1:引擎还是要改进一下:动画显示很慢,没有达到指定的fps的效果【不明白】,
在有的机器上怎么cpu在85%以上,fps越高,cpu越厉害,但是这里26 fps就这么慢了【不明白】
2:音乐格式FF不支持mp3,但是ogg都支持。wav的播放很卡,safari还好。ie9不支持ogg,支持mp3和aac
3:对于坐标系统,要注意相对坐标高宽的变化,最好每次会只是都计算(要计算zoom比),因为如果canvas是百分比高宽的时候,浏览器的resize会导致绘制的图形压缩或扩大。
4:ie9需要设置html5 doctype才能运行canvas,其它的浏览器即使你用的html4 doctype也可以。
5:ie9不支持new Audio,但是document.createElement('audio');可以
Continue reading html5开发连连看问题
2009-06-12 10:04
Data Guard 是Oracle的远程复制技术,它有物理和逻辑之分,但是总的来说,它需要在异地有一套独立的系统,这是两套硬件配置可以不同的系统,但是这两套系统的软件结构保持一致,包括软件的版本,目录存储结构,以及数据的同步(其实也不是实时同步的),这两套系统之间只要网络是通的就可以了,是一种异地容灾的解决方案。而对于RAC,则是本地的高可用集群,每个节点用来分担不用或相同的应用,以解决运算效率低下,单节点故障这样的问题,它是几台硬件相同或不相同的服务器,加一个SAN(共享的存储区域)来构成的。
Data Guard由两个多两个以上的独立的数据库构成,他们各自有各自的存储,Oracle负责他们之间的切换和数据同步
双机热备由两台计算机和一个共享存储设备构成,通过第三方软件(HA Rose等)实现切换,不需要做数据同步
建议应用RAC+Dataguard ,RAC保证可用性,Dataguard在RAC组独立磁盘上和另外一台主机上,保证可靠性。
双机就是人们所说的双机热备,数据库放在共享设备上,同一时刻只能有一台主机接管,另一台待用,这种方式只能保护实例,不能保护db,而且备机长期处于闲置,对资源是一种极大的浪费!
如果原本是双机,建议转换为RAC
规划好应用,DML操作从一个节点跑,查询操作从另一个节点跑,通常不需要太多调优就可以利用闲置的另外一台机器了
RAC服务器共用一套存储,同时提供服务,没有主备之分.宕一个其它的可以继续服务.
双机热备,共用一套存储,一个提供服务一个备份,主机宕了切换到备份服务器提供服务.
data guard 完全两套系统,存储是单独的,用日志同步.
RAC: 实例层冗余
DG :数据库层冗余
热备:仅仅只是数据冗余
个人理解:
RAC :实例冗余,而且还可以做到数据库的loadbalance。
DG :多份数据,所以能做到数据冗余,但是只有主节点提供服务。
热备:与RAC最大的差异可能就是RAC有多个实例,一个数据库。而热备只是一个实例,一个数据库。所以做不了并发和loadbalance。
Oracle RAC只是做Oracle的应用,rose,legato还可以做其它的
HA:是High Availability 的首字母组合,翻译过来,可以叫做高可用,或高可用性,高可用(环境)。我觉得应该说HA是一个观念而不是一项或一系列具体技术,就象网格一样。作过系统方案就知道了,评价系统的性能当中就有一项高可用。广义的高可用涉及到系统的各个方面,简单来说,让系统不会中断 运行,就是高可用。包括软件的高可用,硬件的高可用,网络的高可用等等。具体实现的方案包括操作系统的集群,数据库的集群,硬件的冗余,网络的冗余等等。做HA方面的软件,有IBM的HACMP(很多常用AIX的人,常说的HA就指HACMP,乱啊)、SUN的Sun Cluster、HP的MC/SG等。
在 2000年以前,大家谈HA,大部分时候说的是操作系统一级的双机热备,主流产品当时有IBM HACMP4.1,HP的MC/SG啥版本忘了,sun的系统很多人不用VCS,用的是一个叫dataware的东西。现在很多人眼中的HA也还是这样。时至今日,HA包括的东西可就多了,先不说其他方面,单就数据库,单就Oracle,与HA相关的产品先后有:高级复制(AdvanceRepication)、OPS/RAC(Real Application Cluster)、数据卫士(Data Guard)、oracle流(Oracle Streams)、分区(Oracle Partition)这样数款产品。照这么说,RAC只是HA这个概念下的一个具体产品而已!目前为止,只有RAC和分区是Oracle要收取 licence的,其他的,只要给经验丰富的第三方实施方付一定的规划/设计及部署费用就可以了;当然,也可以自己照着文档依葫芦画瓢,但是这样弄出的环境是否能达到高可用就难说了。事实上,大部分人所说的HA,还是狭义上的HA,也就是OS一级的双机热备。
RAC:是real application cluster的简称,它是在多个主机上运行一个数据库的技术,即是一个db多个instance。它的好处是 可以由多个性能较差的机器构建出一个整体性能很好的集群,并且实现了负载均衡,那么当一个节点出现故障时,其上的服务会自动转到另外的节点去执行,用户甚 至感觉不到什么。
双机热备(HA)和RAC有啥区别呢?
1、对于硬件来说,基本上一样,共享存储、光纤线(也有还用SCSI线的)、多台小型机(可以做多节点的相互热备,也可以做多节点的RAC)、光纤交换机(如果是用光纤卡的话);但做RAC,在主机之间,最好使用高带宽网络交换机(虽然不用也可以做成);因此硬件成本相差不大。
2、软件呢,差别可不小。如果是双机热备,必须买操作系统级的双机管理软件;如果是RAC,目前还是建议购买双机管理软件(尽管10g的crs+asm可以摆脱双机软件了,但ASM目前实在太难伺候了),当然还得买RAC license。
3、日常维护。RAC要求的技术含量更高,也应该更勤快。最关键的是得买oracle服务,否则遇到有些问题(bug),你就比单机还不高可用了。
4、优缺点。这个,看看RAC的官方论述吧。如果能用好,确实是很有好处的。目前我们的40多个客户的使用情况来看,RAC确实大大降低了他们的downtime,另一方面可以说就是提高了生产力咯。
Dataguard:一般是出于容灾的目的。是主数据库的备用库(standby 库)通过自动传送和接受archivelog,并且在dataguard库自动apply 这些log,从而达到和主数据库同步的目的,可能dataguard 库是建立的异地的,当主库所在的区域出现了致命性的灾难时(火灾、地震等),主库没法修复时,这时可以切换dataguard 为主库的模式,对外提供服务,而它的数据基本是当前最新的。目前可能大家对于 dataguard 库的使用已经拓展出了其他更多的用途,比如备份,跑报表等等 |
Continue reading 【转】双机/RAC/Dataguard的区别
一、中国工商银行上海数据中心数据备份和恢复的需求
1.1. 用户的需求
中国工商银行上海数据中心(以下简称上海数据中心),每天需要对 VSE/ESA 生产主机 和 OS/390 生产系统上的生产和系统数据进行备份,包括批处理前和批处理后的数据备份。上海数据中心每天需要从 8 个 VSE/ESA 系统和 8 个 OS/390 系统上的数百个 3390-3 型磁盘卷上备份大量 VSAM 文件(业务数据) 和备份磁盘卷的整卷数据。现在,每个VSE/ESA 生产系统的每天的数据备份量达 200 盘 3490E 磁带,其中有 60 盘左右为对磁盘卷的备份。为了不间断业务运行,缩短批处理时间,不影响生产运行。上海数据中心对数据备份操作的要求是:
确保数据安全性和完整性。
缩短备份时间,减少由于备份对业务的中断。
如果需要进行数据恢复时,恢复操作要准确、迅速,时间短。
备份和恢复操作要简捷,便于操作员的日常使用。
为了将数据备份时间缩短到最小,上海数据中心希望利用磁盘快速复制技术,或者虚 拟磁带系统来快速完成备份操作。
上海数据中心最终备份的的数据是 VSAM 文件。单个文件的数据量不大,但是文件数量众多。对这种类型数据的备份和恢复,虚拟磁带系统(VTS)技术将是最好的解决方案。上海数据中心最终利用 StorageTek 公司 的、运行在 OS/390 操作系统上的 HSC 和 VTCS 软件,配合以运行在 VSE/ESA 操 作系统上的、MT Consultant 公司的 LMS/VSE 软件来完成这些备份任务的。
二、方案介绍
由于上海数据中心需要备份的数据量庞大,将来的备份磁带数量一定很多。因此,上海数据中心应该采用自动磁带库来管理备份磁带。并采用物理磁带及 和虚拟磁带机相结合的数据备份和恢复技术,来提高数据备份的效率和存储空间的利用率。 9490 磁带机与 3490E 磁带机完全兼容,采用 IDRC 压缩和 3490E E-cart,单盘磁带的容量为 2.4 GB。由于上海数据中心的磁盘卷大多数为 3390-3 型,容量为2.89 GB,将占用 2 盘 3490E E-cart 磁带。上海中心采用 9490 磁带机 EE-tape 功能,一盘磁带的容量可以高达 4.8 GB (压缩后)。对于 OS/390 磁盘卷整卷的备份,上海数据中心采用 StorageTek 9310 自动磁带库和 9840高性能、大容量磁带机。如果配合 StorageTek exHPDM 软件,可以将数个磁盘卷同时 备份到一盘 9840 磁带上。将能充分发挥 9840 磁带机的性能和充分利用 9840 磁带的容量。
根据工商银行上海数据中心对数据备份和恢复的要求,采用 StorageTek 公司 9310 自动磁带库加 StorageTek 公司的 VSM(虚拟存储系统)的综合磁带解决方案。
VSM 主要处理大量小文件的备份和恢复,如 VSAM 文件、CICS 日志、数据库增量 备份等。而对大型文件备份和恢复,则直接使用 9310 自动磁带库中磁带驱动器,如对磁盘卷的整卷备份、数据库的全备份等操作。
本方案涉及的硬件和软件产品
1 1套 StorageTek 9310 自动磁带库系统
2. 1套 StorageTek VSM 虚拟存储系统
3. 8 套 HSC (主机软件部件) 软件
4. 1套 VTCS (虚拟磁带控制软件)
5. 8 套 LMS/VSE 软件及 8 套 5193 磁带库管理网关
6. 磁带管理软件
在 OS/390 系统上采用 CA 公司的 CA-1/TMS 磁带管理软件。
在 VSE/ESA 系统上采用 CA 公司的 DYNAM/T 磁带管理软件。
2.4. 磁带库和 VSM 系统硬件连接方案
若要实现虚拟磁带卷的迁移和回迁,VSM 至少需要 9310 磁带库中的 2 台 9840 物 理磁带驱动器与其相连接。如果迁移和回迁的工作量比较大,则需要更多的磁带机驱动器。由于 VSM 主要用于处理大量小文件的备份和恢复。而对大型文件的备份和恢复仍需要直接使用 9310 自动磁带库中 9840 磁带驱动器。因此 9310 自动磁带库必须要有 直接(或通过 ESCON 通道转接器)连接到 OS/390 主机上的磁带机驱动器。如果主机上同时提交了多个大型文件的备份或恢复作业,则需要有多个磁带机驱动器。否则,将会有作业因没有可用的磁带驱动器而等待。 如果将 9310 中的多个磁带驱动器给 VSM 专用,再将另一些磁带驱动器给主机专用,则需要更多的磁带驱动器。直连的优点是,日常操作比较简便。但是,这样做投资 比较大,而且磁带驱动器不能得到充分的利用。这样如何充分、有效地利用磁带库 中磁带驱动器,则是需要解决的问题。
上海中心每个VSE系统每天的数据备份量平均为 200 盘 3490E 磁带。不含磁盘卷的备份磁带。按照实际存储在每盘磁带上的数据量平均为 100 MB,那么 8 个 VSE 系统每天的备份数据总量为 160 GB。如果这些备份数据驻留在 VSM 的时间为 1 天,那么VSM的容量至少为 160GB。如果这些备份数据的保留时间为 30 天,则总的数据容量为 9.6 TB。 自动磁带库中将 需要至少 120 盘 9840 磁带来保留这些备份磁带。如果将每天每个 VSE 系统的备份数 据迁移到一盘 3490E 磁带中, 30 天则需要 240 盘 3490 磁带。 如果 OS/390 系统的备份的数据量与 VSE/ESA 系统的相近,则对 VSM 容量的要求将 与以上分析大体相近。
三、方案技术要点
虚拟磁带存储管理是对磁带和自动磁带库解决方案的重大革新。它是自从磁带库出现以来,第一个为批量处理而发明的新技术。虚拟磁带使现有的技术能够得到充分地利用。虚拟磁带技术将批处理中的磁带操作变得更加有效,使高密度介质、高性能磁带机和高速通道得以充分利用。
VSM 虚拟磁带系统所带来的最大利益是极大地提高了批处理的性能,这是用户可以直接感受到的虚拟磁带技术所带来的影响。其带来的间接利益还有很多,包括:充分利用现有的磁带机和磁带资源,解决磁带驱动器紧张的问题,简化了磁带管理。
对于小型批处理文件的备份,装带和卸带时间占整个磁带操作时间(占用磁带机驱动器的时间)的很大一部分。利用虚拟磁带技术,将没有装带和卸带的 时间,所以整个磁带操作时间将显著降低。 这将带来两大好处:第一,批处理作业将运行地更快,从而缩小批处理窗口;第二, 虚拟磁带机驱动器的利用率更高,减少作业等待驱动器的时间,降低了对驱动器数 量的需求。再加上虚拟磁带系统提供的虚拟磁带驱动器数量很多,使系统可以同时 处理大量批处理备份作业,减少作业的等待时间。如果需要从仍驻留在 VSM 中 虚拟磁带中恢复数据,由于该虚拟磁带卷仍然驻留在缓存中,VSM 将会直接将它恢复到主机磁盘上。整个过程不需要装带/卸带操作,缩短了恢复的时间,也缩短了批处理的时间。用户可以定义虚拟磁带卷驻留的时间。
Continue reading 【转】工商银行上海数据中心备份方案解析
用来保存计算最终结果的数据库是整个信息系统的重要组成部分,技术也相对成熟。然而,对于所有数据库而言, 除了记录正确的处理结果之外,也面临着一些挑战:如何提高处理速度,数据可用性、数据安全性和数据集可扩性。将多个数据库联在一起组成数据库集群来达到上 述目标应该说是一个很自然的想法。
集群(Cluster)技术是使用特定的连接方式,将价格相对较低的硬件设备结合起来,同时也能提供高性能相当的任务处理能力。
本文试图对当前主要的数据库集群用到的具体技术和市场上的主流产品进行分析并作点评,从而为读者提供一个数据库集群的评价参考。
下面讨论的数据库集群技术分属两类体系:基于数据库引擎的集群技术和基于数据库网关(中间件)的集群技术。
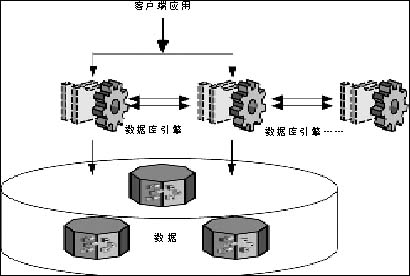
基于数据库引擎的集群技术(共享磁盘或非共享磁盘)
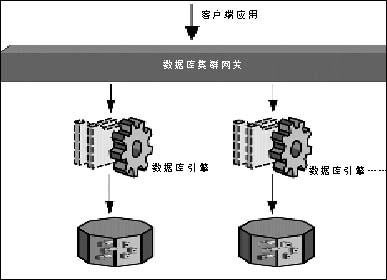
基于数据库网关(中间件)的集群技术(不共享磁盘)
关键技术
在复杂的数据库集群技术之间做比较,其实就是比较它所包含的各项子技术性能和它们之间的协调运作能力,下面的文字将介绍数据库集群最需要得到重视的核心技术,同时也关注到了一些技术细节。
提高处理速度的四种办法
提高磁盘速度:主要思想是提高磁盘的并发度。尽管实现方法各不相同,但是它们最后的目的都是提供一个逻辑数据库的存储映象。
【点评】系统为了提高磁盘访问速度,建立一个虚拟的涵盖所有数据“大”数据库,而不用去考虑数据的实际物理磁盘存放位置。
分散数据的存放:利用多个物理服务器来存放数据集的不同部分,使得不同的服务器进行并行计算成为可能。
ORACLE RAC是共享磁盘的体系结构,用户只需简单地增加一个服务器节点,RAC就能自动地将这节点加入到它的集群服务中去,RAC会自动地将数据分配到这节点 上,并且会将接下来的数据库访问自动分布到合适的物理服务器上,而不用修改应用程序;UDB是非共享磁盘的体系结构,需要手工修改数据分区,MSCS和 ASE也是同样情况。ICX是一种基于中间件的数据库集群技术,对客户端和数据库服务器都是透明的。可以用来集群几个数据库集群。
【点评】系统通过化整为零的策略,将数据表格分散到多个服务器或者每个服务器分管几个内容不同的表格,这样做的目的在于通过多服务器间并行运算以提高访问速度。
对称多处理器系统:
利用多处理机硬件技术来提高数据库的处理速度。
所有基于数据库引擎的集群都支持这个技术。
【点评】将多CPU处理器进行合理调度,来同时处理不同的访问要求,但这种技术在数据库上的应用的实际收益是很有限的。
交易处理负载均衡:在保持数据集内容同步的前提下,将只读操作分布到多个独立的服务器上运行。因为绝大 多数的数据库操作是浏览和查询,如果我们能拥有多个内容同步的数据库服务器,交易负载均衡就具有最大的潜力(可以远远大于上面叙述的最多达四个处理器的对 称多处理器系统)来提高数据库的处理速度,同时会具有非常高的数据可用性。
所有基于数据库引擎的集群系统都只支持一个逻辑数据库映象和一个逻辑或物理的备份。这个备份的主要目的 是预防数据灾难。因此,备份里的数据只能通过复制机制来更新,应用程序是不能直接更新它的。利用备份数据进行交易负载均衡只适用于一些非常有限的应用,例 如报表统计、数据挖掘以及其它非关键业务的应用。
【点评】负载平衡算是一项“老”技术了。但将性能提高到最大也是集群设计所追求的终极目标。传统意义上,利用备份数据进行交易负载均衡只适用于一些非常有限的应用。
上述所有技术在实际部署系统的时候可以混合使用以达到最佳效果。
提高可用性的四种方法
硬件级冗余:让多处理机同时执行同样的任务用以屏蔽瞬时和永久的硬件错误。有两种实现方法:构造特殊的冗余处理机和使用多个独立的数据库服务器。
基于数据库的集群系统都是用多个独立的数据库服务器来实现一个逻辑数据库,在任意瞬间,每台处理器运行的都是不同的任务。这种系统可以屏蔽单个或多个服务器的损坏,但是因为没有处理的冗余度,每次恢复的时间比较长。
【点评】传统意义上,硬件越贵,性能越高,但往往事与愿违。想通过追加和升级硬件设备来改善硬件级的冗余,要进行详细的需求分析和论证。
通讯链路级冗余:冗余的通讯链路可以屏蔽瞬时和永久的通讯链路级的错误。
基于数据库引擎的集群系统有两种结构:共享磁盘和独立磁盘。RAC, MSCS 可以认为是共享磁盘的集群系统。UDB和ASE 是独立磁盘的集群系统。共享磁盘集群系统的通讯的冗余度最小。
【点评】通讯链路级的冗余具有容错功能。
软件级冗余:由于现代操作系统和数据库引擎的高度并发性,由竞争条件、死锁、以及时间相关引发的错误占 据了非正常停机服务的绝大多数原因。采用多个冗余的运行数据库进程能屏蔽瞬时和永久的软件错误。基于数据库引擎的集群系统都用多个处理器来实现一个逻辑数 据库,它们只能提供部分软件冗余,因为每一瞬间每个处理器执行的都是不同的任务。
【点评】改善软件设计来提高冗余性能和屏蔽软件级错误是每个技术开发商的梦想。传统的集群系统只能提供部分软件冗余。
数据冗余:
1. 被动更新数据集:所有目前的数据复制技术(同步或异步),例如磁盘镜像、数据库文件复制以及数据库厂商自带的数据库备份工具都只能产生被动复制数据集。它一般只用于灾难恢复。
【点评】大多数应用都是采用被动更新数据集的方法。这种方法容灾能力差,资源占用多,已面临淘汰和革新。
2. 主动更新数据集:这种数据集需要一台或多台备份数据库服务器来管理,它可用于报表生成,数据挖掘,灾难恢复甚至低质量负载均衡。分同步和异步两种。
异步主动复制数据集:先把事务处理交给主服务器来完成,然后事务处理再被串行地交给备份服务器以执行同样操作来保证数据一致性。所有的商用数据库都支持异步主动复制技术。
同步主动复制数据集:要求所有并发事务处理在所有数据库服务器上同时完成。直接好处就是解决了队列管理 问题,同时通过负载均衡实现更高性能和可用性。RAC, UDB, MSCS 和 ASE是用完全串行化并结合两阶段提交协议来实现的,设计目标就是为了获得一份可用于快速灾难恢复的数据集。
【点评】主动更新数据集是目前比较先进的数据冗余方法。专业人员还可以进行更底层的技术细节比较。底层技术的差异直接影响着一些重要指标。
提高安全和数据集可扩性的技术
在提高数据库安全性和数据集可扩性这两方面,可以创新的空间是很小的。数据库最常见的安全办法是口令保 护,要么是分布式的,要么是集中式的。在数据库前面增加防火墙会增加额外的延迟,因此,尽管许多安全侵犯事件是来自于公司内部,但是数据库防火墙还是很少 被采用。如果数据库集群技术是基于中间件技术实现的,就有可能在不增加额外延迟的情况下,在数据经过的路径上实现防火墙功能。数据库数据集的可扩性只能通 过将数据分布到多个独立的物理服务器上来实现。
主流产品
在数据库集群产品方面,其中主要包括基于数据库引擎的集群技术的Oracle RAC、Microsoft MSCS、IBM DB2 UDB、Sybase ASE,以及基于数据库网关(中间件)的集群技术的ICX-UDS等产品。
Oracle RAC
Oracle RAC 支持 Oracle 数据库在集群上运行的所有类型的主流商业应用程序。这包括流行的封装产品,如 SAP、PeopleSoft 和 Oracle E-Business Suite 等,以及自主研发的应用程序,其中包括 OLTP 和 DSS,以及 Oracle 有效支持混合 OLTP/DSS 环境的独有能力。Oracle 是唯一提供具备这一功能的开放系统数据库的厂商。 Oracle RAC 运行于集群之上,为 Oracle 数据库提供了最高级别的可用性、可伸缩性和低成本计算能力。如果集群内的一个节点发生故障,Oracle 将可以继续在其余的节点上运行。如果需要更高的处理能力,新的节点可轻松添加至集群。为了保持低成本,即使最高端的系统也可以从采用标准化商用组件的小型 低成本集群开始逐步构建而成。
Oracle 的主要创新是一项称为高速缓存合并的技术,它最初是针对 Oracle9i 真正应用集群开发的。高速缓存合并使得集群中的节点可以通过高速集群互联高效地同步其内存高速缓存,从而最大限度地低降低磁盘 I/O。高速缓存最重要的优势在于它能够使集群中所有节点的磁盘共享对所有数据的访问。数据无需在节点间进行分区。Oracle RAC 支持企业网格。Oracle RAC 的高速缓存合并技术提供了最高等级的可用性和可伸缩性。Oracle RAC能显著降低了运营成本,增强了灵活性,从而赋予了系统更卓越的适应性、前瞻性和灵活性。动态提供节点、存储器、CPU 和内存可以在实现所需服务级别的同时,通过提高的利用率不断降低成本。
Oracle RAC采用了“sharing everything”的实现模式,通过CPU共享和存储设备共享来实现多节点之间的无缝集群,用户提交的每一项任务被自动分配给集群中的多台机器执行, 用户不必通过冗余的硬件来满足高可靠性要求。另一方面,RAC可以实现CPU的共享,即使普通服务器组成的集群也能实现过去只有大型主机才能提供的高性 能。
Microsoft MSCS
数年以来,Microsoft一直致力于对自身服务器解决方案的伸缩能力、可用性与可靠性进行扩展。最 初代号为Wolfpack且先后被称为Microsoft集群服务器与Microsoft集群服务的MSCS是Microsoft在NT集群技术领域中的 首次重拳出击,它是公认的最佳Microsoft集群解决方案。在MSCS群集中,MSCS软件最多可以同四台运行在高速网络上的物理计算机建立连接。通 常情况下,群集中的计算机能够按照“活动--活动”方式共享相同的存储子系统与功能,这意味着所有集群计算机(节点)均可主动通过共享负载的方式协同完成 工作,并在某个节点出现故障时分担它的工作。MSCS的主要用途是通过自身提供的容错能力提高应用程序可用性。容错能力是指将相关处理过程从某个节点上的 故障应用程序移植到集群中其它健康节点上的集群功能。当故障应用程序得到恢复后,集群应当能够对原先的集群节点实现“故障返回”。MSCS能够在不丢失任 何与故障应用程序相关数据的前提下对集群上所运行的应用程序进行故障恢复与故障返回管理,并且能够在故障恢复过程中维护用户及应用程序状态。这种类型的集 群功能被称作有状态集群功能。MSCS同时还允许用户在应用程序升级过程中继续进行工作。您可以采取滚动升级方式(例如每次在一个集群节点上升级应用程序 并确保其它节点上的应用程序继续处于可用状态)而不必在升级过程中停止使用应用程序。
SQL Server 2005是微软的下一代数据管理和分析解决方案,给企业级应用数据和分析程序带来更好的安全性、稳定性和可靠性,更易于创建、部署和管理。它凭借针对故障 转移群集机制的支持能力,得以增强的多实例支持能力以及分析服务对象与数据备份及恢复能力,分析服务的可用性得到了提高。它提供了诸如表分区、快照隔离、 64位支持等方面的高级可伸缩性功能,使用户能轻松构建和部署关键应用。表和索引的分区功能显著增强了对大型数据库的查询性能。
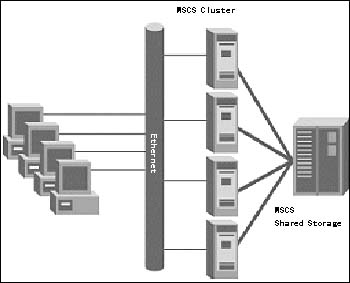
利用Windows 2000 MSCS实现的4节点集群
性能指标
这部分将介绍集群系统的细节技术指标。在做系统规划时,用户就可去掉一些应用中不太重要的指标,或赋予这些指标以不同的权重,从而进行专业的技术性能比较,选择最适合自己的数据库集群系统。
处理速度
磁盘技术:所有集群系统都能很好地应用磁盘技术,但是由于DM,FM会对磁盘系统带来传输速度的负面影响,因此这方面它们相对欠缺。
数据分割:所有基于数据库引擎的集群系统都有很好数据分割能力。
SMP:所有基于数据库引擎的集群系统的SMP性能指标都比较接近。
负载均衡:一般的数据库引擎的集群系统由于使用了备份的数据集,因此只能支持有限的负载均衡。这一指标不同产品之间有差异。
数据可用性
处理器和软件冗余:只有部分集群系统支持该功能。
通讯链路冗余:一般来说,共享磁盘的集群系统通讯链路冗余指标较低,独立磁盘的集群系统指标较高。
数据冗余:
主动异步复制:除了磁盘和文件镜像外,其他集群系统支持该功能。
主动同步复制:所有集群系统支持该功能,细节指标略有不同。
被动异步复制:所有集群系统该性能指标都比较接近。
被动同步更新:所有集群系统该性能指标都比较接近。
通过广域网的复制技术:
远程主动异步复制:所有的集群系统都支持这种复制技术,只不过对队列的管理能力有所不同。DM,FM和RAID的此性能相对较低。RAID不支持远程复制功能。
远程主动同步复制:ICX在这方面做的比较好。
远程被动异步复制:DM 和 FM支持这种类型的复制,因为DM和FM对集群是透明的,是在集群系统的下一层工作的,所有的集群系统都可以利用它们提供的功能。
远程被动同步复制:DM和FM支持这种类型的复制,因为这种复制方式只在距离很近的时候才能使用(使用双模光纤,半径五英里)。同样地,因为DM和FM对集群是透明的, 所有的集群系统都可以利用它们提供的功能, 如果部署的话,所有的集群系统都是类似的。
安全性
口令:这是所有集群系统的基本性能。分布式或集中式的口令保护基本上保证了数据的安全。
数据库防火墙:大多数数据库集群系统得数据库防火墙很少被采用,而ICX则采用在数据经过的路径上实现防火墙功能。
数据集的可扩性
数据分区:所有基于数据库引擎的集群系统都具备数据分区以保证数据集的可扩展。
数据分区的可用性:所有集群系统该性能指标比较接近。
集群管理
共享磁盘的集群系统,比如RAC、MSCS,它们的管理比较方便,其中RAC的服务更多。但是,由于此 种系统中的每一单独的服务器需要特殊处理,和独立磁盘的集群系统比较,就容易管理多了(虽然进行初始化和修改配置的时候也不那么容易),但它们都要求应用 程序对集群不透明,而且配置,修改也比较麻烦。
独立磁盘的集群系统象 UDB、ASE此性能相对稍低,因为用的都是非共享磁盘,所以管理相对繁琐。
ICX在易管理性(初始配置和将来的修改)方面和独立磁盘集群系统的性能相当,但是在对底层数据管理复杂性方面做得比较好。在对数据库引擎和数据进行底层修复的时候任务需要直接到每台数据库处理器上去做。
那些磁盘工具,即DM、FM和RAID,它们对集群是透明的。管理相对简单得多。
应用透明度
因为在错误回复和分区方面对应用程序不透明以及它们对应用程序都有些特殊的要求,基于数据库引擎的RAC、MSCS、UDB、ASE和ICX在这方面都有待提高的地方。而DM、FM和RAID它们对应用程序可以说是完全透明的。
IBM DB2 UDB
DB2 UDB大量自动或自我管理功能可使管理员能够节省更多时间来集中精力考虑驱动业务价值的问题,甚至可以消除较小的实施项目对专职管理员的需求。
UDB的优势体现在DB2的开放无界:支持Unix, Linux 以及Windows等主流操作系统;支持各种开发语言和访问接口;同时具有良好的数据安全性和稳定性。DB2 V8.2的高可用性灾备技术,可在极短时间内使关键应用得到恢复。利用DB2数据分区部件(DPF)实现横向扩展,可以支持多达1000台服务器组成的庞 大数据库群集,为构建企业级数据仓库提供坚实的技术基础。利用DB2的数据分区部件以及DB2信息集成器(DB2 II)技术,数据库操作可综合利用网格中的每台服务器的运算能力,实现真正意义上的网格运算。
UDB V8.2应用更多的创新技术,Design Advisor可以帮助 DBA 制定全面的数据库设计决策,包括集成复杂的功能划分、物化查询表,大大缩短部署时间。自动生成统计信息概要代表了来自 IBM LEO研发项目的首次部署。自主对象维护特性可自动执行基于策略的管理和维护功能,如表重构、统计信息收集和数据库备份。高可用性灾难恢复和客户机重路由 特性实现了具备随选能力的企业所需的24*7信息可用性和恢复力。此外,DB2 UDB 提供与 Java/Eclipse 和 Microsoft .NET IDE的深入集成或插件。
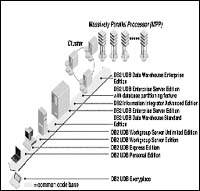
DB2 UDB结构拓扑图
SYBASE ASE
ASE性能的提高是建立在虚拟服务器架构上的,这是 Sybase 独有的体系结构。当前的ASE版本是ASE15。与操作系统和相关软件保持独立让ASE15可以更智能化地进行系统自我调优。VSA只需要很少的内存资源 和内部交换开销,所以ASE15可以管理大量的联机用户。能够使ASE提高性能并控制成本的最主要原因是它采用了专利技术的、自调整的优化器和查询引擎。 它可以智能地调整复杂的查询操作并忽略那些未包含相关信息的分区上的数据。ASE15还通过一系列用来管理和诊断数据库服务器的新特性来降低运营成本。
ASE15 拥有高可靠性和极低的运行风险。个人数据的安全性是ASE特别关注的领域,使用了一种无需修改应用的独特加密系统。当应用和安全软件进行连接时将降低实施 成本并避免产生新的安全漏洞。ASE15 还通过一种简单、直接和可编程的脚本语言来方便进行加密和解密。在解决意外停机问题时,ASE15 在其已证实的可靠性和高系统利用率的基础上,增加了许多显著的功能来增强系统的可用性和灾难恢复过程。新的存储引擎支持四种数据分区方式,在不同的物理设 备上进行不同的分区操作。能帮助数据库管理员迅速地建立冗余灾难恢复节点并在异构的数据平台上同步数据库。
ASE15系统新的查询和存储引擎被设计用于支持下一代网格计算和集群技术。它结合了充分利用数据分区 技术的查询处理机制和适用于解决集群问题的优化器技术。同时ASE15为事件驱动的企业提供了一个绝好的数据库平台。与web services 和 XML的架构将减少系统内部的相互依赖性,并为应用开发提供更大的灵活性。
ICX-UDS
ICX-UDS不受基于数据库引擎的集群技术限制,可以支持不同的数据库。
它类似通常的代理服务器。把ICX放置在关键的网络路径上,监听数据库系统流量。ICX网关将自动过滤 出无状态的查询访问,并将负载均衡到所有服务器上。在这里,网关就象一个在线“编译器”,它将所有对数据库的更新操作发送到所有数据库上执行,而将无状态 的查询操作只发送到其中某一数据库服务器上。
对于统计报表和数据挖掘类应用,可以通过复制和只读去获得更快的处理速度。还能指定更多的只读来负载均衡。ICX 网关的容错可以通过备份网关来达到。加载一个非同步的数据库可以造出不影响主服务机群的近于实时的数据源。
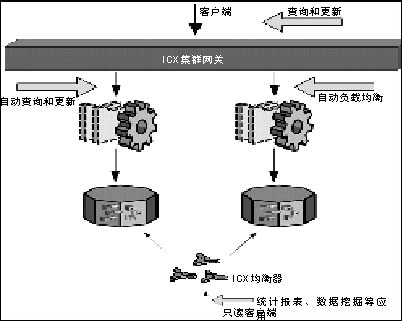
ICX 网关和负载均衡器配置示意图
应用点评
Oracle RAC和Oracle数据库提供的特定新管理性增强功能实现了企业网格。各种规模的企业都可以采用Oracle RAC来支持各类应用程序。
企业网格采用大型标准化商用组件配置:处理器、网络和存储器。利用Oracle RAC的高速缓存合并技术,Oracle数据库实现了最高可用性和可伸缩性。现在,利用Oracle数据库和Oracle RAC将大幅降低了运行成本,进一步增强了灵活性,其动态提供节点、存储器、CPU和内存的特性可以更轻松、高效地保持服务级别,而通过提高的利用率又进 一步降低了成本。企业网格是未来的数据中心,使企业具备更高的适应能力、前瞻性和敏捷性。
集群技术随着服务器硬件系统与网络操作系统的发展将会在可用性、高可靠性、系统冗余等方面逐步提高。我们汇集了市场上的主流产品,并从分析性能指标的角度出发,对产品进行了简要评价。
Sybase ASE是一个深受用户欢迎的高性能数据库,它具有一个开放的、可扩展的体系结构,易于使用的事务处理系统,以及低廉的维护成本。
ASE可支持传统的、关键任务的OLTP和DSS应用,并且满足Internet应用的发展需 要,Sybase可以很好地满足关键任务的企业业务应用的需求,提供数据库可靠性、集成性和高性能。ASE有效的多线索结构,内部并行机制和有效的查询优 化技术提供了出色性能和可伸缩性;还可提供先进的企业集成、强健和数据访问与数据移动技术,支持跨越远程Sybase和non-Sybase数据库的分布 事务和查询。ASE进一步扩展了这些功能,通过分布信息和管理商业事务,支持通过企业信息门户对商业系统进行个性化的用户访问。
MSCS对于诸如电子邮件服务器、数据库应用程序之类的应用程序,是一种良好的运行方式。
假设您决定在一个4节点MSCS群集上运行Microsoft Exchange 2000 Server。当安装MSCS软件以及适用于群集的Exchange 2000版本后,您可以对群集进行配置,以便使Exchange 2000能够在主要节点发生故障时在备份节点上进行故障恢复。当故障发生时,主服务器上肯定存在处于打开状态的用户会话,然而,MSCS能够在不丢失任何 数据的情况下快速、自动的完成故障恢复。备份节点将从故障节点上接替工作负载及相关数据,并继续为用户提供服务。
ICX的最大优点是在数据库集群技术面临的挑战上有了新的探索,此项基于中间件的数据库集群技术为获得具有高可扩性的高性能数据库提供了一条切实可行的途径,同时能灵活地适应未来的技术变化。
这种中间件复制技术可位于关键的网络路径上,监听所有进出数据库系统的流量,方便地提供防火墙和其它安 全服务,保护物理的数据库服务器。通过多个服务器的并发处理很容易地隐藏了处理的延迟。实时并行同步交易复制:一旦我们突破了实时并行同步交易复制的技术 障碍,用户就能通过由多个数据库服务器构成的集群来获得高性能,高可用性和高安全性。
DB2 UDB是一个可以随企业增长的数据库。当对网站的事务需求达到峰值时它可以迅速响应,它可以进行扩展以容纳分布在许多不同数据库中的数量不断增长的信息。
随着信息基础结构从一个处理器发展到多个处理器再到高度并行的多个群集,它也随之扩展。将分区技术和群 集技术集成到新的 DB2 UDB Enterprise Server Edition 中意味着该版本很灵活。DB2 UDB还添加了自主数据库技术,它使数据库管理员可以选择使用增强的自动化技术来配置、调优和管理他们的数据库。自主数据库管理意味着管理员可以在管理日 常任务上花费较少的时间。表的多维群集减轻了 DBA 创建索引的工作负担,同时提供了数据群集以快速查询。DB2内置的已规划的和未规划的可用性能力确保了业务应用程序在任何时候都可用。诸如索引重建、索引 创建和表装载之类的联机实用程序以及可以不停止数据库进行更改的配置参数,都意味着改进的性能和高可用性。
【相关链接】
理想的数据库集群应具备的特点
提高速度:只通过简单地增加数据库服务器就能相对提高数据库处理速度。
数据同步:在任何时刻需要有多个随时可用的实时同步数据服务。最好有多个异地的同步数据服务。
安全保证:除了密码保护之外,我们最好能控制企业内部对数据库的非法访问。
可扩展性:应保证我们能任意增大数据集而没有对可用性产生负面影响。
一般来说,有关数据库集群的技术都非常庞杂。更具挑战性的是,实际应用要求在提高速度、数据同步、安全保证、可扩展性方面的指标能同时提升,而不是单纯提升某一指标而牺牲其他指标。全面提升这些技术指标是数据库集群技术都将面临的重大课题。
【名词解释】
集群:是一组通过协同工作方式运行同一套应用程序并针对客户端及应用程序提供单一系统映像的独立计算机。集群技术的目标在于通过多层网络结构进一步提高伸缩能力、可用性与可靠性。
可伸缩性:是指一台计算机在维持可接受性能的前提下处理不断提高的工作负载的能力。
可用性:是指存在质量、备用能力、获取简便性以及可访问能力。
可靠性:是指系统牢固程度。
Continue reading 【转】主流数据库集群技术深入探讨
c 数组指针申明方法
char *p;//原始类型直接
Type (*p) [];//申明
p = (Type (*) []) long;//转换
vc6在win7上有如下毛病:
1:添加文件右键菜单不起作用,在网上搜,要装个古怪的插件
2:要将vc6快捷图标设置为管理员运行,否则有些插件运行不了
有些编译不通过时,需要更新sdk:
见下文:
http://social.msdn.microsoft.com/forums/en-US/Vsexpressvc/thread/c5c3afad-f4c6-4d27-b471-0291e099a742/
下载地址:
http://www.microsoft.com/downloads/en/details.aspx?FamilyId=0BAF2B35-C656-4969-ACE8-E4C0C0716ADB&displaylang=en
安装后在tools/options/directories里面添加包含
但是我发现include里面由mfc文件夹,lib里面却没有。导致在编译时如果查找inlcude/mfc就会说找不到连接符号,所以就去掉mfc文件夹只包含include文件夹。
对于win7系统请使用最新sdk
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=6b6c21d2-2006-4afa-9702-529fa782d63b&displaylang=en
对于web安装来说是不需要选择版本的。如果需要选择,看如下:
The Windows SDK for Windows 7 and .NET Framework 3.5 SP1: Release Candidate has been released on the Microsoft Download Center in both ISO andWeb Setup format. Web setup allows you to install a specific subset of the SDK you select without having to download the entire SDK; whereas the DVD ISO setup allows you to download the entire SDK to install later.
With this release of the SDK, there are 3 ISOs to choose from based on the CPU (x86, x64, or Itanium) platform you are installing on. Each ISO will however allow you to build applications that target all the other CPU platforms. Thus if you install the x86 ISO (which only installs on x86 platforms), you will be able to create applications targeting x86, x64, and Itanium. [任何版本都可以编译其它平台上的软件]
Which download is right for you?
· If your computer is X86, download GRC1SDK_EN_DVD.iso
· If your computer is X64, download GRC1SDKX_EN_DVD.iso
· If your computer is IA64, download GRC1SDKIAI_EN_DVD.iso (and send me mail. I’d love to hear how many folks are actually developing on IA64)
--Karin
但安装后发现这个sdk不支持vc6,那我只好试试vc2010express了,安装了后又发现express版不带mfc,+_+,没法,只有安装旗舰版了。
fatal error LNK1103: debugging information corrupt;
工程 setting/gernaral/ 去掉build debug infomation复选框
vs2010生成文件确实很大,似乎不用mfc就小些。
mfc代码可以用vs2010编码,用vc6生成。但是要改配置:
使用unicode生成方式,这样好兼容。
vc6 unicode配置:
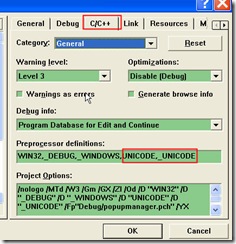
project setting/c,c++/processor definition:加入UNICODE,_UNICODE两项,去掉之前的编码项
可以使用_WIN32_WINNT=0x0500制定生成版本(未测试)
在编译时可能会出现
1:cannot open file "uafxcwd.lib"
这是由于mfc+unicode编码需要uafxcwd.lib库,vc6安装时要选择自定义安装并全选所有组件。
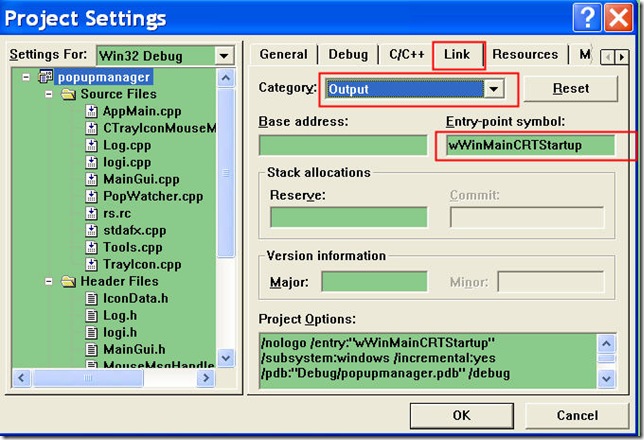
2:LNK2001: unresolved external symbol _WinMain@16
这也是mfc+unicode需要制定入口
wWinMainCRTStartup
vs2010自动生成的targetver.h里面需要包含的头文件vc6不需要
//#include <WinSDKVer.h>
//#include <SDKDDKVer.h>
VC乱码
VC 中,有时会遇到当字符串资源的属性(String table properties)设置为英文时输入的中文并不能在界面上正确显示,尽管在VC中显示正确。查看.rc文件,可以看到这些资源被放到了英文资源下。那 么如何正确显示呢?现在试着将字符串资源属性改成中文,重新build,可以发现还是不能正确显示。为什么呢?退出VC,打开rc文件,你会发现尽管这些 字符串资源放到了中文资源中,其中的中文字符都变成了乱码,再打开VC你会发现确实变成了乱码。这估计是UNICODE页面映射问题。怎么解决呢?其实很 简单,关闭VC,打开.rc文件,把没变成乱码前的那些字符串拷贝到中文资源中覆盖相应的乱码即可。
http://topic.csdn.net/t/20021212/17/1255874.html所说的方法(修改code_page)应该也可行,不过没试。
另外发现Project Settings-Resources-Language设置不起任何作用,这是比较奇怪的一件事。
Continue reading pophunter琐碎
=============================================================
标题:JAVA JNLP组件数字签名制作步骤
关键字:JNLP 数字签名 java
作者:iuprg
2009 5.15
领域:Java j2ee
web 页面 JNLP组件下载运行的数字签名
[本文禁止转载,属于个人笔记]
=============================================================
这个证书签名需要专门购买,中国的数字签名机构好象还不成熟吧?
我这里只讨论自己的证书,也就是匿名的证书。
为JAR签名需要两个工具:
1。用keytool来创建一个密匙(同时指定时效,多久会过期,默认只给 6个月)
2。用JARSigner用此密匙为JAR签名。
可以用同一个密匙来为多个JAR签名。
注意:大小写,签名一致,数字签名过期
[谢绝转载,如有刊登请email联系drs163@163.com]
为 什么JAR要被签名?当用户启动一个Java Network Launching Protocol (JNLP,Java网络加载协议)文件或使用一个applet时,这个JNLP或applet可能请求系统提供一些非一般的访问。比如“文件打开”等进 行这样的请求,就需要签名的JAR。
如果它是匿名的,系统会询问用户是否打算信任JAR的签署者。
1.首先生成签名文件,执行完成后,会在本目录内生成一个.keystore的密钥文件,2kByte大小。
yourProj是别名 keypass后面是密文密码,keystore密码是存储密码(要改变此文时需要输入确认此密码)【删掉默认的.的keystore就会创建新的】
在dos命令提示状态下输入
C:\Documents and Settings\Administrator>keytool -genkey -alias yourProj -keypas
s yourCompany:Kouling
[回车],屏幕提示:
输入keystore密码: yourCompany:yourPassword
您的名字与姓氏是什么?
[Unknown]: ChinayourCompany
您的组织单位名称是什么?
[Unknown]: ChinayourCompany.com
您的组织名称是什么?
[Unknown]: Company
您所在的城市或区域名称是什么?
[Unknown]: City
您所在的州或省份名称是什么?
[Unknown]: Province
该单位的两字母国家代码是什么
[Unknown]: CN
CN=ChinayourCompany, OU=ChinayourCompany.com, O=Company, L=City, ST=Province, C=CN 正确
吗?
[否]: Y
[谢绝转载,如有刊登请email联系drs163@163.com]
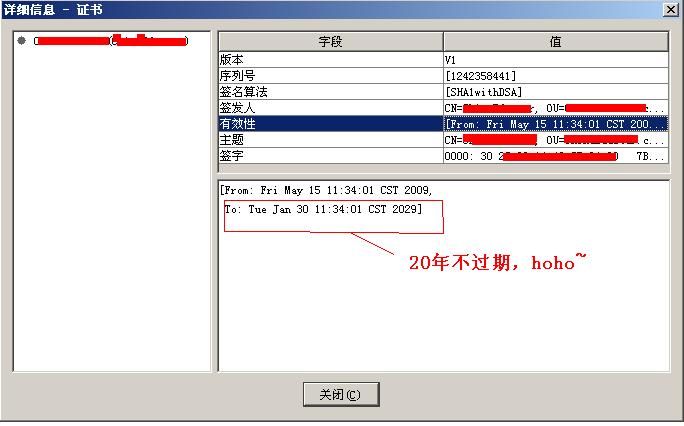
2.为此密钥加 有效期限:7200天,将近20年. [嘿嘿,足够用了吧? 再也别想6个月]
输入命令:
C:\Documents and Settings\Administrator>keytool -genkey -alias yourProj -keypass yourCompany:Kouling -selfcert -validity 7200
屏幕提示:
输入keystore密码: yourCompany:yourPassword
注意:-validity 7200 这个就是加时效的参数,7200单位是“天”。
检查密钥文件,输入命令:
C:\Documents and Settings\Administrator>keytool -list
屏幕提示:
输入keystore密码: yourCompany:yourPassword
Keystore 类型: jks
Keystore 提供者: SUN
您的 keystore 包含 1 输入
yourProj, 2009-5-15, keyEntry,
认证指纹 (MD5): D4:9D:C7:3A:91:B4:30:6A:4D:50:F1:7C:E7:F5:B9:49
说明已经生成成功完成!
3.开始为Jar包文件签名
用JARsigner工具
切换到项目jar包所在目录
D:\yourPassword's--works\yourProj\webroot\app 的目录
输入dir可以看到:
2009-04-30 18:37 <DIR> .
2009-04-30 18:37 <DIR> ..
2009-04-30 17:55 56,317 commons-logging-1.1.jar
2009-04-30 18:37 550,863 yourCompany-app-v1.0.1.jar
输入命令 :
jarsigner -verbose -certs commons-logging-1.1.jar yourProj
注:
verbose输出详细信息
certs表示验证此jar包时输出证书信息
屏幕提示:
输入密钥库的口令短语: yourCompany:yourPassword
输入 yourProj 的密钥口令: yourCompany:Kouling
正在添加: META-INF/YOURPROJ.SF
正在添加: META-INF/YOURPROJ.DSA
正在添加: org/
正在添加: org/apache/
正在添加: org/apache/commons/
正在添加: org/apache/commons/logging/
正在添加: org/apache/commons/logging/impl/
。。。
。。。
接着输入:
D:\yourProj\webroot\app>jarsigner -verbose -certs yourCompany-app-v1.0.1.jar yourProj
屏幕提示:
输入密钥库的口令短语: yourCompany:yourPassword
输入 yourProj 的密钥口令: yourCompany:Kouling
正在添加: META-INF/YOURPROJ.SF
正在添加: META-INF/YOURPROJ.DSA
正在添加: org/
注意:重要签名给yourCompany-app-v1.0.1.jar文件,但它使用了另外的几个commonsxxxx包,也要签名,否则将来使用时会提示签名不一致的错误!
4。打开jar包文件的 META-INF目录可以看到
yourProj.SF
yourProj.DSA
以及被扩充的MANIFEST.MF文件
表明已经加入了签名文件
[完毕]
[演示图片]
1。签名文件
2。实际运行时的签名提示图和时效[谢绝转载,如有刊登请email联系drs163@163.com]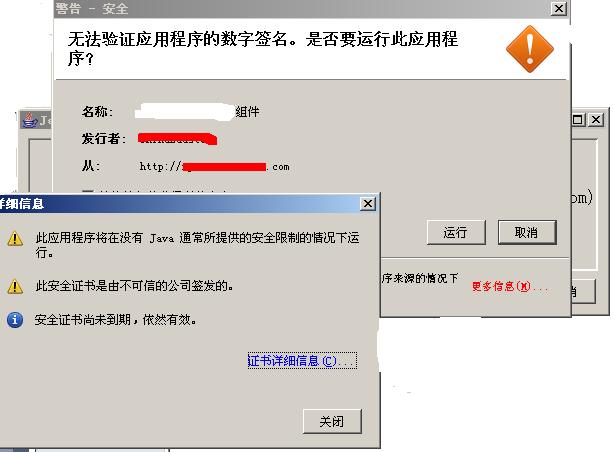
Continue reading JAVA JNLP组件数字签名制作步骤
注本文版权由文章原作者所有,如果作者认为本转载侵犯了原作者的权利,请与管理员联系 admin@ig2net.info
浅谈改进数据库应用系统性能的常用策略
陆兆洁 南宁经济信息中心
摘要:本文主要简述了改进数据库应用系统性能的常用策略,并从系统层次架构角度分别介绍了在不同领域所采用的方法,本文的侧重点放在解决问题的方法论上,期待能够达到抛砖引玉之效。
1 引言
数据交互复杂度与频度的提升,导致了数据库在运维、迁移和规模扩展进程中的性能问题。作为一项确保企业IT基础部件健康运营的关键技术,数据库性能优化的实现路径和IT系统管理架构越来越密不可分。
在数据库成熟应用的时代,数据库的性能优化已经演变为一项相当严密的系统工程。作为企业IT基础设施的核心部件之一,数据库并不是孤立的系统,它与网络、操作系统、存储等硬件系统紧密相连,这种与其他IT部件的多重连接特性决定了数据库性能优化是一门综合技术。
2 数据库应用系统性能的优化
完整的数据库性能优化周期可以分为两个阶段,一是设计与开发阶段,主要负责对数据库逻辑和物理结构的优化设计,使其在满足具体业务需求的前提下,系统性能达到最佳,同时系统开销最小;二是数据库的运行阶段,其优化手段以数据库级、操作系统级、网络级为主。
2.1 数据库的设计和开发阶段
数据库性能下降很大一部分的风险是能够在数据库的设计阶段予以规避的。因此,设计优化也就成为了数据库性能优化技术的源头和方向。由于数据库逻辑结构的不合理、索引设计不合理,开发阶段的技术冲突无法调适,多种因素的累积作用导致了许多数据库系统上线后不久即出现性能故障的案例不在少数。比较生命周期的调优成本与调优收益曲线,性能调优的成本随软件生命周期进程而增加,但调优收益却随软件生命周期进程而减少。在该阶段的具体实现上一般表现为某一类数据库,其性能的改进主要体现在逻辑设计和物理设计上。
2.1.1 数据库的逻辑设计
数据库的逻辑结构是由一些数据库对象组成,如数据库表空间、表、索引、段、视图、存储过程、触发器等。数据库的逻辑存储结构(表空间等)决定了数据库的物理空间是如何被使用的,数据库对象如表、索引等分布在各个表空间中。
数据库的逻辑配置对数据库性能有很大的影响,因此首先要对数据库中的逻辑对象根据他们的使用方式和物理结构对数据库的影响来进行分类,这种分类包括将系统数据和用户数据分开、一般数据和索引数据分开、低活动表和高活动表分开等等。
数据库逻辑设计的结果应当符合下面的准则摘要:
(1)把以同样方式使用的段类型存储在一起;
(2)按照标准使用来设计系统;
(3)存在用于例外的分离区域;
(4)最小化表空间冲突;
(5)将数据字典分离。
逻辑结构优化用通俗的话来说就是通过增加、减少或调整逻辑结构来提高应用的效率,可以从以下几个方面来精练数据库的逻辑设计:
1、基本表扩展
数据库性能包括存储空间需求量的大小和查询响应时间的长短两个方面。为了优化数据库性能,需要对数据库中的表进行规范化。一般来说,逻辑数据库设计满足第三范式的表结构轻易维护且基本满足实际应用的要求。所以,实际应用中一般都按照第三范式的标准进行规范化,从而保证了数据库的一致性和完整性,设计人员往往会设计过多的表间关联,以尽可能地降低数据冗余。但在实际应用中这种做法有时不利于系统运行性能的优化:如过程从多表获取数据时引发大量的连接操作,在需要部分数据时要扫描整个表等,这都消耗了磁盘的I/O和CPU时间。
为解决这一问题,在设计表时应同时考虑对某些表进行反规范化,方法有以下几种:一是分割表。分割表可分为水平分割表和垂直分割表两种:水平分割是按照行将一个表分割为多个表,这可以提高每个表的查询速度,但查询、更新时要选择不同的表,统计时要汇总多个表,因此应用程序会更复杂。垂直分割是对于一个列很多的表,若某些列的访问频率远远高于其它列,就可以将主键和这些列作为一个表,将主键和其它列作为另外一个表。通过减少列的宽度,增加了每个数据页的行数,一次I/O就可以扫描更多的行,从而提高了访问每一个表的速度。但是由于造成了多表连接,所以应该在同时查询或更新不同分割表中的列的情况比较少的情况下使用。二是保留冗余列。当两个或多个表在查询中经常需要连接时,可以在其中一个表上增加若干冗余的列,以避免表之间的连接过于频繁,一般在冗余列的数据不经常变动的情况下使用。三是增加派生列。派生列是由表中的其它多个列的计算所得,增加派生列可以减少统计运算,在数据汇总时可以大大缩短运算时间。
因此,在数据库的设计中,数据应当按两种类别进行组织:频繁访问的数据和频繁修改的数据。对于频繁访问但是不频繁修改的数据,内部设计应当物理不规范化。对于频繁修改但并不频繁访问的数据,内部设计应当物理规范化。有时还需将规范化的表作为逻辑数据库设计的基础,然后再根据整个应用系统的需要,物理地非规范化数据。规范与反规范都是建立在实际的操作基础之上的约束,脱离了实际两者都没有意义。只有把两者合理地结合在一起,才能相互补充,发挥各自的优点。
2、索引的建立
创建索引是提高检索效率最有效的方法之一,索引把表中的逻辑值映射到安全的RowID,能快速定位数据的物理地址,可以大大加快数据库的查询速度,一个建有合理索引的数据库应用系统可能比一个没有建立索引的数据库应用系统效率高几十倍,但并不是索引越多越好,在那些经常需要修改的数据列上建立索引,将导致索引B*树的不断重组,造成系统性能的下降和存储空间的浪费。对于一个大型表建立的索引,有时并不能改善数据查询速度,反而会影响整个数据库的性能。这主要是和SGA的数据治理方式有关,Oracle在进行数据块高速缓存治理时,索引数据比普通数据具有更高的驻留权限,在进行空间竞争时,Oracle会先移出普通数据,对建有索引的大型表进行数据查询时,索引数据可能会用完所有的数据块缓存空间,Oracle不得不频繁地进行磁盘读写来获取数据,所以,在对一个大型表进行分区之后,可以根据相应的分区建立分区索引。
2.1.2 数据库的物理设计
数据库物理设计需要对时间效率、空间效率、维护代价和各种用户要求进行权衡,结果会产生多种方案,必须对此进行细致评价,选择一个较优的方案作为数据库的物理结构。
数据库的数据最终是存储在物理磁盘上的,对数据进行访问就是对这些物理磁盘进行读写,因此对于这些物理存储的优化是系统优化的一个重要部分。对于物理存储结构优化,主要是合理地分配逻辑结构的物理存储地址,这样虽不能减少对物理存储的读写次数,但却可以使这些读写尽量并行,减少磁盘读写竞争,从而提高效率,也可以通过对物理存储进行精密的计算减少不必要的物理存储结构扩充,从而提高系统利用率。
为了避免数据库文件之间的竞争,在物理设计时,文件应该被放到不同的I/O通道,跨越驱动器的文件分离,避免磁盘争用成为一个“瓶颈”。主要应该注意以下几点技巧:把关键数据文件分布在各个可用的磁盘上,这些文件包括表空间、回滚段或UNDO段、联机重做日志文件、操作系统盘、经常访问的表的数据文件以及经常访问的索引的数据文件;把数据和索引文件分开放置;对于经常连接的表,把它们的数据和索引表空间分开,这样每个表上的信息就不会放在相同的磁盘上;把控制文件的多个备份存储到不同的磁盘和控制器上,以最终实现操作并行化。
同时,还应将表数据和索引数据分开表空间存储,分别使用独立的表空间。因为假如将表数据和索引数据放在一起,表数据的I/O操作和索引的I/O操作将产生影响系统性能的I/O竞争,降低系统的响应效率。将表数据和索引数据存放在不同的表空间中,并在物理层面将这两个表空间的数据文件放在不同的物理磁盘上,就可以避免这种竞争了。
2.2 数据库的运行阶段
数据库的运行管理主要通过对数据库运行环境进行调整来达到改进性能的目的。在决定进行系统性能调优级时,首先应制定一个完善的调优级方案,先监控系统并分析问题所在,然后根据分析结果每次调整一个参数,再进一步监控系统查看系统性能有无变化,然后做进一步调节。其中有一个重要的原则:每次最好只调节一个参数。
2.2.1 数据库级参数性能调优
一般来说,数据库管理系统(DBMS)中与性能相关的参数都与对系统物理内存的设置有关,换言之,数据库级参数性能优化即是DBMS对系统内存的配置。通常,只要将这些主要参数设置好就会显著改善数据库系统的性能,因此,配置好数据库系统参数,是优化数据库系统运行环境的关键。
数据库管理系统对系统内存的配置应尽可能实现如下目标:
一是减少分页:当系统执行分页时,会将当前没有使用的信息从内存移到硬盘上。这样就可以为当前需要内存的程序分配内存。如果频繁地发生分页,系统性能就会严重降低,从而导致很多程序的执行时间变长。
二是减少内存交换:当系统执行内存交换时,会将活动进程临时地从内存移到硬盘上,这样另一个活动进程就可以得到所需要的内存。内存交换基于系统循环时间。如果内存交换过于频繁,就会产生大量的磁盘I/O,应用的性能可能会急剧恶化。
三是扩大高速数据存储内存缓冲区容量:用户的进程对这个内存区发送事务,并且以这里作为高速缓存读取命中的数据,以实现加速的目的。主要包括数据块缓冲、数据字典缓冲、恢复回滚日志缓冲以及SQL共享池等这几个部分摘要。对这些内存缓冲区的合理设置,可以大大加快数据查询速度,提高内存区的命中率。
2.2.2 操作系统级参数性能调优
(1)进行定期的磁盘检查和磁盘空间清理,当系统运行一段时间后,会出现一定的文件错误和磁盘碎片,此时就需要进行磁盘整理。
(2)自动关闭停止响应的程序,无须进行手工干预。
(3)调整应用程序优先级,让常用程序拥有较高的优先权,自然运行速度就会快些。
(4)配置操作系统核心使用更少的内存。
(5)配置操作系统与DBMS相关的内核参数以便将更多的系统内存留给DBMS使用。
2.2.3 网络级参数性能调优
网络带宽会影响系统性能,减少网络负载,可以改善系统的性能。
负载均衡将是大型应用高负荷访问和大量并发请求采用的终极解决办法,它提供了一种有效的方法来扩充服务器带宽,增加吞吐量,提高网络的灵活性和可用性。
对负载均衡的应用,可以从网络的不同层次入手,具体情况要看瓶颈所在,不外乎从传输链路聚合、采用更高层网络交换技术和设置服务器集群策略三个角度实现,一个典型的使用负载均衡的策略就是,在软件或者硬件四层交换的基础上搭建集群,这样的架构成本低、性能高还有很强的扩张性,随时往架构里面增减节点都非常容易。
3 结束语
在应用丛生、高度分布式的环境中,要总结出一套“放之四海皆准”的数据库性能优化方法论并不容易。但结合企业自身特色的性能优化流程却是有据可循的。同时,数据库性能优化方法还具有浓重的行业色彩。
在对数据库应用系统改进所采取的策略中,前面提到的每个方法可能都会被用到,本文介绍得比较粗浅,具体实现过程中很多细节还需要慢慢熟悉和体会,有时一个很小的参数设置,对于系统性能的影响就会很大,在此仅概而述之,以期达到抛砖引玉之效
Continue reading 【转】浅谈改进数据库应用系统性能的常用策略
Web前端的起源
Web应用诞生:随着GMail、 Google Map等优秀Web应用出现,Ajax在2004年之后一度成为热门话题。经过几年的发展,一批以Prototype、Dojo、Ext为首的 Ajax+UI的浏览器兼容框架不断出现。UI和Web中间新增了一层以Javascript为核心,专门处理数据传输、Web交互等内容的开发 层,Web前端。Web前端伴随Web应用而诞生,并逐步走来。
Web宿主之争:随着RESTful Web Service潮流的发展,后台服务也迅速实现了数据云端化,接口API化。但受IE垄断和发展缓慢的影响,Web前端始终走不出浏览器能力不足和兼容性 问题突出的困局。开发维护浏览器插件、Flash控件等更是无奈的选择。Web前端往往因为需要兼容IE6、IE7、FF、有无插件、有无Flash等情 况付出巨大开发代价。2006年,John Resig的jQuery框架从某个意义上解决了这个问题。我认为最大的突破在于让老旧浏览器适配新的Web标准,满足了开发者开发高效而兼容老旧浏览器 的需要。
Web标准化之路:Google 在 2008年推出了Webkit核心的浏览器Chrome(后来也发布了ChromeOS)。随着FireFox,Chrome,Safari,Opera 等浏览器开始对HTML5和CSS3的深入支持以及性能的不断优化,IE市场占有率的持续下滑。Web标准化终于等到了一个发展机遇。2010 年,HTML5和CSS3被Webkit核心的Chrome、Safari绚丽地实现后,IE9也表示全面支持HTML5后。Web标准进入一个高速发展 阶段。随后,浏览器GPU加速也浏览器厂商们所接受。在Web标准化、离线化、硬件化的浪潮中,Web应用逐渐具备了替代桌面应用条件和能力。Web前端 开发也在逐步取代桌面应用客户端开发。
移动Web应用背景
非智能机时代:Java和WAP是取代短信SP后的第一种移动互联网实现方式。这个年代虽然荒蛮,但很纯真。
前智能机时代:HP 把一台WinPPC 的PAD增加电话功能,做成第一台智能手机时。Windows Mobile和S60是这个时代的主角。基于手机系统的客户端应用就是移动互联网应用的最好形式。但是随着系统版本的不断升级,设备的差异不断增大。手机 客户端应用开发同样面临着与Web前端开发一样的兼容性开发效率和维护成本问题。
后智能机时代:随着iPhone和 Android(HTC、摩托罗拉、三星等)手机等的热卖,两个电子市场生态链逐步形成。再加上最近诺基亚和微软和合作,电子市场生态链之争拉开帷幕。客 户端应用成为了电子市场生态链的主角。不过随着三方系统的竞争升级,也伴随浏览器的不断优化。先不论WP7,iPhone和Android阵营的浏览器都 是webkit核心的,差异只在于硬件加速能力和设备资源的差异。这恰好也是移动Web应用的发展机遇。
移动Web应用开发
需求:
互联网是个产品线丰富的产业,但不可能对所有产品都投入巨大开发成本。WAP能满足基本使用需求,而客户端应用满足主线产品的高端需求。还有一大片中高端需求无法很好满足。遗憾的是,限于开发成本,用户没有与其高端设备相匹配的非主线产品客户端可用。
开发成本无法避免,但可以择优。我们可以通过移动Web应用的方式来次优替代非主线产品客户端。这也是廉价的移动应用实现方式。
现状:
目前iOS和Android系统的浏览器都是webkit核心的,我们可以开发移动Web应用来满足这块需求。iOS支持硬件加 速,Android系统也能满足基本Webkit的API功能,适宜通过区分iOS来提供差异化服务。iOS的Mobile Safari有足够能力提供webkitTransForm(图形变换,3D变换支持硬件加速)、webkitTransition(CSS3动画)、 SQLite、LocalStorage(离线存储)、 WebSocket(iOS 4.2+)服务。至于Android,因为需要兼容参差的低端设备,还是不建议使用复杂图形变换和CSS3动画,其它能力可以通过判断能否支持来选择使 用。另外多点触摸、重力感应、地理位置还是根据能否支持和需要来使用,主要用于优化用户体验,不影响基本交互方式。
未来:
移动Web应用的起点比PC Web应用的高,但适用范围较窄。但移动Web应用将成为Web应用的一种延伸,从开发角度来看,应该是殊途同归的。
小结
Javascript的角色从诞生起的页面粘合剂转变成今天的Web应用开发语言,一路走来经过很多波折。有人喜欢他,有人讨厌他,在崇拜和谩 骂中成长过来。将来的路还很长,但迷雾已散去,前途是光明的。当中有无数人的付出汗水,也成就了少数应用的辉煌。不过他仍然是一个工具,为开发者服务,需 要人们一起来优化他,使用他。
Continue reading 【转】Web前端在移动
见维基百科
http://en.wikipedia.org/wiki/Software_architecture
2005 年 1 月 01 日
本文基于多个并 发视图的使用情况来说明描述软件密集型系统架构的模型。使用多重视图允许独立地处理各"风险承担人":最终用户、开发人员、系统工程师、项目经理等所关注 的问题,并且能够独立地处理功能性和非功能性需求。本文分别对五种视图进行了描述,并同时给出了捕获每种视图的表示方法。这些视图使用以架构为中心的、场 景驱动以及迭代开发过程来进行设计。
引言
我们已经看到在许多文章和书籍中,作者欲使用单张视图来捕捉所有的系统架构要点。通过仔细地观察这些图例中的方框和箭头, 不难发现作者努力地在单一视图中表达超过其表达限度的蓝图。方框是代表运行的程序吗?或者是代表源代码的程序块吗?或是物理计算机吗?或仅仅是逻辑功能的 分组吗?箭头是表示编译时的依赖关系吗?或者是控制流吗?或是数据流吗?通常它代表了许多事物。是否架构只需要单个的架构样式?有时软件架构的缺陷源于过 早地划分软件或过分的强调软件开发的单个方面:数据工程、运行效率、开发策略和团队组织等。有时架构并不能解决所有"客户"(或者说"风险承担 人",USC 的命名)所关注的问题。许多作者都提及了这个问题:Garlan & Shaw 1、CMU 的 Abowd & Allen、SEI 的 Clements。作为补充,我们建议使用多个并发的视图来组织软件架构的描述,每个视图仅用来描述一个特定的所关注的方面的集合。



回页首
架构模型
软件架构用来处理软件高层次结构的设计和实施。它以精心选择的形式将若干结构元素进行装配,从而满足系统主要功能和性能需 求,并满足其他非功能性需求,如可靠性、可伸缩性、可移植性和可用性。Perry 和 Wolfe 使用一个精确的公式来表达,该公式由 Boehm 做了进一步修改:
软件架构 = {元素,形式,关系/约束}
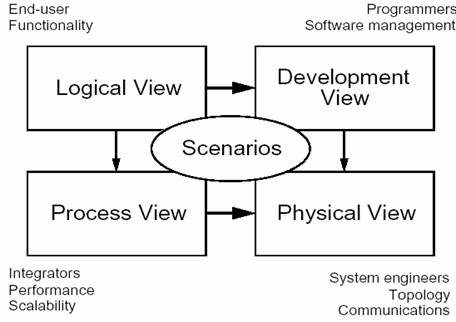
软件架构涉及到抽象、分解和组合、风格和美学。我们用由多个视图或视角组成的模型来描述它。为了最终处理大型的、富有挑战 性的架构,该模型包含五个主要的视图(请对照图 1):
- 逻辑视图(Logical View),设计的对象模型(使用面向对象的设计方法时)。
- 过程视图(Process View),捕捉设计的并发和同步特征。
- 物理视图(Physical View),描述了软件到硬件的映射,反映了分布式特性。
- 开发视图(Development View),描述了在开发环境中软件的静态组织结构。
架构的描述,即所做的各种决定,可以围绕着这四个视图来组织,然后由一些用例 (use cases)或场景(scenarios)来说明,从而形成了第五个视图。正如将看到的,实际上软件架构部分从这些场景演进而来,将在下文中讨论。
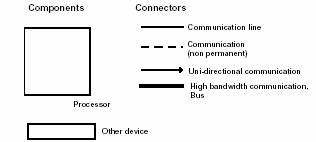
图 1 - "4+1"视图模型
我们在每个视图上均独立地应用 Perry & Wolf 的公式,即定义一个所使用的元素集合(组件、容器、连接符),捕获工作形式和模式,并且捕获关系及约束,将架构与某些需求连接起来。每种视图使用自身所特 有的表示法-蓝图(blueprint)来描述,并且架构师可以对每种视图选用特定的架构风格(architectural style),从而允许系统中多种风格并存。
我们将轮流的观察这五种视图,展现各个视图的目标:即视图的所关注的问题,相应的架构蓝图的标记方式,描述和管理蓝图的工 具。并以非常简单的形式从 PABX 的设计中,从我们在Alcatel 商业系统(Alcatel Business System)上所做的工作中,以及从航空运输控制系统(Air Traffic Control system)中引出一些例子―旨在描述一下视图的特定及其标记的方式,而不是定义这些系统的架构。
"4+1"视图模型具有相当的"普遍性",因此可以使用其他的标注方法和工具,也可以采用其他的设计方法,特别是对于逻辑 和过程的分解。但文中指出的这些方法都已经成功的在实践中运用过。
逻辑结构
面向对象的分解
逻辑架构主要支持功能性需求――即在为用户提供服务方面系统所应该提供的功能。系统分解为一系列的关键抽象,(大多数)来 自于问题域,表现为对象或对象类的形式。它们采用抽象、封装和继承的原理。分解并不仅仅是为了功能分析,而且用来识别遍布系统各个部分的通用机制和设计元 素。我们使用 Rational/Booch 方法来表示逻辑架构,借助于类图和类模板的手段 4。 类图用来显示一个类的集合和它们的逻辑关系:关联、使用、组合、继承等等。相似的类可以划分成类集合。类模板关注于单个类,它们强调主要的类操作,并且识 别关键的对象特征。如果需要定义对象的内部行为,则使用状态转换图或状态图来完成。公共机制或服务可以在类功能 (class utilities)中定义。对于数据驱动程度高的应用程序,可以使用其他形式的逻辑视图,例如 E-R 图,来代替面向对象的方法(OO approach)。
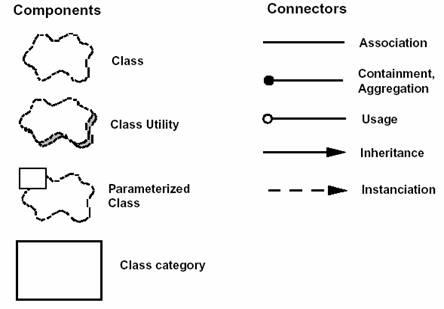
逻辑视图的表示法
逻辑视图的标记方法来自 Booch 标记法4。当仅考虑具有架构意义的条目时,这种表示法相当简单。特别是在这种设计级别上,大量的修饰作用不大。我们使用 Rational Rose? 来支持逻辑架构的设计。
图 2 - 逻辑蓝图的表示法
逻辑视图的风格
逻辑视图的风格采用面向对象的风格,其主要的设计准则是试图在整个系统中保持单一的、一致的对象模型,避免就每个场合或过 程产生草率的类和机制的技术说明。
逻辑结构蓝图的样例
图 3 显示了 Télic PABX 架构中主要的类。
图 3 - a. Télic PABX 的逻辑蓝图 b.空中交通系统的蓝图
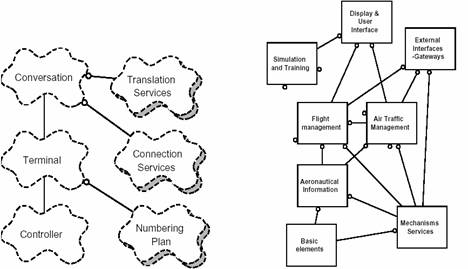
PABX 建立终端间的通信连接。终端可以是电话设备、中继线(例如,连接到中央办公室)、连接线(PABX 专线到 PABX 线)、电话专线、数据线、ISDN 等等。不同的线路由不同的接口卡提供支持。线路 controller 对象的职责是在接口卡上对所有的信号进行解码和注入,在特定于接口卡的信号与一致性的小型事件集合之间进行相互转换:开始、停止、数字化等。 controller 对象同时承载所有的实时约束。该类派生出许多子类以满足不同的接口类型。terminal 对象的责任是维持终端的状态,代表线路协调各项服务。例如,它使用 numbering plan 服务来解释拨号。conversation 代表了会话中的一系列终端 。conversation 使用了Translation Service(目录、逻辑物理映射、路由),以及建立终端之间语音路径的Connection Service 。
对于一个包含了大量的具有架构重要意义的类的、更大的系统来说,图 3 b 描述了空中交通管理系统的顶层类图,包含 8 个类的种类(例如,类的分组)。
进程架构
过程分解
进程架构考虑一些非功能性的需求,如性能和可用性。它解决并发性、分布性、系统完整性、容错性的问题,以及逻辑视图的主要 抽象如何与进程结构相配合在一起-即在哪个控制线程上,对象的操作被实际执行。
进程架构可以在几种层次的抽象上进行描述,每个层次针对不同的问题。在最高的层次上,进程架构可以视为一组独立执行的通信 程序(叫作"processes")的逻辑网络,它们分布在整个一组硬件资源上,这些资源通过 LAN 或者 WAN 连接起来。多个逻辑网络可能同时并存,共享相同的物理资源。例如,独立的逻辑网络可能用于支持离线系统与在线系统的分离,或者支持软件的模拟版本和测试版 本的共存。
进程是构成可执行单元任务的分组。进程代表了可以进行策略控制过程架构的层次(即:开始、恢复、重新配置及关闭)。另外, 进程可以就处理负载的分布式增强或可用性的提高而不断地被重复。
软件被划分为一系列单独的任务。任务是独立的控制线程,可以在处理节点上单独地被调度。
接着,我们可以区别主要任务、次要任务。主要任务是可以唯一处理的架构元素;次要任务是由于实施原因而引入的局部附加任务 (周期性活动、缓冲、暂停等等)。它们可以作为 Ada Task 或轻量线程来实施。 主要任务的通讯途径是良好定义的交互任务通信机制:基于消息的同步或异步通信服务、远程过程调用、事件广播等。次要任务则以会见或共享内存来通信。在同一 过程或处理节点上,主要任务不应对它们的分配做出任何假定。
消息流、过程负载可以基于过程蓝图来进行评估,同样可以使用哑负载来实现"中空"的进程架构,并测量在目标系统上的性能。 正如 Filarey et al. 在他的 Eurocontrol 实验中描述的那样。
进程视图的表示法
我们所使用的进程视图的表示方法是从Booch最初为 Ada 任务推荐的表示方法扩展而来。同样,用来所使用的表示法关注在架构上具有重要意义的元素。(图 4)
图 4 - 过程蓝图表示法
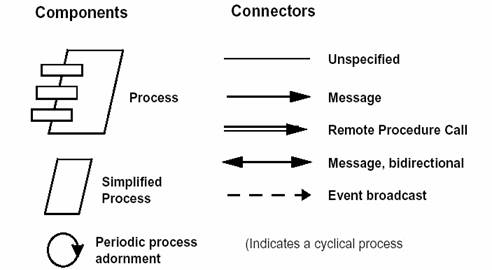
我们曾使用来自 TRW 的 Universal Network Architechure Services(UNAS0) 产品来构建并实施过程和任务集合(包扩它们的冗余),使它们融入过程的网络中。UNAS 包含 Software Architect Lifecycle Environment(SALE)工具,它支持上述表示方法。SALE 允许以图形的形式来描述进程架构,包括对可能的交互任务通信路径的规格说明,正是从这些路径中自动生成对应的 Ada 或 C++ 源代码。使用该方法来指定和实施进程架构的优点是易于进行修改而不会对应用软件造成太多的影响。
进程视图的风格
许多风格可以适用于进程视图。例如采用 Garlan 和 Shaw 的分类法1,我们可以得到管道和过滤器(Pipes and filters),或客户端/服务器,以及各种多个客户端/单个服务器和多个客户端/多个服务器的变体。对于更加复杂的系统,可以采用类似于 K.Birman 所描述的ISIS系统中进程组方法以及其它的标注方法和工具。
进程蓝图的例子
图 5 - Télic PABX 的过程蓝图(部分)
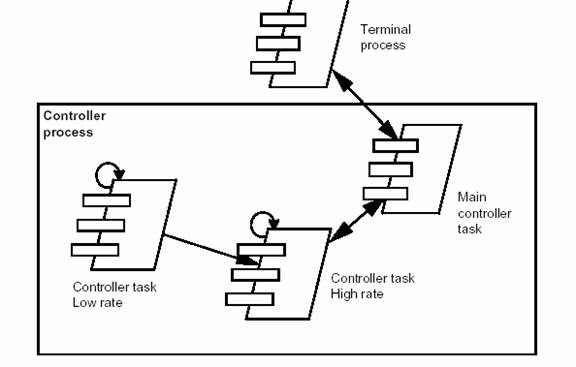
所有的终端由单个的 Termal process 处理,其中 Termal process 由输入队列中的消息进行驱动。Controller 对象在组成控制过程三个任务之中的一项任务上执行:Low cycle rate task 扫描所有的非活动终端(200 ms),将 High cycle rate task(10 ms)扫描清单中的终端激活,其中 High cycle rate task 检测任何重要的状态变化,将它们传递给 Main controller task,由它来对状态的变更进行解释,并通过向对应的终端发送消息来通信。这里 Controller 过程中的通信通过共享内存来实现。
开发架构
子系统分解
开发架构关注软件开发环境下实际模块的组织。软件打包成小的程序块(程序库或子系统),它们可以由一位或几位开发人员来开 发。子系统可以组织成分层结构,每个层为上一层提供良好定义的接口。
系统的开发架构用模块和子系统图来表达,显示了"输出"和"输入"关系。完整的开发架构只有当所有软件元素被识别后才能加 以描述。但是,可以列出控制开发架构的规则:分块、分组和可见性。
大部分情况下,开发架构考虑的内部需求与以下几项因素有关:开发难度、软件管理、重用性和通用性及由工具集、编程语言所带 来的限制。开发架构视图是各种活动的基础,如:需求分配、团队工作的分配(或团队机构)、成本评估和计划、项目进度的监控、软件重用性、移植性和安全性。 它是建立产品线的基础。
开发蓝图的表示方法
同样,使用 Booch 方法的变形,仅考虑具有架构意义的项。
图 5 - 开发蓝图表示方法
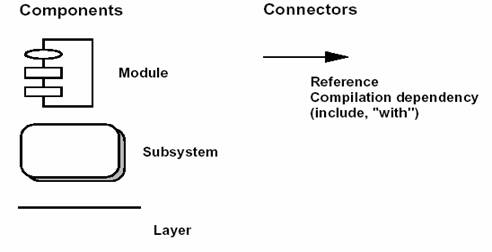
来自 Rational 的 Apex 开发环境支持开发架构的定义和实现、和前文描述的分层策略,以及设计规则的实施。Rational Rose 可以在模块和子系统层次上绘制开发蓝图,并支持开发源代码(Ada、C++)进程的正向和反向工程。
开发视图的风格
我们推荐使用分层(layered)的风格,定义 4 到 6 个子系统层。每层均具有良好定义的职责。设计规则是某层子系统依赖同一层或低一层的子系统,从而最大程度地减少了具有复杂模块依赖关系的网络的开发量,得 到层次式的简单策略。
图 6 - Hughes 空中交通系统(HATS)的 5 个层
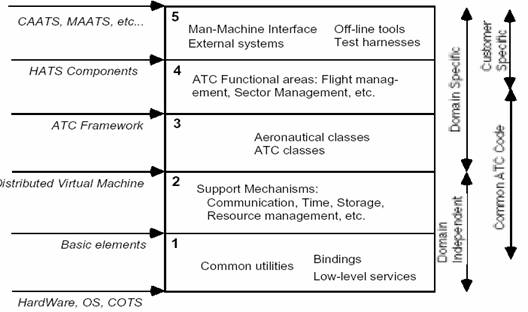
开发架构的例子
图 6 代表了加拿大的 Hughes Aircraft 开发的空中交通控制系统(Air Traffic Control system)产品线的 5 个分层开发组织结构。这是和图 3 b 描述的逻辑架构相对应的开发架构。
第一层 和第二层组成了独立于域的覆盖整个产品线的分布式基础设施,并保护其免受不同硬件平台、操作系统或市售产品(如数据库管理系统)的影响。第三层为该基础设 施增加了 ATC 框架,形成一个特定领域的软件架构(domain-specific software architecture)。使用该框架,可以在第四层上构建一个功能选择板。层次 5 则非常依赖于客户和产品,包含了大多数用户接口和外部系统接口。72 个子系统分布于 5 个层次上,每层包含了 10 至 50 个模块,并可以在其他蓝图上表示。
物理架构
软件至硬件的映射
物理架构主要关注系统非功能性的需求,如可用性、可靠性(容错性),性能(吞吐量)和可伸缩性。软件在计算机网络或处理节 点上运行,被识别的各种元素(网络、过程、任务和对象),需要被映射至不同的节点;我们希望使用不同的物理配置:一些用于开发和测试,另外一些则用于不同 地点和不同客户的部署。因此软件至节点的映射需要高度的灵活性及对源代码产生最小的影响。
物理蓝图的表示法
大型系统中的物理蓝图会变得非常混乱,所以它们可以采用多种形式,有或者没有来自进程视图的映射均可。
图 7 - 物理蓝图的表示法
TRW 的 UNAS 提供了数据驱动方法将过程架构映射至物理架构,该方法允许大量的映射 的变更而无需修改源代码。
物理蓝图的示例
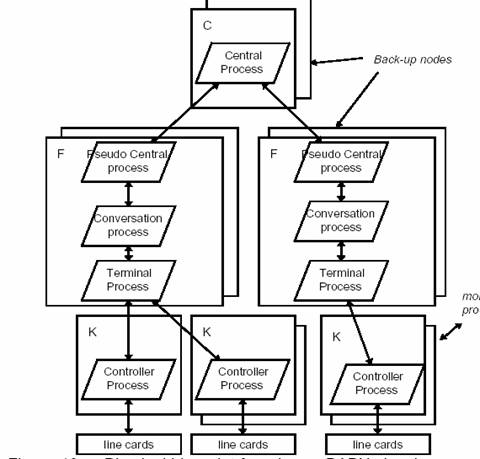
图 8 - PABX 的物理蓝图
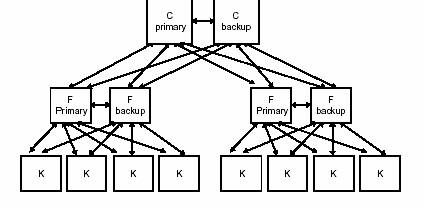
图 8 显示了大型 PABX 可能的硬件配置,而图 9 和图 10 显示了两种不同物理架构上的进程映射,分别对应一个小型和一个大型 PABX。C、F 和 K 是三种不同容量的计算机,支持三种不同的运行要求。
图 9 - 带有过程分配的小型 PABX 物理架构
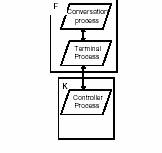
图10-显示了过程分配的大型PABX物理蓝图
场景
综合所有的视图
四种视图的元素通过数量比较少的一组重要场景(更常见的是用例)进行无缝协同工作,我们为场景描述相应的脚本(对象之间和 过程之间的交互序列)。正如 Rubin 和 Goldberg 所描述的那样6。
在某种意义上场景是最重要的需求抽象,它们的设计使用对象场景图和对象交互图来表示4。
该视图是其他视图的冗余(因此"+1"),但它起到了两个作用:
- 作为一项驱动因素来发现架构设计过程中的架构元素,这一点将在下文中讨论。
- 作为架构设计结束后的一项验证和说明功能,既以视图的角度来说明又作为架构原型测试的出发点。
场景的表示法
场景表示法与组件逻辑视图非常相似(请对照图 2),但它使用过程视图的连接符来表示对象之间的交互(请对照图 4),注意对象实例使用实线来表达。至于逻辑蓝图,我们使用 Rational Rose 来捕获并管理对象场景。
场景的例子
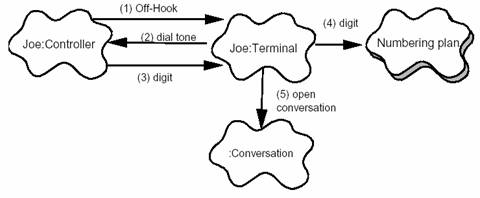
图 11 显示了小型 PABX 的场景片段。相应的脚本是:
1. Joe的电话控制器检测和校验摘机状态的变换,并发送消息唤醒相应的终端对象。
2. 终端分配一些资源,并要求控制器发出拨号音。
3. 控制器接受拨号并传递给终端。
4. 终端使用拨号方案来分析数字流。
5. 有效的数字序列被键入,终端开始会话。
图 11 - 本地呼叫的初期场景――阶段选择
视图之间的对应性
各种视图并不是完全是正交的或独立的。视图的元素根据某种设计规则和启发式方法与其他视图中的元素相关联。
从逻辑视图到过程视图
我们发现逻辑视架构有几项重要特性:
- 自主性:对象是主动的、被动的还是被保护的?
- 主动对象享有调用其他对象或其自身操作的主动权,并且当其他对象对其进行调用时,具有对其自身 操作的完全控制权。
- 被动对象不能主动调用任何操作,对其他对象调用自身的操作没有控制。
- 被保护对象不能主动调用任何操作。但对自身的操作有一定的控制功能。
- 持久化:对象是暂时的还是持久化的?它们是否会导致过程或处理器的终止?
- 依赖性:对象的存在或持久化是否依赖于另一个对象?
- 分布性:对象的状态或操作是否能被物理架构中的许多节点所访问?或是被进程架构中的几个进程所访问?
在逻辑视图中,我们认为每个对象均是主动的,具有潜在的"并发性",即与其他对象具有"平行的"行为,我们并不考虑所要达 到的确切并发程度。因此,逻辑结构所考虑的仅是需求的功能性方面。
然而,当我们定义进程架构时,由于巨大的开销,为每个对象实施各自的控制线程(例如,Unix 进程或 Ada 任务),在目前的技术状况下是不现实的。此外,如果对象是并发的,那么必须以某种抽象形式来调用它们的操作。
另一方面,由于以下几种原因需要多个控制线程。
- 为了快速响应某类外部触发,包括与时间相关的事件。
- 为了在一个节点中利用多个 CPU,或者在一个分布式系统中利用多个节点。
- 为了提高 CPU 的利用率,在某些控制线程被挂起,等待其他活动结束的时候(例如,访问外部对象其他活动对象时),为其他的活动分配 CPU。
- 为了划分活动的优先级(提高潜在的响应能力)。
- 为了支持系统的可伸缩性(借助于共享负载的其他过程)。
- 为了在软件的不同领域分离关注点。
- 为了提高系统的可用性(通过 Backup 过程)。
我们同时使用两种策略来决定并发的程度和定义所需的过程集合。考虑一系列潜在的物理目标架构。以下两种形式我们可以任选其 一:
- 从内至外:
由逻辑架构开始:定义代理任务,该任务将控制一个类的多个活动对象的单个线程进行多元化处理;同一代理任务还执行持久化处理那些依赖于一个主动对象的对 象;需要相互进行操作的几个类或仅需要少量处理的类共享单个代理。这种聚合会一直进行,直到我们将过程减少到合理的较少数量,而仍允许分布性和对物理资源 的使用。 - 由外至内:
从物理结构开始:识别系统的外部触发;定义处理触发的客户过程和仅提供服务(而非初始化它们)的服务器进程;使用数据完整性和问题的串行化 (serialization)约束来定义正确的服务器设置,并且为客户机与服务器代理分配对象;识别出必须分布哪些对象。
其结果是将类(和它们的对象)映射至一个任务集合和进程架构中的进程。通常,活动类具有代理任务,也存在一些变形:对于给 定的类,使用多个代理以提高吞吐量,或者多个类映射至单个代理,因为它们的操作并不是频繁地被调用,或者是为了保证执行序列。
注意这并不是产生最佳过程架构的线性的、决定性的进程;它需要若干个迭代来得到可接受的折衷。还存在许多其他方法,例如 Birman 等人5 或 Witt 等人7提出的方法。 确切的实施映射的方法不在本文的讨论范围,但我们以一个小的例子来说明一下。
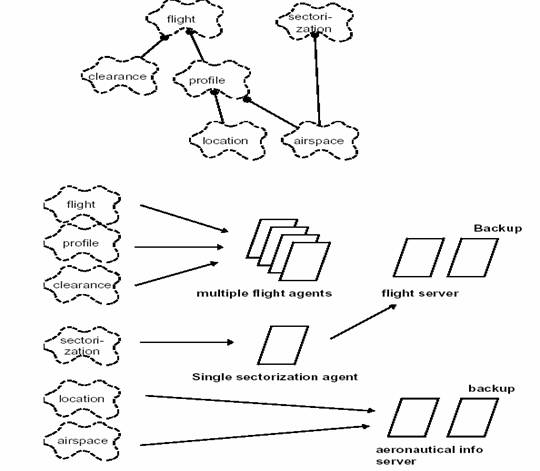
图 12 显示了一个小的类集合如何从假想的空中交通控制系统映射至进程。
flight 类映射至一个 flight 代理集合:有许多航班等待处理,外部触发的频率很高,响应时间很关键,负载必须分布于多个 CPU。并且,航班处理的持久化和分布性方面都取决于 flight server,为了满足可用性,还是使用 flight server 的一台备份服务器。
航班的 profile 和 clearance 总是从属于某个航班,尽管它们是复杂的类,但它们共享 flight 类的进程。航班分布于若干其他进程,特别是对于显示和外部接口。
sectorization 类,为 controller 的权限分配建立了空域划分。由于完整性约束,仅能被一个代理处理,但可以与 flight 类共享服务器过程:更新得并不频繁。
location 和 arispace 及其他的静态航空信息是受到保护的对象,在几个类中共享,很少被更新;它们被映射至各自的服务器,分布于其他过程。
图 12 - 从逻辑视图到过程视图的映射
从逻辑视图到开发视图
类通常作为一个模块来实现,例如 Ada 包中可视部分的一个类型。密切相关的类(类的种类)的集合组合到子系统中。子系统的定义必须考虑额外的约束,如团队组织、期望的代码规模(通常每个子系统 为 5 K 或 20 K SLOC)、可重用性和通用性的程度以及严格的分层依据(可视性问题),发布策略和配置管理。所以,通常最后得到的不是与逻辑视图逐一对应的视图。
逻辑视图和开发视图非常接近,但具有不同的关注点。我们发现项目规模越大,视图间的差距也越大。例如,如果比较图 3 b 和图 6,则会发现并不存在逐一对应的类的不同种类到层的映射。而如果我们考虑类的种类的"外部接口"-网关种类时,它的实现遍布若干层:通讯协议在第 1 层或以下的层,通用网关机制在第 2 层,而特定的网关在第 5 层子系统。
从进程视图到物理视图
进程和进程组以不同的测试和部署配置映射至可用的物理硬件。Birman 在 ISIS 项目中描述了详细的映射模式5。
场景主要以所使用类的形式与逻辑视图相关联;而与进程视图的关联则是考虑了一个或多个控制线程的、对象间的交互形式。
模型的剪裁
并不是所有的软件架构都需要"4+1"视图。无用的视图可以从架构描述中省略,比如: 只有一个处理器,则可以省略物理视图;而如果仅有一个进程或程序,则可以省略过程视图。 对于非常小型的系统,甚至可能逻辑视图与开发视图非常相似,而不需要分开的描述。场景对于所有的情况均适用。
迭代过程
Witt 等人为设计和架构指出了 4 个阶段:勾画草图、组织、具体化和优化,分成了 12 个 步骤7。他们还指出需要某种程度的反向工程。而我们认为对于大型的项目,该方法太"线性 化"了。在 4 个阶段的末尾,可用于验证架构的内容太少。我们提倡一种更具有迭代性质的方法,即架构先被原形化、测试、估量、分析,然后在一系列的迭代过程中被细化。该 方法除了减少与架构相关的风险之外,对于项目而言还有其他优点:团队合作、培训,加深对架构的理解,深入程序和工具等等(此处提及的是演进的原形,逐渐发 展成为系统,而不是一次性的试验性的原形)。这种迭代方法还能够使需求被细化、成熟化并能够被更好地理解。
场景驱动(scenario-driven)的方法
系统大多数关键的功能以场景(或 use cases)的形式被捕获。关键意味着:最重要的功能,系统存在的理由,或使用频率最高的功能,或体现了必须减轻的一些重要的技术风险。
开始阶段:
- 基于风险和重要性为某次迭代选择一些场景。场景可能被归纳为对若干用户需求的抽象。
- 形成"稻草人式的架构"。然后对场景进行"描述",以识别主要的抽象(类、机制、过程、子系统),如 Rubin 与 Goldberg6 所指出的 ―― 分解成为序列对(对象、操作)。
- 所发现的架构元素被分布到 4 个蓝图中:逻辑蓝图、进程蓝图、开发蓝图和物理蓝图。
- 然后实施、测试、度量该架构,这项分析可能检测到一些缺点或潜在的增强要求。
- 捕获经验教训。
循环阶段:
下一个迭代过程开始进行:
- 重新评估风险,
- 扩展考虑的场景选择板。
- 选择能减轻风险或提高结构覆盖的额外的少量场景,
然后:
- 试着在原先的架构中描述这些场景。
- 发现额外的架构元素,或有时还需要找出适应这些场景所需的重要架构变更。
- 更新4个主要视图:逻辑视图、进程视图、开发视图和物理视图。
- 根据变更修订现有的场景。
- 升级实现工具(架构原型)来支持新的、扩展了的场景集合。
- 测试。如果可能的话,在实际的目标环境和负载下进行测试。
- 然后评审这五个视图来检测简洁性、可重用性和通用性的潜在问题。
- 更新设计准则和基本原理。
- 捕获经验教训。
终止循环
为了实际的系统,初始的架构原型需要进行演进 。较好的情况是在经过 2 次或 3 次迭代之后,结构变得稳定:主要的抽象都已被找到。子系统和过程都已经完成,以及所有的接口都已经实现。接下来则是软件设计的范畴,这个阶段可能也会用到 相似的方法和过程。
这些迭代过程的持续时间参差不齐,原因在于:所实施项目的规模,参与项目人员的数量、他们对本领域和方法的熟悉程度,以及 该系统和开发组织的熟悉程度等等。因而较小的项目迭代过程可能持续 2-3 周(例如,10 K SLOC),而大型的项目可能为 6-9 个月(例如,700 K SLOC)。
架构的文档化
架构设计中产生的文档可以归结为两种:
- 软件架构文档,其结构遵循"4+1"视图(请对照图 13,一个典型的提纲)
- 软件设计准则,捕获了最重要的设计决策。这些决策必须被遵守,以保持系统架构的完整性。
图 13 - 软件架构文档提纲

回页首
结束语
无论是否经过一次本地定制的和技术上的调整,"4+1"视图都能在许多大型项目中成功运用。事实上,它允许不同的"风险承 担人"找出他们就软件架构所关心的问题。系统工程师首先接触物理视图,然后转向进程视图;最终用户、顾客、数据分析专家从逻辑视图入手;项目经理、软件配 置人员则从开发视图来看待"4+1"视图。 在 Rational 和其他地方,提出并讨论了其他系列视图,例如 Meszaros(BNR)、Hofmeister。Nord 和 Soni(Siemenms)、Emery 和 Hilliard(Mitre),但我们发现其他视图通常可以归入我们所描述的 4 个视图中的一个。例如 Cost&Schedule 视图可以归入开发视图,将一个数据视图归入一个逻辑视图,以及将一个执行视图归入进程视图和物理视图的组合。
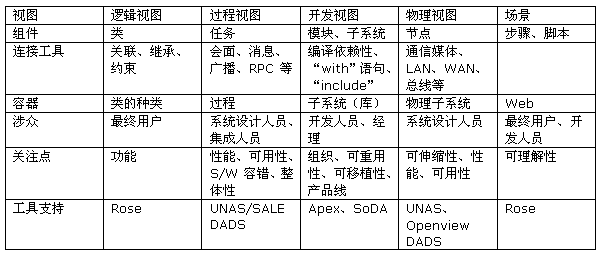
表 1 - "4+1"视图模型一览表
Continue reading 架构蓝图--软件架构 "4+1" 视图模型



