的匹配。如果一个队列绑定到该交换机上要求路由键 “dog”,则只有被标记为“dog”的消息才被转发,不会转发dog.puppy,也不会转发dog.guard,只会转发dog。
Topic Exchange – 将路由键和某模式进行匹配。此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“*”匹配不多不少一个词。因此“audit.#”能够匹配到“audit.irs.corporate”,但是“audit.*” 只会匹配到“audit.irs”。我在RedHat的朋友做了一张不错的图,来表明topic交换机是如何工作的:
Source: Red Hat Messaging Tutorial: 1.3 Topic Exchange
持久化这些小东西们
你花了大量的时间来创建队列、交换机和绑定,然后,砰~服务器程序挂了。你的队列、交换机和绑定怎么样了?还有,放在队列里面但是尚未处理的消息们呢?
放松~如果你是用默认参数构造的这一切的话,那么,他们,都,biu~,灰飞烟灭了。是的,RabbitMQ重启之后会干净的像个新生儿。你必须重做所有的一切,亡羊补牢,如何避免将来再度发生此类杯具?
队列和交换机有一个创建时候指定的标志durable,直译叫做坚固的。durable的唯一含义就是具有这个标志的队列和交换机会在重启之后重新建立,它不表示说在队列当中的消息会在重启后恢复。那么如何才能做到不只是队列和交换机,还有消息都是持久的呢?
但是首先一个问题是,你真的需要消息是持久的吗?对于一个需要在重启之后回复的消息来说,它需要被写入到磁盘上,而即使是最简单的磁盘操作也是要消耗时间的。如果和消息的内容相比,你更看重的是消息处理的速度,那么不要使用持久化的消息。不过对于我们@DigiTar来说,持久化很重要。
当你将消息发布到交换机的时候,可以指定一个标志“Delivery Mode”(投递模式)。根据你使用的AMQP的库不同,指定这个标志的方法可能不太一样(我们后面会讨论如何用Python搞定)。简单的说,就是将 Delivery Mode设置成2,也就是持久的(persistent)即可。一般的AMQP库都是将Delivery Mode设置成1,也就是非持久的。所以要持久化消息的步骤如下:
- 将交换机设成 durable。
- 将队列设成 durable。
- 将消息的 Delivery Mode 设置成2 。
就这样,不是很复杂,起码没有造火箭复杂,不过也有可能犯点小错误。
下面还要罗嗦一个东西……绑定(Bindings)怎么办?我们无法在创建绑定的时候设置成durable。没问题,如果你绑定了一个 durable的队列和一个durable的交换机,RabbitMQ会自动保留这个绑定。类似的,如果删除了某个队列或交换机(无论是不是 durable),依赖它的绑定都会自动删除。
注意两点:
- RabbitMQ 不允许你绑定一个非坚固(non-durable)的交换机和一个durable的队列。反之亦然。要想成功必须队列和交换机都是durable的。
- 一旦创建了队列和交换机,就不能修改其标志了。例如,如果创建了一个non-durable的队列,然后想把它改变成durable的,唯一的办法就是删除这个队列然后重现创建。因此,最好仔细检查创建的标志。
开始喂蛇了~
【译注】说喂蛇是因为Python的图标是条蛇。
AMQP的一个空白地带是如何在Python当中使用。对于其他语言有一大坨材料。
- Java – http://www.rabbitmq.com/java-client.html
- .NET – http://www.rabbitmq.com/releases/rabbitmq-dotnet-client/v1.5.0/rabbitmq-dotnet-client-1.5.0-user-guide.pdf
- Ruby – http://somic.org/2008/06/24/ruby-amqp-rabbitmq-example/
但是对Python老兄来说,你需要花点时间来挖掘一下。所以我写了这个,这样别的家伙们就不需要经历我这种抓狂的过程了。
首先,我们需要一个Python的AMQP库。有两个可选:
- py-amqplib – 通用的AMQP
- txAMQP – 使用 Twisted 框架的AMQP库,因此允许异步I/O。
根据你的需求,py-amqplib或者txAMQP都是可以的。因为是基于Twisted的,txAMQP可以保证用异步IO构建超高性能的AMQP程序。但是Twisted编程本身就是一个很大的主题……因此清晰起见,我们打算用 py-amqplib。更新:请参见Esteve Fernandez关于txAMQP的使用和代码样例的回复。
AMQP支持在一个TCP连接上启用多个MQ通信channel,每个channel都可以被应用作为通信流。每个AMQP程序至少要有一个连接和一个channel。
from amqplib import client_0_8 as amqp conn = amqp.Connection(host="localhost:5672 ", userid="guest", password="guest", virtual_host="/", insist=False) chan = conn.channel()
每个channel都被分配了一个整数标识,自动由Connection()类的.channel()方法维护。或者,你可以使用.channel(x)来指定channel标识,其中x是你想要使用的channel标识。通常情况下,推荐使用.channel()方法来自动分配 channel标识,以便防止冲突。
现在我们已经有了一个可以用的连接和channel。现在,我们的代码将分成两个应用,生产者(producer)和消费者(consumer)。我们先创建一个消费者程序,他会创建一个叫做“po_box”的队列和一个叫“sorting_room”的交换机:
chan.queue_declare(queue="po_box", durable=True, exclusive=False, auto_delete=False) chan.exchange_declare(exchange="sorting_room", type="direct", durable=True, auto_delete=False,)
这段代码干了啥?首先,它创建了一个名叫“po_box”的队列,它是durable的(重启之后会重新建立),并且最后一个消费者断开的时候不会自动删除(auto_delete=False)。在创建durable的队列(或者交换机)的时候,将auto_delete设置成false是很重要的,否则队列将会在最后一个消费者断开的时候消失,与durable与否无关。如果将durable和auto_delete都设置成True,只有尚有消费者活动的队列可以在RabbitMQ意外崩溃的时候自动恢复。
(你可以注意到了另一个标志,称为“exclusive”。如果设置成True,只有创建这个队列的消费者程序才允许连接到该队列。这种队列对于这个消费者程序是私有的)。
还有另一个交换机声明,创建了一个名字叫“sorting_room”的交换机。auto_delete和durable的含义和队列是一样的。但是,.excange_declare() 还有另外一个参数叫做type,用来指定要创建的交换机的类型(如前面列出的): fanout, direct 和 topic.
到此为止,你已经有了一个可以接收消息的队列和一个可以发送消息的交换机。不过我们需要创建一个绑定,把它们连接起来。
chan.queue_bind(queue=”po_box”, exchange=”sorting_room”,
routing_key=”jason”)
这个绑定的过程非常直接。任何送到交换机“sorting_room”的具有路由键“jason” 的消息都被路由到名为“po_box” 的队列。
现在,你有两种方法从队列当中取出消息。第一个是调用chan.basic_get(),主动从队列当中拉出下一个消息(如果队列当中没有消息,chan.basic_get()会返回None, 因此下面代码当中print msg.body 会在没有消息的时候崩掉):
msg = chan.basic_get("po_box")
print msg.body
chan.basic_ack(msg.delivery_tag)但是如果你想要应用程序在消息到达的时候立即得到通知怎么办?这种情况下不能使用chan.basic_get(),你需要用chan.basic_consume()注册一个新消息到达的回调。
def recv_callback(msg): print 'Received: ' + msg.body
chan.basic_consume(queue='po_box', no_ack=True,
callback=recv_callback, consumer_tag="testtag")
while True:
chan.wait()
chan.basic_cancel("testtag")chan.wait() 放在一个无限循环里面,这个函数会等待在队列上,直到下一个消息到达队列。chan.basic_cancel() 用来注销该回调函数。参数consumer_tag 当中指定的字符串和chan.basic_consume() 注册的一直。在这个例子当中chan.basic_cancel() 不会被调用到,因为上面是个无限循环…… 不过你需要知道这个调用,所以我把它放在了代码里。
需要注意的另一个东西是no_ack参数。这个参数可以传给chan.basic_get()和chan.basic_consume(),默认是false。当从队列当中取出一个消息的时候,RabbitMQ需要应用显式地回馈说已经获取到了该消息。如果一段时间内不回馈,RabbitMQ 会将该消息重新分配给另外一个绑定在该队列上的消费者。另一种情况是消费者断开连接,但是获取到的消息没有回馈,则RabbitMQ同样重新分配。如果将no_ack 参数设置为true,则py-amqplib会为下一个AMQP请求添加一个no_ack属性,告诉AMQP服务器不需要等待回馈。但是,大多数时候,你也许想要自己手工发送回馈,例如,需要在回馈之前将消息存入数据库。回馈通常是通过调用chan.basic_ack()方法,使用消息的delivery_tag属性作为参数。参见chan.basic_get() 的实例代码。
好了,这就是消费者的全部代码。(下载:amqp_consumer.py)
不过没有人发送消息的话,要消费者何用?所以需要一个生产者。下面的代码示例表明如何将一个简单消息发送到交换区“sorting_room”,并且标记为路由键“jason” :
msg = amqp.Message("Test message!")
msg.properties["delivery_mode"] = 2
chan.basic_publish(msg,exchange="sorting_room",routing_key="jason")你也许注意到我们设置消息的delivery_mode属性为2,因为队列和交换机都设置为durable的,这个设置将保证消息能够持久化,也就是说,当它还没有送达消费者之前如果RabbitMQ重启则它能够被恢复。
剩下的最后一件事情(生产者和消费者都需要调用的)是关闭channel和连接:
chan.close() conn.close()
很简单吧。(下载:amqp_publisher.py)
来真实地跑一下吧……
现在我们已经写好了生产者和消费者,让他们跑起来吧。假设你的RabbitMQ在localhost上安装并且运行。
打开一个终端,执行python ./amqp_consumer.py让消费者运行,并且创建队列、交换机和绑定。
然后在另一个终端运行python ./amqp_publisher.py “AMQP rocks.” 。如果一切良好,你应该能够在第一个终端看到输出的消息。
付诸使用吧
我知道这个教程是非常粗浅的关于AMQP/RabbitMQ和如何使用Python访问的教程。希望这个可以说明所有的概念如何在Python当中被组合起来。如果你发现任何错误,请联系原作者(williamsjj@digitar.com) 【译注:如果是翻译问题请联系译者】。同时,我很高兴回答我知道的问题。【译注:译者也是一样的】。接下来是,集群化(clustering)!不过我需要先把它弄懂再说。
注:关于RabbitMQ的知识我主要来自这些来源,推荐阅读:
–完–


