ie5就开始支持gzip了[待考证,反正ie6是支持的]
传统的JS压缩(删除注释,删除多余空格等)提供的压缩率有时还是不尽不意, 幸亏现在的浏览器都支持压缩传输(通过设置http header的Content-Encoding=gzip),可以通过服务器的配置(如apache)为你的js提供压缩传输,或是appfuse中使 用的GZipFilter使tomcat也提供这种能力
现在的问题是这种动态的压缩会导致服务器CPU占用率过高,现在我想到的解决辨法是通过提供静态压缩(就是将js预先通过gzip.exe压缩 好)
一.下面描述在tomcat中的应用
httpServletResponse.setHeader("Content-Encoding", "gzip");//主要是这一句,但是如果仅仅加个header,让容器自己输出的话,没有起作用,返回流的头部还是没有gzip信息,所以还得自己负责返回文件流,这个又加重了服务端cpu,但是减少了带宽。
对于chrome,还要返回Content-Type,否则会被忽略
httpServletResponse.setHeader("Content-Type", "text/plain");//这只对于非图片类型对于safari,直接.gz为扩展名的它处理有问题,要改成别的如.jgz
1.将prototype.js通过gzip.exe压缩保存成prototype.gzjs
2.设置header,我编写了一个简单的AddHeadersFilter来将所有以gzjs结尾的文件增加设置header Content-Encoding=gzip
web.xml中的配置
- <filter>
- <filter-name>AddHeaderFilter</filter-name>
- <filter-class>
- badqiu.web.filter.AddHeaderFilter
- </filter-class>
- <init-param>
- <param-name>headers</param-name>
- <param-value>Content-Encoding=gzip</param-value>
- </init-param>
- </filter>
-
- <filter-mapping>
- <filter-name>AddHeaderFilter</filter-name>
- <url-pattern>*.gzjs</url-pattern>
- </filter-mapping>
测试prototype.js是否正常的代码
- <html>
- <head>
- <!-- type="text/javascript"不可少,有些浏览器缺少这个不能运行,具体已经忘记 了 -->
- <script src="prototype.gzjs" type="text/javascript"></script>
- </head>
- <body>
- <input id="username" name="username" value="badqiu"/><br />
- <input id="email" value="badqiu@gmail.com"/>
- <script>
- <!-- 测 试prototype的方法是否正常-->
- alert($F('username'))
- </script>
- </body>
- </html>
在Apache httpd中可以直接通过在httpd.conf增加AddEncoding x-gzip .gzjs来映射.gzjs文件的header
二.相关压缩率数据
1. prototype.js 1.5.0_rc0原始大小56KB,未经任何处理直接使用gzip压缩为12KB,总压缩率79%
2. 通过js压缩工具压缩过的protytype.js为20KB,使用gzip压缩为10KB,总压缩率为83%
3. 实际项目中的多个js合并成的文件 439KB,直接通过gzip压缩为85KB,总压缩率81%
4. 439KB经过js压缩为165KB,再经过gzip压缩为65KB,总压缩率86%
基本上你都可以忽略js压缩工具的压缩率,直接使用gzip压缩
gzip下载地址 http://www.gzip.org
tomcat的压缩配置示例下载地址: http://www.blogjava.net/Files/badqiu/gziptest.rar
==================================================================
Wordpress之终极Gzip兼容IE6
为了这Gzip我可没有少费功夫啊,之前我已经写过三篇文章《开启GZIP,提速 Wordpress》、《给Wordpress开启Gzip 功能》、《完美启用Gzip压缩JS、 CSS》,三篇文章三个方法,各有特色,一直以来我是将这三个Gzip结合使用的,但是始终没有达到我期望的最佳效果,因为启用后就不得不放弃 IE6的用户。这一bug让我在使用Gzip时很尴尬,之后我也试过给浏览器设置白名单,希望IE6跳过Gzip,最后以失败告终。不过今天终于让我找到 一个可以兼顾IE6的开启Gzip的方法,让我的Wordpress载入速度又上了一个台阶。特地将此方法转载来和大家分享,因为原文是繁体,我就简化了 一下:
1、下载gzip.zip, 解压后上传至网站根目录。
2、修改根目录的.htaccess,增加gz的识别支援及网址改写:
#識辨gz檔案的支援 <Files *.js.gz> AddEncoding gzip .js ForceType application/x-javascript </Files> <Files *.css.gz> AddEncoding gzip .css ForceType text/css </Files><IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
#wordpress靜態 網址,如果沒有使用,就略過
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
#讀到css和js檔,就 重導至gzip.php
RewriteRule (.*.css$|.*.js$) gzip.php?$1 [L]
#讀到.css,判斷如果 瀏覽器支援gzip且.css.gz檔存在,就進行重導
RewriteCond %{HTTP:Accept-encoding} gzip
RewriteCond %{REQUEST_FILENAME}.gz -f
RewriteRule ^(.*).css $1.css.gz [L,QSA]
#讀到.js,判斷如果瀏 覽器支援gzip且.js.gz檔存在,就進行重導
RewriteCond %{HTTP:Accept-encoding} gzip
RewriteCond %{REQUEST_FILENAME}.gz -f
RewriteRule ^(.*).js $1.js.gz [L,QSA]
</IfModule>
3、浏览自己的网站,让CSS和JS产生gz档,并将相应的.gz文件权限设置为777。
4、最后,再次改写.htaccess,把以下代码注释掉或删除。
RewriteRule (.*.css$|.*.js$) gzip.php?$1 [L]
完毕。此Gzip方法是至今我最满意的,效果最显著的,强烈推荐。不过在修改CSS和JS后,还要还原那句代码并重做第3、4步。所以该方法稍 有些复杂,比较适合像我一样喜欢折腾Wordpress的童鞋们。
给 Wordpress 开启 Gzip 功能
曾经我为了给 Wordpress 开启 Gzip 功能真是煞费苦心,但最终还是成功了,并写下日志《开启GZIP,提速 Wordpress》分享给大家。据willin的反馈,他使用该方法感觉 不错,但是我自己用这个方法却发现主题在IE6下裸奔了,至今没有找到问题的根源,之后只好弃用了该方法。郁闷~
但是我一直没有放弃对开启 Gzip 的追求,皇天不负有心人,终于让我找到了两个给 Wordpress 开启 Gzip 的方法,且比在《开启GZIP,提速 Wordpress》中提到的方法更简单,更实用,也没有在 IE6 下裸奔的现象,值得推荐。至于什么是 Gzip、如何检测网站是否开启 Gzip 功能等问题本文就不多作熬述了,欲知答案请移步《开启GZIP,提速 Wordpress》。下面马上切入正题:
方法一:
gzippy 插件。
这对于懒人或者菜菜们来说是个福音和首选,这个插件解压后也不足2K,可谓短小精悍,且上传安装之后也无需另外设置,很方便实用。
下载地址:http://wordpress.org/extend/plugins/gzippy/
方法二:
定义 php.ini。
新建一个名为 php.ini 的文件,输入以下内容,保存并上传至网站根目录即可。
output_buffering = Off
output_handler =
zlib.output_compression = On
因为本人对插件有抵触情绪,能 用代码搞定的就绝不用插件解决!所以我现在用的是方法二,压缩率达到73%,还是比较让人满意的。现在我的 YSlow 成绩又回到了 Grade B,真要感谢 Gzip 的压缩功能啊.
完美启用Gzip压缩JS、CSS
这已经是我自《开启GZIP,提速 Wordpress》和《给Wordpress开启Gzip 功能》两篇文章后第三次介绍Wordpress中的Gzip功能,而这三篇中所涉及的Gzip又各有不同,可以结合实用。在《给Wordpress开启Gzip 功能》中提到的Gzip功能很简单,但是只对Wordpress输出的html进行压缩,所以效果有限。而这篇文章提及的Gzip功能将对 Wordpress中的重头戏JS和CSS进行压缩,这将使Wordpress的载入速度达到一个质的飞跃!
1、把模板目录下的style.css复制一份出来,命名为style.css.php,接着在style.css.php顶部加入这句:
<?php if(extension_loaded('zlib')) {ob_start('ob_gzhandler');} header("Content-type: text/css"); ?>
在最后加上下面代码:
<?php if(extension_loaded('zlib')) {ob_end_flush();} ?>
2、按照下面的方式修改header.php中的css连接
原来的:
<link rel="stylesheet" type="text/css" media="screen" href="/style.css"/>
修改后的:
<link rel="stylesheet" type="text/css" media="screen" href="/style.css.php"/>
这样,你的CSS就被Gzip压缩了,同样的方法可以压缩你的JS。只是在JS的顶部加入的是如下代码:
<?php if ( extension_loaded('zlib') ) {ob_start('ob_gzhandler');} header("Content-Type: text/javascript"); ?>
 说说我自己使用Gzip压缩后的效果吧,在《开启GZIP,提速 Wordpress》中我就提到,根据YSlow的要求,其中Compress components with gzip这项,我的得分仅为F,严重地影响了小站的整体评级。开启Gzip之后,我再用YSlow去检测,现在我的得分是Grade A!再贴个图让各位有个直观的理解,看看我的JS和CSS减了多少肥吧。JS和CSS的大小从102.1K直降到33.8K,足足减少了三分之二的文件大 小,如果你有用prototype.js这样的大型JS,那压缩之后的效果就更可观了。!
说说我自己使用Gzip压缩后的效果吧,在《开启GZIP,提速 Wordpress》中我就提到,根据YSlow的要求,其中Compress components with gzip这项,我的得分仅为F,严重地影响了小站的整体评级。开启Gzip之后,我再用YSlow去检测,现在我的得分是Grade A!再贴个图让各位有个直观的理解,看看我的JS和CSS减了多少肥吧。JS和CSS的大小从102.1K直降到33.8K,足足减少了三分之二的文件大 小,如果你有用prototype.js这样的大型JS,那压缩之后的效果就更可观了。!
开启此Gzip功能比《给Wordpress开启Gzip 功能》中提到的Gzip要复杂的多,因为要对所有JS和CSS一一修改,且要找到并修改调用该JS和CSS的代码,如果你还是刚刚踏入 Wordpress大家庭的小菜菜,那我还是建议你用《给Wordpress开启Gzip 功能》中的插件或php.ini来实现Gzip。
最后友情提醒一下,因为使用此Gzip,需要修改比较多的文件和代码,所以记得备份哟,如果做错也好有个挽回的余地。
开启GZIP,提速Wordpress
今天我用FireFox的YSlow组件对小站进行了评测,结果仅为Grade C,实在是差强人意。虽然自认为本站的速度已经算是很不错了,话说自从换了小张童鞋的息壤主 机后,小站的速度也是突飞猛进,但是为了满足小小的虚容心和完美主义性格,Grade C的结果在我看来是不合格的,我的目标是Grade A!我需要优化、优化、再优化,提速、提速、再提速!
根据YSlow的要求,其中Compress components with gzip这项,我的得分仅为F,严重地影响了小站的整体评级。本文也就重点谈谈如何开启GZIP压缩网页从而给Wordpress提速。
三言两语先简单介绍下GZIP功能,我G来的。GZIP功能可以大幅度地压缩CSS、JS之类的文本型文件,压缩率达60%-90%,挺可观 的。GZIP压缩功能在Wordpress2.3-2.5版本里都是自带的,之后就没有了,我现在用的是Wordpress2.7.1,就更没有这个功能 了。那如何手动开启Wordpress2.7+的GZIP功能呢?
在开始之前,我们先做点准备工作,你也可以用YSlow查一下你的网站评级,然后登陆http://www.whatsmyip.org/mod_gzip_test/检测一下你的网站是否已经开 启了GZIP,等事后可以作个比较。下面是我开启GZIP之前的测试截图。

废话到此为止,进入正题。
1.开启GZIP功能。在根目录下的index.php找到
define(’WP_USE_THEMES’, true);
在其后插入如下代码:
if(ereg(’gzip’,$_SERVER['HTTP_ACCEPT_ENCODING'])){//判断浏览器是否支持Gizp
if(substr($_SERVER['REQUEST_URI'],0,10)!=’/download /’)//排除不需要Gzip压缩的目录
ob_start(’ob_gzhandler’);//打开Gzip压缩
}
2.在.htaccess里面加上RewriteRule (.*.css$|.*.js$) gzip.php?$1 [L]
如果你那可怜的主机不支持.htaccess可写,很遗憾,你就不用往下看了。
3.压缩CSS和JS文件。你可以复制以下代码保存为gzip.php,或者点此下载我的gzip.php文件,下载解压之后上传至根目录即可。让所有的CSS和JS文件访问就以相对根目 录的路径以GET变量传递到了gzip.php,交给gzip.php来全权处理了。
<?php define(
'ABSPATH', dirname(
__FILE__)
.'/');
$cache = true;//Gzip压缩开关
$cachedir = 'wp-cache/';//存放gz文件的目录,确保可写
$gzip = strstr($_SERVER['HTTP_ACCEPT_ENCODING'], 'gzip');
$deflate = strstr($_SERVER['HTTP_ACCEPT_ENCODING'], 'deflate');
$encoding = $gzip ? 'gzip' : ($deflate ? 'deflate' : 'none');
if(!isset($_SERVER['QUERY_STRING'])) exit();
$key=array_shift(explode('?', $_SERVER['QUERY_STRING']));
$key=str_replace('../','',$key);
$filename=ABSPATH.$key;
$symbol='^';
$rel_path=str_replace(ABSPATH,'',dirname($filename));
$namespace=str_replace('/',$symbol,$rel_path);
$cache_filename=ABSPATH.$cachedir.$namespace.$symbol.basename($filename).'.gz';//生成gz文件路径
$type="Content-type: text/html"; //默认的类型信息
$ext = array_pop(explode('.', $filename));//根据后缀判断文件类型信息
switch ($ext){
case 'css':
$type="Content-type: text/css";
break;
case 'js':
$type="Content-type: text/javascript";
break;
default:
exit();
}
if($cache){
if(file_exists($cache_filename)){//假如存在gz文件
$mtime = filemtime($cache_filename);
$gmt_mtime = gmdate('D, d M Y H:i:s', $mtime) . ' GMT';
if( (isset($_SERVER['HTTP_IF_MODIFIED_SINCE']) &&
array_shift(explode(';', $_SERVER['HTTP_IF_MODIFIED_SINCE'])) == $gmt_mtime)
){
// 浏览器cache中的文件修改日期是否一致,将返回304
header ("HTTP/1.1 304 Not Modified");
header("Expires: ");
header("Cache-Control: ");
header("Pragma: ");
header($type);
header("Tips: Cache Not Modified (Gzip)");
header ('Content-Length: 0');
}else{
//读取gz文件输 出
$content = file_get_contents($cache_filename);
header("Last-Modified:" . $gmt_mtime);
header("Expires: ");
header("Cache-Control: ");
header("Pragma: ");
header($type);
header("Tips: Normal Respond (Gzip)");
header("Content-Encoding: gzip");
echo $content;
}
}else if(file_exists($filename)){ //没有对应的gz文件
$mtime = mktime();
$gmt_mtime = gmdate('D, d M Y H:i:s', $mtime) . ' GMT';
$content = file_get_contents($filename);//读取文件
$content = gzencode($content, 9, $gzip ? FORCE_GZIP : FORCE_DEFLATE);//压缩文件内容
header("Last-Modified:" . $gmt_mtime);
header("Expires: ");
header("Cache-Control: ");
header("Pragma: ");
header($type);
header("Tips: Build Gzip File (Gzip)");
header ("Content-Encoding: " . $encoding);
header ('Content-Length: ' . strlen($content));
echo $content;
if ($fp = fopen($cache_filename, 'w')) {//写入gz文件,供下次使用
fwrite($fp, $content);
fclose($fp);
}
}else{
header("HTTP/1.0 404 Not Found");
}
}else{ //处理不使用Gzip模式下 的输出。原理基本同上
if(file_exists($filename)){
$mtime = filemtime($filename);
$gmt_mtime = gmdate('D, d M Y H:i:s', $mtime) . ' GMT';
if( (isset($_SERVER['HTTP_IF_MODIFIED_SINCE']) &&
array_shift(explode(';', $_SERVER['HTTP_IF_MODIFIED_SINCE'])) == $gmt_mtime)
){
header ("HTTP/1.1 304 Not Modified");
header("Expires: ");
header("Cache-Control: ");
header("Pragma: ");
header($type);
header("Tips: Cache Not Modified");
header ('Content-Length: 0');
}else{
header("Last-Modified:" . $gmt_mtime);
header("Expires: ");
header("Cache-Control: ");
header("Pragma: ");
header($type);
header("Tips: Normal Respond");
$content = readfile($filename);
echo $content;
}
}else{
header("HTTP/1.0 404 Not Found");
}
}
?>
搞定,再去http://www.whatsmyip.org/mod_gzip_test/检 测一下你的网站是否已经开启了GZIP,如果上述步骤都操作正确,那测试结果应该如下图所示。
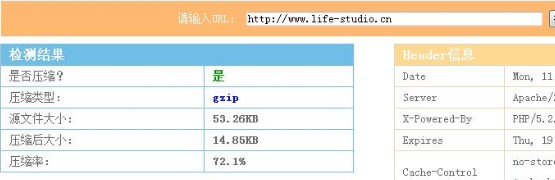
既然已经对CSS和JS文件压缩了,那我们再用YSlow来评测一下等级。Oh耶!我的小站从Grade C上升到Grade B了,不过说实话,虽然把CSS和JS文件压缩了72%,但并没有很明显地提速,因为本来就已经够快的了,哈哈。
说些题外话,根据YSlow的要求,我的小站要从Grade B上升到Grade A怕是有些难度了。因为首页上加载了两个Flash,还有5个JS,拖慢了不少速度,等会有时间我研究下把这5个JS合并,或许会好些吧。我又查了下新 浪、网易、搜狐这样的大型门户网站,也不过Grade B甚至Grade C,我心理平衡一下,嘿嘿。
Continue reading gzip系列
1 概述
系统应用集成中一般对各系统中数据分为两类
操作型数据:它 有细节化,分散化的特点
决策型数据:它 有综合化,集成化的特点
数据仓库概念的提出也把数据处理划分为了操作型处 理和分析型处理两种不同类型,从而建立起了DB-DW的两层体系结构。但是有很多情况,DB-DW的两层体系结构并不能涵盖企业所有的数据处理要求,比如 有些实时性决策问题,它要求获取数据周期不能太长,而且也需要一定程度的汇总。这样的问题可以借助于DB-DW的中间层ODS(操作数据存储)来解决。它 象DW一样是一种面向主题,集成的数据环境,又象操作型DB一样包含着全局一致的,细节的当前的数据。我们看下常用的几种系统应用集成需求:
我要了解企业目前的运转情况!(实时监控)
我要知道某地区近5年内的销售情况以制定未来的发展策 略!(决策支持)
我要知道哪些是值得发展的优质的顾客!(预测)
提供企业内部和外部的有用信息以支持中期或远期决策
提供事实的全局信息进行实时监控与临时决策
要满足上面所有的需求,不管是传统的OLTP系统 还是已经集成的数据仓库,都是很难完成任务的。由于这些原因,ODS应运而生。ODS可以看做是围绕主题进行动态整合的一种应用型体系结构,它有如下一些 特点:
从应用子系统获取数据
提供几乎精确到每秒的企业整体应用状态
数据一旦过期就将转入DW
实时决策与预警提示
使用者多为前端业务人员
2 DW与ODS比 较:
| 数据仓库 | ODS |
| 目的 | 决策支持 | 接近实时监控 |
| 共同点 | 整合数据 | 整合数据 |
| 面向主题 | 面向主题 |
| 不同点 | 静态数据
(延迟>24小时) | 动态数据
(延迟>1秒) |
| 历史数据 | 当前数据 |
| 概括性数据 | 细节化数据 |
| 实施方案 | 实施结果 | 优势 | 缺陷 |
| 数据仓库(DW) | 企业能够分析DW中的历史数据,进行中远期的规划 | 可以解决企业的决策需求 | 不能满足企业的实时监控和实时业务需求
|
| 操作型数据存储(ODS) | 企业能够把握ODS中的当前综合数据,对企业的及时运行情况随时掌控 | 可以满足企业的实时监控和实时业务需求
| 不能满足企业的中远期决策需求 |
| DW+ODS(如下图) | 企业能够分析ODS中的当前综合数据,对企业当前运行情况进行宏观控制;能够分析DW中的历史数据,对未来进行合理规划 | 既能把握实时的企业运作情况,采取及时的应对措施;又能把握历史纵向概况,进行远期战略规划 | |
图1 ODS+DW方案
4 三种类型的ODS:
类型一:以几秒为间隔的更新(非常贵、不常用、数 据整合能力弱)
类型二:以约1小时为间隔的更新(常用、数据整合 能力较强)
类型三:以约1天为间隔的更新(常用、数据整合能 力较强)
ODS技术的引入和应用,为企业在日常经营中进行 即时OLAP提供了一种解决方案使得企业无须建立一个“臃肿”的DW,就可以进行一些非战略性的的中层决策,来实现对企业的日常管理和控制,同时也能获得 较快的响应速度
Continue reading 数据仓库(DW)与操作型数据存储(ODS)
extjs GridPanel 使用jsonstore的load来加载远程数据:
Ext.onReady(function() {
var store = new Ext.data.JsonStore({
url : 'getRes.ax',//远程加载
root : 'rows',//告诉store,server返回json数据rows是本页的记录数组
totalProperty : 'count',//告诉store,server返回json数据中count表明总共记录数
remoteSort : true,//远程排序
fields : [{
name : 'id',
type : 'int'
}, {
name : 'actived',
type : 'bool'
}, {
name : 'selected',
type : 'bool'
}, {
name : 'value',
type : 'string'
}],
listeners : {
beforeload : function() {
//beforeloadr事件是添加参数的最好途径
//这里可以添加查询条件
// can add the filter params at here
// store.setBaseParam('selected:bool',true);
// store.setBaseParam('actived:bool',true);
store.setBaseParam('ps', Ext.encode({
'selected' : true,
'actived' : true
}));
//结合pagingtoolbar使用时,每次的分页排序,会向serversrvr传参数start[开始的行数],limit[需要的行数],sort[排序的字段],dir[排序方向]。
}
}
});
var PAGESIZE = 2;
var grid = new Ext.grid.GridPanel({
store : store,
bbar : new Ext.PagingToolbar({
store : store,
displayInfo : true,
pageSize : PAGESIZE
}),
columns : [{
header : 'actived',
sortable : true,
dataIndex : 'actived'
}, {
header : 'selected',
sortable : true,
dataIndex : 'selected'
}, {
header : 'value',
sortable : true,
dataIndex : 'value'
}],
columnLines : true,
viewConfig : {
forceFit : true,
emptyText : 'No data available'
},
stripeRows : true,
header : false
});
store.load({
params : {
start : 0,
limit : PAGESIZE
}
});
var vi = new Ext.Viewport({
layout : 'fit',
items : grid
});
vi.show();
});
Continue reading extjs 分页排序
通过这篇文章,可以发现通常所用的session,cookie多么的不安全!但是也不要杯弓蛇影,关键是要依据情景来制定策略!
见互动的文章
session fixation attacks(固定session攻击)
就是要注意,cookie是可以被客户端改动的,也可能客户端开启了第三方cookie,也是可能被窃听的。
那么什么情况下会被入侵:
信任cookie的值:例如用其(固定的值)直接作为登陆凭证,例如被它做了sql注入--安全的做法是:cookie保存随机值,或是加密的用户名密码。你也许会想,加密的用户名密码还不是可以放到修改的cookie里面--是的,但是hackerr怎么得到这个用户名密码?一:它安装木马---这个就不是web程序的原因了,要怪就怪用户自己染上木马。二:用户自己就是hacker,有这个程序的用户名密码--那还费什么劲搞hack,直接输入用户名密码登陆不就得了。(我就是犯了这个牛角尖)
未经加密的http通信中cookie和基于cookie的session都是不安全的,不要用cookie存储机密信息。sessionid这类机密信息应该设置为安全,cookie.setSecure(true);可惜java servlet是没有设置jsession为true的。
不过可以这样:
final HttpSession session = httpRequest.getSession(false);
if (session != null) {
final Cookie sessionCookie = new Cookie("JSESSIONID",
session.getId());
sessionCookie.setMaxAge(-1);
sessionCookie.setSecure(false);
sessionCookie.setPath(httpRequest.getContextPath());
httpResponse.addCookie(sessionCookie);
} 话说回来,一个没有使用ssl的站点,加密cookie又有什么用呢?即使监听者获取不了jsessionid之类的cookie,但是他可以看到明文的http内容,他就不需要去猜什么用户名密码之类的。
这样说来还是看安全定位,确实很重要的传输,还是使用ssl吧。
在ssl中还要注意sessionid的安全性:
- 一些程序在一些HTTP页面就发送一个令牌,然后再登录页面开始使用https,并且登录时也不修改此令牌,结果最初并未通过验证的用户会话在登录后被升级为通过验证的会话。窃听者可以在登录前就拦截到这个令牌。所以为了提高安全性,程序可以在登录的时候发送令牌或发送一个新令牌。
- 程序容许通过HTTP登录,如果攻击者成功将用户的链接降级为HTTP,他仍然能够拦截这个令牌。
- 如果所有的页面都是用HTTPS,但图片和一些js,css等的静态文件是使用HTTP传输。这时如果静态文件和登录等页面时在同一个域下,令牌也会通过HTTP泄露。所以将静态文件使用别的域好处是很多的。
CAS的TGC(cookie)还是要配合SSL来保证安全的(这样看来CAS这方面还是有缺陷。),它的TGC一旦被窃听,就会被利用。
总结一下,一般没有加密的http内容都是可以被窃取的,这种情况下,session,cookie,内容等都不是安全的。如果想要提高安全,就是用ssl吧,无论从经济,技术复杂度,架构复杂度来说,都是划算的。但是不是使用了ssl就万事大吉,仍然需要做些防范来保证session令牌的安全性。
参见文章:
安全的session管理 http://blog.ureshika.com/archives/500.html
session 和 cookie 到底有什麼差別?安全性 http://bbbb7787.blogspot.com/2010/10/session-cookie.html
提高session的安全性(这是对《黑客攻防技术宝典-web实战篇》一书的概括,建议看看这本书) http://hi.baidu.com/billdkj/blog/item/e72ce5257cf93d6b35a80fc2.html
Continue reading web安全中的cookie欺骗以及session的安全性
数据库
数据库就是结构化的数据仓库。人们时刻都在和数据打交道,如:存储在个人掌上电脑(PDA)中的数据、家庭预算电子数据表,企业的财务、仓库数据,银 行、 电信数据等等。对于少量、简单的数据,如果它们与其它数据之间的关联较少或没有关联的情况下,他们可以简单的存放在文件中。当然如果所有的数据结构都很简 单,那么数据库管理系统就没什么用了。但是企业数据都是相关联的。如:职员表链接到名称和地址的记录,订单记录需要与库存信息相对应,海运记录需要与信用 额度相对应,等等。通常来说,不可能使用普通的记录文件来管理大量的、复杂的系列数据,如:银行的客户数据,或者生产厂商的的生产控制数据。普通记录文件 没有系统结构来系统的反映数据间的复杂关系,它也不能强制定义个别数据对象。
数据库管理系统
数据库管理系统(DBMSs),或者数据库管理器,已经发展了近二十年,来解决上面提到的这些需求。数据库管理器是近似于文件系统的软件系统,通过它, 应 用程序和用户可以取得所需的数据。然而,它们又不象文件系统,它们定义了所管理的数据之间的结构和约束关系。并且,数据库管理器提供了一些基本的数据管理 功能:
数据安全: 在商业上,数据库必须是一个可以存储数据的安全的地方。数据库管理器必须提供有效的备份和恢复能力,来确保在灾难和错误后,数据能够尽快的可以被应用所访 问。
数据权限: 对于一个企业来说,它把关键的和重要的数据存放在数据库中,数据库管理系统必须能够防止未授权的数据访问。
数据共享: 一个数据库必须允许多个应用和用户同时进行数据访问,而且不影响数据的完整性。例如:如果两个用户试图同时修改同一条记录,两个修改操作都必须被处理,并 且产生一个可理解的干净的结果。
数据 组织: 基于文件的数据的主要优势就在于它利用了数据结构。数据库的结构使开发者避免了针对每一个应用都需要重新定义数据逻辑关系的过程。
数据库数据模型
数据库管理系统的发展已经经历了一个漫长复杂的过程。人们提出了许多数据模型,并一一实现。其中比较重要的三个就是:
分 级模型: 在一个分级的数据库中,数据项间具有父项与子项的关系。例如:一个顾客的记录包括名称和地址信息,它可能就是一系列订单记录的父项,每个订单记录包含了关 于这个订单的详细信息。
网络 模型: 在一个网络数据库中,数据项之间有更多的相互关系。这些关系通常用来描述一个图形形状,或者网络中形成刀片结构的那些节点和它们之间的关系。
关 系模型: 在关系型数据库中,数据项保存在行中,文件就象是一个表。关系被描述成不同数据表间的匹配关系。一个区别关系模型和网络及分级型数据库的重要一点就是数据 项关系可以被动态的描述或定义,而不需要因为结构被改变而卸载然后重新加载数据库。
关系模型
早在1980年,数据库市场就被关系型数据库管理系统所占领。关系模型的成功并不在意料之外。这个模型基于一个可靠的基础,它可以简单并恰当的将数据 项描 述成为表(table)中的记录行(raw)。关系模型第一次广泛的推行是在1980年中,是因为一种标准的数据库访问程序语言被开发出来,它被称作结构 查询语言(SQL)。
今天,成千上万使用关系型数据库的应用程序已经被开发出来,包括跟踪客户端处理的银行系统,仓库货物管理系统,客户关系管理(CRM)系统,以及人力 资源 管理系统。由于数据库保证了数据的完整性,企业通常将他们的关键业务数据存放在数据库中。因此保护数据库避免错误以及灾难已经成为企业所关注的重点。
数据库备份中的一致性和实时性
一致性和实时性
一个一致性的数据库就是指数据处理响应完成了的数据库。例如:一个会计数据库,当它的记入借方与相应的贷方记录相匹配的情况下,它就是数据一致的。 一个 实时的数据库就是指所有的事务全部执行完毕后才响应。如果一个正在运行数据库管理的系统崩溃了,而对事务的处理结果还存在缓存中而没有写入到磁盘文件中的 情况,当系统重新启动时,系统数据就是非实时性的。数据库日志被用来在灾难发生后恢复数据库时保证数据库的一致性和实时性。
数据库恢复
正规的数据库备份是最基本和有效的数据库容灾技术。数据库备份和恢复技术与我们在错误!未找到引用源。中讲述的文件系统的备份和恢复是不同的。
数 据库事务
如果要明白备份恢复技术,明白数据库事务的种类是很有用的。一个事务就是一个事务活动所引起的一系列的数据库操作。例如,一个会计事务可能是由以下部 分组 成:
读取借方数据
减去借方记录中的借款数量
重写借方记录
读取贷方记录
在贷方记录上的数量加上从借方扣除的数量
重写贷方记录
写一条单独的记录来描述这次操作,以便日后审计所有这些操作组成了一个事务,描述了一个业务动作。在上述例子中,无论借方的动作或是贷方的动作哪一个 没有 被执行,数据库都不会反映该业务执行正确。
数据库管理系统在数据库操作时强迫进行事务定义,这意味着或者一个事务定义的应用的全部操作结果都反映在数据库中,或者都没有反映在数据库中,即使数 据库 在事务执行过程中崩溃的情况下。
事务定义是关系数据库中最重要的关系之一。上述例子包含了两个数据库操作:从借方数据中扣除资金,并且在贷方记录中加入这部分资金。如果系统在执行事 务的 过程中崩溃,如果此时已修改完毕借方数据,但还没有修改贷方数据,资金就会在此时物化。把这两个步骤合并成一个事务命令,这样在数据库系统执行时,要么全 部完成,要么全部不完成,但当只完成一步时,系统是不会对已作的这一步做出响应的。
数据库崩溃恢复
一个运行着数据库系统的计算机随时都可能宕机。然而“已借未贷”或“已贷未借”的情况都可能出现。当系统崩溃后重启时,数据库管理系统必须允许这种可 能性 的发生,也就是说,在磁盘数据文件中可能包含一些部分完成的事务,在应用能够访问数据库数据之前,这些必须全部被检出。
防止上述情况发生的基本技术就是保存一份连续日志,记录将做的和完成的操作。当需要修复损坏的数据库时,数据库系统重新应用这些日志,寻找那些将要执 行但 未完成的任务。如果任何类似的事务的已经在数据库中反映,这一定是颠倒的,并且数据库必须回滚。
使用这种日志重新应用的技术,数据库系统可以避免宕机所带来的已接受事务(应用已确认执行完毕的事务)的丢失。数据修复时,那些在宕机时处理结果还存 在缓 存中的已接受事务,结果会存放到磁盘文件中。未接受事务(还没有被应用确认的事务)会被回滚,消除它所带来的对其他数据的影响。
文件系统缓存和数据库恢复
如果使用文件作为数据库的数据存储方式会给我们的讨论增加一些额外的复杂性,因为文件管理系统有它自己的缓存。如果一个数据库系统在宕机后立 刻重新启动,那么它所包含的文件可能并没有实时刷新到存储中,这是由于在系统宕机时,文件系统的缓存没有写入到存储的原因 。在这种情况下,数据库恢复进程必须重新应用数据日志刷新。也就是说,在系统宕机的情况下已接受事务也不会丢失。
归档日志:
长时间的数据库恢复
大多数的数据库都支持数据库日志归档,支持企业保存一个长时间的数据刷新历史。如果所有的基于一次全备份时间点之后的归档数据全部可用,那么就可以通过以 下步骤恢复成为一个最新的数据库。
恢复备份拷贝
在已经恢复的数据库上重新应用所有的归档日志。
在已经恢复的数据库上重新应用数据库日志。
这也许是一个灾难后完全丧失服务能力数据中心的唯一恢复数据方法。在这个工作过程步骤中,数据库全备份数据和归档日志必须快速的传送到灾难恢复中心。为了 实现完全的实时数据库恢复,镜像或复制当前的数据库日志到恢复中心也是必需的。
数据库备份技术
就如前面对恢复作用的描述,一个数据库的数据库备份必须必须是一个数据库的完整的映像,在这个映像的时间点上,没有部分完成的事务存在。这可以通过数据库 的离线备份来实现,因为在这种情况下,没有事务需要处理。这种方式的缺点在于,在备份过程中,没有应用能够使用数据库。数据库在线的时候也可以进行备份, 在这种情况下,备份程序要确保不管数据访问多么活跃,都能够得到一个完整的数据拷贝。
离线数据备份
如果备份时数据库不可以被应用所访问,那么我们称这种备份为离线备份或冷备份。冷备份可以通过关闭数据库然后进行文件备份来实现。离线数据库备份是简单 的,也是被认为有效的备份技术。但是逐渐的,企业发现把他们的数据库停下来,然后进行备份,这种方式完全不切实际。而且,在一些老的数据库管理系统中,冷 备份拷贝不能用来进行前滚,因为它们与数据库日志不同步。在新的数据库设计中,已经解决了冷备份拷贝与数据库日之间的同步问题,所以前面的问题也就逐渐不 成为问题了。
在线数据库备份
现在大多数的数据库都可以在应用进行数据访问时进行数据备份。在备份活跃数据库时有两种基本技术,被称作逻辑的和物理的在线分别备份。
大多数数据库管理系统都支持逻辑在线备份。例如:被包含在Oracle数据库的RMAN工具和Sybase数据库的“dump database”命令。逻辑在线备份之所以这么命名,是因为它拷贝了数据库的逻辑单元,而不是存储设备列表或是存储逻辑单元的文件。逻辑数据库备份工具 通常和恢复、修复工具放在一起,因此产生有问题备份的几率较小。逻辑数据库备份的主要缺点就是他无法利用存储设备的快照技术来减少对应用的影响。因为在一 个逻辑数据库备份的过程中,系统性能会大大的降低,因此它对总是处在活跃状态的数据库并不合适。
在线数据库备份也可以通过物理的备份数据库底层所 包含的文件来实现。数据库的数据文件并不是随时都可以进行拷贝的,因为数据库始终在不断的刷新这些文件。一个文件的拷贝包含有非全部完整事务的概率很高, 而且也不要期望通过数据库修复来恢复数据的一致性。
要确保一个具有一致性的系列文件备份,数据库必须处于一个静止状态,没有事务提交,也没有缓存的数据需要写到存储中。当备份结束后,数据库可以被重新激 活。当然在数据库备份时,数据库时不可用的,这样的结果与离线数据备份基本相同。
一些文件系统和卷管理器支持数据快照。如果可以制作一个基于数据库所包含文件的快照,那么数据库只需要在快照初始化的一瞬间是静止的即可。一旦快照初始化 完毕,数据库就可以重新提供访问能力。快照使备份可以进行在应用正在访问“实际”的数据库的过程中。因此,物理数据库备份可以是在(近)线的,而且能够保 证数据库拷贝的一致性。
数据库静止状态
不同的数据库支持不同的备份技术。例如:Oracle,将表空间(一组表)置于在线的备份模式。这样的一份备份数据就可能不一致,因为数据库会在备份模式 下会不断的刷新数据。然而恢复却可以是一致的,因为在备份过程中,额外的信息被数据库的管理日志记录下来。重新应用日志记录了数据库在备份状态下的变化, 并将它恢复成一致的状态。
其它的数据库管理,包括Sybase ASE和DB2,会暂时的挂起所有事务并且将缓存保存,这样一个基于快照的数据库所包含文件的拷贝就是一个一致性的数据库拷贝。
包含了卷管理和文件系统快照的物理数据库备份技术是一种非常强大的技术,因为它基本消除了应用不能进行数据访问的备份窗口时间。例如:数据库可以将数据直 接或间接的存储在镜像的逻辑卷上。要进行备份的情况下,数据库管理员可以将数据库暂时静止,将镜像卷与存储分离,然后重新激活数据库。被分离的镜像卷包含 了一个一致的数据拷贝,可以通过它完成一个数据库复制。这种情况下的应用不能访问数据库的备份窗口只有几秒钟或几分钟。
当被剥离的镜像卷连接到存储网络中,可使用一个额外的服务器来进行数据的拷贝。因为使用了独立的存储设备和服务器资源,因此对数据库应用性能没有任何影 响。唯一的缺点是,当基于被剥离的镜像卷的数据库备份拷贝完成后,镜像卷需要重新连接到数据库存储卷中。重新同步所有的I/O会影响应用的I/O。镜像技 术可以记录所有在剥离镜像卷后改变了的数据,在镜像卷重新接入后快速同步数据,这种技术使同步对应用的影响降到最低。图1-4使用流程图描述了脱离主机的 备份方式。流程图同样强调了快照可以在运行着数据库的服务器上进行备份。
数据库增量备份
数据库的不断增长和对可用性要求的提高,使数据库全备份在许多情况下无法完成。如同文件系统一样,如果在两次备份间只有少量的数据变化,数据库增量备份可 以缩短数据库备份时间。如果只是变化了的数据被拷贝,可以节省备份时间和备份介质。与全备份类似,增量备份也可以是逻辑的或是物理的。
逻辑增量备份
归档数据库日志是逻辑数据库增量备份的一种方式。通过恢复一次数据库全备份和重新应用归档日志,可以将数据库恢复到归档的最新时刻。把全备份数据和所有的 归档日志存放在一个安全的地方,是一个很有用处的恢复技术。
随着归档日志的堆积,恢复时间和对介质的占用都会随之增长。对于每一个企业,都有一个对增量恢复窗口的可容忍的极限。因此,增量备份策略应该包含定期的数 据库全备份,以便经常建立新的基点。
一些数据库管理器可以在数据库正在运行时执行数据库逻辑增量备份。一个逻辑增量备份在开始时首先检测自上次备份后改变了的数据块的列表。这些块被读取并被 传送到备份服务器。增量备份减少了全备份必须被执行的频率。使用这种技术,数据库恢复就可以是自动的,因为数据库管理器的恢复功能可以从以前的全备份和后 来的增量备份创建一个较新的数据库映像。增量备份使数据库性能只是稍有加强,因为数据库管理器必须创建一个变化数据块的列表。
物理增量备份
包含数据库系列文件的文件系统的增量备份有效的创建了一个数据库的物理增量备份。但当一个数据库管理器刷新表中的一行数据时,只有包含这条数据的文件块改 变了,其余的文件块并没有受到影响。然而针对文件的任何改变都会导致在增量备份中整个文件被拷贝,这种基于文件的增量备份通常等同于数据库全备份。如果数 据库管理器或者备份程序能够识别在数据库文件中变化了的数据块,就可以只备份变化的数据块;有这么一种技术被称作数据块级增量备份。
在使用快速镜像不太现实的情况下,除使用更少的备份介质外,数据库增量备份能够减小备份窗口。一些数据库管理器能够执行透明的数据库物理增量备份和恢复, 使对个别增量备份的管理降到最低。要完成一个基于块级别的备份的数据库恢复,首先应恢复最新的全备份,然后重新应用所有的后面的增量备份来恢复数据库映 像。
恢复任何的增量备份都需要花费时间。数据库管理员通常制定周期全备份计划,以便定期改变新的数据恢复基点,限制最高的增量跳越数量(和最糟糕情况下的恢复 时间)。一些备份程序可以实现被称为“合成全备份”的功能,这是通过第二台服务器上的增量来实现的。这些合成全备份在每一次增量的恢复后都会产生一个新的 基点。
从备份恢复数据库
通过正规备份,并且快速的将备份介质运送到安全的地方,数据库就能够在大多数的灾难中得到恢复。恢复是文件的使用是从一个基点的数据库映像开始,到一些 综合的备份和日志。由于不可预知的物理灾难,一个完全的数据库恢复(重应用日志)可以使数据库映像恢复到尽可能接近灾难发生的时间点的状态。对于逻辑灾 难,如:人为破坏或者应用故障等,数据库映像应该恢复到错误发生前的那一点。
在一个数据库的完全恢复过程中,基点后所有日志中的事务被重新应用,所以结果就是一个数据库映像反映所有在灾难前已接受的事务,而没有被接受的事务则不被 反映。为了恢复数据库误操作等错误,完全的恢复时不合适的,因为如果重新应用所有事务,错误就会重复。数据库恢复应用程序允许管理员停止日志前滚在错误发 生前一点。数据库恢复可以恢复到错误发生前的最后一个时刻。
检验数据库备份
大多数的企业都会定期地对他们的数据库进行备份,但是却没能经常地对数据库备份进行检验。数据库备份会由于以下各种原因而变得无效:
元数据(例如一个Oracle控制文件或SQL Server控制数据库)缺失
在物理备份的过程中数据库处于非静止的状态
一个或多个必需的数据库文件从备份中丢失
数据库被破坏后才进行备份
从某种意义而言,无效的数据库备份比根本不做备份的情况更糟,因为无效的数据库备份会造成一种安全的假象。因此,检验数据库备份是一项非常重要的工作,尤 其是在进行了自动备份进程之后或是在数据库结构改变之后。即使是没有任何改变发生,定期进行检验也是必需的,例如可以定期地检测损坏的介质或磁带驱动器等 等。
为了将检验工作对数据库生产运行的影响冲突降至最低,备份的检验工作需要使用备用资源。一个正在用于检验修复备份的数据库应该带有一个备用数据库标识符或 服务器名称以免客户端会将信息错误地发送给检验数据库。检验内容应该既包括使用全部的归档日志的数据库恢复资源,也包括使用厂商提供工具进行数据库一致性 的检验。
管理数据库日志
对于容灾而言,数据库备份应当存贮在远离数据库的地方。为了达到最优容灾状态,在灾难发生后能够容易地获取数据库日志也是非常必要的。数据库归档日志通常 保存在备份储存的地点。数据库管理员必须在数据库实时恢复和资源占用量两者之间找到平衡,从而决定进行数据库日志归档的频率。过多地进行归档可以降低数据 损失的潜在危险,但是浪费了更多的进程和I/O资源,很有可能增加了处理的响应时间。过少地进行归档可以降低资源的平均占用量,但是延长了两次归档的间隔 时间,很有可能导致不能做到精确的实时恢复。
如果一个数据库和它的联机日志被损坏了,那么即使马上进行了严密的数据库备份和日志归档,数据也极有可能丢失。因此,一个完整的数据库融灾策略的一个重要 部分就是对联机的数据库日志进行复制,这样在进行修复处理时就可以及时利用这些复制的内容准确无误地修复数据库。联机数据库日志可以通过有限的距离进行镜 像。如果距离过长,数据库管理员可以通过多路转接技术或者通过企业网络同时进行本地和远处的日志拷贝。多路转接技术通常比镜像和低水平复制(如数据卷)的 速度要慢一些,因此如果可以的话要尽量选择后一种方式。
最高级别的数据库实时恢复是在每次事务提交的之前同步进行数据库日志的传输和归档。换句话说,必须要在日志已经被转移到另外地点后,才进行事务的提交。显 而易见,这种选择执行起来的代价是非常昂贵的,因而在实践中较少采用。
数据库复制
周围环境的灾难,例如:地震、洪水,或者暴乱会使整个数据中心及周围环境彻底丧失数据服务的能力。为了恢复一个灾难中的数据库,必须有一个灾难破坏范围之 外的一个数据的冗余拷贝,并且当恢复中心数据恢复完毕后,必须可以响应客户端的请求。
使用传输日志方法的复制
保证数据库可恢复的环境容灾的最基本挑战就是如何保证容灾地点具有最新的数据。或许实现这种状态的最简单办法就是在数据中心与容灾地点间物理的传送归档日 志,例如,使用快递或运输服务。在恢复地点,日志被备份数据库(有的叫做备用数据库)重新应用来实现数据“刷新”。对于应用来说,如果可以容忍一整天的数 据丢失,那么这种简单的方法也许就足够了。它的主要缺点就是数据刷新和重路由客户端请求的劳动强度比较高,很容易出现人为错误。
对于简单应用和小型数据库,日志传输和数据库刷新技术可以通过在网络上执行定期的日志传送和刷新任务来自动完成。
数据库管理器复制
今天,大多数数据库管理器支持精密的实施复制,允许例如一对多、双向的复制。也可以是数据库子集的复制,只将感兴趣的数据复制到目标端。在分布式数据库最 初设计时,数据库管理器复制就可以用来实现容灾复制。
数据库复制需要在主站点和恢复站点间有一个高性能网络的连接,但即使这样也不能实时同步,这意味着在数据库完全将数据反映到备用数据库有一个时间延迟。一 些数据库支持同步复制,虽然解决了上面的问题,但是它明显减低了主数据库的性能,因为只有当所有的复制任务全部结束后,数据库才能继续接收数据。
针对数据库的存储复制
数据库复制要求具有专门的数据库管理技术。额外的,一些基于数据库的信息服务在数据库之外存储了额外的数据。为了实现灾难恢复,所有的应用信息都必须复制 到远程站点。存储复制是针对数据库复制的一个简单可行的办法,它可以将数据库数据和其它数据全部从数据中心复制到恢复站点。
数据库的内容可以在卷一级或者文件一级进行复制。稳定的、高性能的文件系统复制也相当优秀。可靠的高性能卷复制能够使远程复制数据文件、在线日志和归档日 志变得非常简单。如果所有的数据文件、日志文件,及其它的辅助数据都存放在一个独立的文件系统或独立的卷中,复制就会变得非常简单。
卷管理器对数据库恢复的非常有利,原因在于它在数据中心与容灾站点执行同样顺序的操作。如果没有这个特点,它的数据不能够保证与实际数据库先前的状态一 致,也就是说复制就不能作为数据库恢复的基础。
复制的延时
无论数据库复制还是存储复制,都会将认为无操作和应用错误复制到恢复端。例如,在主站点错误的删除了一个表,那么恢复中心也同会删除,因此使用复制无法纠 正错误。
如果在数据中心与恢复中心的数据刷新上存在一定的可配制的延时,数据库复制就可以用来一些逻辑错误。例如,如果复制日志在应用到备用数据库前保留一小时, 而逻辑错误在一小时之内被发现(通常是这样),这样错误还没有反映到复制数据库中。可以立即将复制停止,然后可以使用备用数据库恢复主数据库。
全局群集管理
因为更加坚固,在群集上,数据库应用可以同时运行在主站点和备用站点。在一个单独的数据中心内两个或更多的群集计算机可以通过一个大范围的网络连接成全局 群集,他们是一个平等的高可用系统。当配制了多个恢复站点,或者一个恢复站点复制到第二个恢复站点,可以使用全局群集进行复杂的管理。
在错误切换的复杂性上和站点切换操作的限制性上,全局群集不同于本地群集。与本地群集相比,全局群集的错误切换往往不是自动的,管理员的决定通常需要经过 严肃的考虑。全局群集的任务就是方便的提供一个分布的高可用服务器的全局的视图,并且可以通过一个单独的点来进行控制。
概要:数据库恢复层次
下面列出的数据库恢复技术是按照他们所能够提供的保护能力的顺序列出的,也同时是使用他们所需要的资金,方便程度,和技术复杂性的排列顺序。每一种技术都 必须与他前面的技术共同使用。例如,磁盘镜像必须伴随着数据库备份和日志归档。
正规数据库备份和日志归档
磁盘镜像
本地群集
数据库复制
全局群集
对于希望恢复时间(RTO)时间在几个小的内的企业,正规的数据库备份和日志归档也许就能满足。数据库备份和归档日志应该被保存在离数据中心有一定距离的 地方。高级的备份软件的特性,如自动的定期的块增量备份可以减少管理成本,缩短备份窗口,以及最小化恢复时间。
通过简单的镜像硬件和网络,镜像数据库存储dada减少了因为硬件故障所引起的数据库停机。也可以通过剥离镜像的备份提高数据库的可用性。
可以通过群集技术提高数据库级信息服务的可用性。一个本地群集可以使由于系统的单点而出现故障的可能降到最小。当错误引起临时的损耗,服务恢复时自动的。 在共享数据的群集中,损耗窗口可以为零。在群集中,备份可以运行在导入了数据库服务器镜像数据的辅助服务器上。
为防止站点实效而进行的灾难恢复中,数据库必须复制到远程站点。数据库复制的最简单方法就是将归档日志传送到远端,然后在备用服务器上重新应用。这种技术 丢失的数据数量是固定的。不能容忍在灾难中丢失数据的企业应该使用数据库或存储复制。
最高的数据库可用性应该使用全局群集来完成,它在多个互相连接的站点中调整数据库和应用的可用程度。
弹性数据库通过不同方法使用冗余拷贝。数据库可以通过额外的拷贝提高访问性能。存储数据库数据的磁盘可以被镜像来提高弹性。实时备份可以用来避免灾难和故 障。事务日志可以使导致数据错误的时间前滚。最后,完全的数据镜像可以在远端保存一份数据来避免灾难。高级的数据库管理器可以自行分发它们所管理的数据以 提高数据库弹性和性能。
Continue reading 【转】数据库备份与恢复技术
| 版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://heliy.blog.51cto.com/434250/261416 |
软件虚拟化主要的问题是性能和隔离性。Full Virtualization完全虚拟化技术可以提供较好的客户操作系统独立性,不过其性能不高,在不同的应用下,可以消耗掉主机10%~30%的资源。而OS Virtualization可以提供良好的性能,然而各个客户操作系统之间的独立性并不强。无论是何种软件方法,隔离性都是由Hypervisor软件提供的,过多的隔离必然会导致性能的下降。
这些问题主要跟x86设计时就没有考虑虚拟化有关。我们先来看看x86处理器的Privilege特权等级设计。
x86架构为了保护指令的运行,提供了指令的4个不同Privilege特权级别,术语称为Ring,从Ring 0~Ring 3。Ring 0的优先级最高,Ring 3最低。各个级别对可以运行的指令有所限制,例如,GDT,IDT,LDT,TSS等这些指令就只能运行于Privilege 0,也就是Ring 0。要注意Ring/Privilege级别和我们通常认知的进程在操作系统中的优先级并不同。 操作系统必须要运行一些Privilege 0的特权指令,因此Ring 0是被用于运行操作系统内核,Ring 1和Ring 2是用于操作系统服务,Ring 3则是用于应用程序。然而实际上并没有必要用完4个不同的等级,一般的操作系统实现都仅仅使用了两个等级,即Ring 0和Ring 3,如图所示:
也就是说,在一个常规的x86操作系统中,系统内核必须运行于Ring 0,而VMM软件以及其管理下的Guest OS却不能运行于Ring 0——因为那样就无法对所有虚拟机进行有效的管理,就像以往的协同式多任务操作系统(如,Windows 3.1)无法保证系统的稳健运行一样。在没有处理器辅助的虚拟化情况下,挑战就是采用Ring 0之外的等级来运行VMM (Virtual Machine Monitor,虚拟机监视器)或Hypervisor,以及Guest OS。 现在流行的解决方法是Ring Deprivileging(暂时译为特权等级下降),并具有两种选择:客户OS运行于Privilege 1(0/1/3模型),或者Privilege 3(0/3/3模型)。 无论是哪一种模型,客户OS都无法运行于Privilege 0,这样,如GDT,IDT,LDT,TSS这些特权指令就必须通过模拟的方式来运行,这会带来很明显的性能问题。特别是在负荷沉重、这些指令被大量执行的时候。 同时,这些特权指令是真正的“特权”,隔离不当可以严重威胁到其他客户OS,甚至主机OS。Ring Deprivileging技术使用IA32架构的Segment Limit(限制分段)和Paging(分页)来隔离VMM和Guest OS,不幸的是EM64T的64bit模式并不支持Segment Limit模式,要想运行64bit操作系统,就必须使用Paging模式。 对于虚拟化而言,使用Paging模式的一个致命之处是它不区分Privileg 0/1/2模式,因此客户机运行于Privileg 3就成为了必然(0/3/3模型),这样Paging模式才可以将主机OS和客户OS隔离开来,然而在同一个Privileg模式下的不同应用程序(如, 不同的虚拟机)是无法受到Privileg机构保护的,这就是目前IA32带来的隔离性问题,这个问题被称为Ring Compression。
IA32不支持VT,就无法虚拟64-bit客户操作系统 这个问题的实际表现是:VMware在不支持Intel VT的IA32架构CPU上无法虚拟64-bit客户操作系统,因为无法在客户OS之间安全地隔离。
为了解决IA32架构采用Ring等级带来的虚拟化难题,Intel VT就是为此而生!
作为一个芯片辅助(Chip-Assisted)的虚拟化技术,VT可以同时提升虚拟化效率和虚拟机的安全性。IA32上的VT技术,一般称之为VT-x,而在Itanium平台上的VT技术,被称之为VT-i。 VT-x介绍: VT-x将IA32的CU操作扩展为两个forms(窗体):VMX root operation(根虚拟化操作)和VMX non-root operation(非根虚拟化操作),VMX root operation设计来供给VMM/Hypervisor使用,其行为跟传统的IA32并无特别不同,而VMX non-root operation则是另一个处在VMM控制之下的IA32环境。所有的forms都能支持所有的四个Privileges levels,这样在VMX non-root operation环境下运行的虚拟机就能完全地利用Privilege 0等级。
两个世界:VMX non-root和VMX root 和一些文章认为的很不相同,VT同时为VMM和Guest OS提供了所有的Privilege运行等级,而不是只让它们分别占据一个等级:因为VMM和Guest OS运行于不同的两个forms。 由此,GDT、IDT、LDT、TSS等这些指令就能正常地运行于虚拟机内部了,而在以往,这些特权指令需要模拟运行。而VMM也能从模拟运行特权指令当中解放出来,这样既能解决Ring Aliasing问题(软件运行的实际Ring与设计运行的Ring不相同带来的问题),又能解决Ring Compression问题,从而大大地提升运行效率。Ring Compression问题的解决,也就解决了64bit客户操作系统的运行问题。 为了建立这种两个虚拟化窗体的架构,VT-x设计了一个Virtual-Machine Control Structure(VMCS,虚拟机控制结构)的数据结构,包括了Guest-State Area(客户状态区)和Host-State Area(主机状态区),用来保存虚拟机以及主机的各种状态参数,并提供了VM entry和VM exit两种操作在虚拟机与VMM之间切换,用户可以通过在VMCS的VM-execution control fields里面指定在执行何种指令/发生何种事件的时候,VMX non-root operation环境下的虚拟机就执行VM exit,从而让VMM获得控制权,因此VT-x解决了虚拟机的隔离问题,又解决了性能问题。 |
Continue reading 【转】虚拟化os in os中ring与vm关系
传统虚拟化软件台为 Hypervisor Type 2(基于Host OS 的虚拟化)
如Virtual PC,VMware GSX Server .VMware workstation ,QMEU.缺点则是性能不佳.并且资源配置性不好.
主要讨论的虚拟化技术以Hypervisor Type 1 (底层虚拟化技术)为主,所谓的Hypervisor Type 1 ,是指虚拟化主控平台与作业系统结合为一的结构.好处是能够100%控制硬件并且获得最佳性能.尽管Hypervisor Type 1 性能佳.但是下面应用用途不能应用.
1.没有当地终端显示,所以不能使用需要当地终端 单机多OS用途.(比如说玩游戏)
2.大部份Hypervisor Type 1 对本地 USB设备、 声卡 等硬件支持不佳
Hypervisor Type 1 又分为全虚拟化跟半虚拟化
Ring
还未解说 CPU 虚拟化之前先解释一个东西就是 Ring(环),
在 Intel CPU 的系统运行下可以区分成 Ring 0,Ring 1,Ring 2 和 Ring 3.
Ring 0 拥有最高的权限,通常是由系统核心才会有 Ring0 的权限,Ring 0 可以直接和硬件沟通读入 IO,CPU,Memory 与周边设备
.其次是 Ring 1,以此类推.一般 Kernel,driver 会存在 Ring 0.
一般 AP 存在 Ring 3,一般的作业系统也只运用到 Ring 0 和 Ring3.
采取这种方式的优点是一般运行的程序没有办法直接与硬件沟通,所以不会有像 Window 3.1 时一样的状况发生,一个程序就能把整个系统摧毁(Crash)掉
VMM(Virtual MachineMonitor)
一个机台要能同时执行很多作业系统时不能像是传统的方式让OS 的核心存放在Ring0.取而代之的就是VMM((Virtual Machine Monitor)也可以称作Hybervisor.也为了虚拟化的资源配置管理,所以必须有一个东西来管理所有虚拟化的作业系统(GuestOS).也就是所谓的 VMM(VirtualMachine Monitor).
此时的 VMM 主要工作为
‧仿真出一个完整的硬件环境给每一个 GuestOS
‧ 配置硬件支持给每一个 GuestOS
‧ 每一个 GuestOS 都是独立出来不会被彼此影响的
1 - FullVirtualization 使用的是 -Binary Translation
也正因为 IntelCPU 结构的关系,不少的CPU 指令必须执行在Ring 0 底下,而传统的作业系统核心也必须放在Ring 0 让他们能直接访问硬件.所以一开始的虚拟化几乎不能在X86的系统上使用.
但是VMware 使用了一种方式让虚拟化能够执行在X86 的系统上.他们使用一种称为Binary Translation 加上direct execution 的方式,所谓的Binary translation就是将原本要执行不能虚拟化的指令(nonvirtualizableinstructions)VMM 会转换成另一种语法,然后再交由VMM 去执行.就像是Guest OS 要将数据写入硬盘中,但是其实Guest OS的硬盘可能只是硬盘中的一块磁盘块(partition)或是文件(Loopfile),所以 VMM会把他的请求转换成另一种方式再来向硬件提出要求.而不再是用原本的指令去执行了.至於direct execution 是一般性的指令不需要在Ring0 才能执行就直接可以向硬件提出请求.
这样的缺点是会造成效率的低落,但好处是虚拟出来的作业系统(GuestOS)并不知道有 VMM的存在,他会以为自己拥有整个机器,而且虚拟出来的作业系统(GuestOS)也不需要修改核心去配合 VMM.加上VMM 会去虚拟整个机器包括了虚拟化的BIOS,devices 和memory的管理,.而且每一个虚拟出来的作业系统(GuestOS)都是独立而且安全性高不会受到其它虚拟出来的作业系统(GuestOS)影响.
当前采用这种方式的有 VMware’s全系列virtualizationproducts 和 MicrosoftVirtual Server.
2 -另一种需要修改作业系统的核心才能支持-Paravirtualization
刚才有说明为什么在一般x86系统下没有办法做虚拟化,大部分的原因是不能虚拟化的指令(nonvirtualizableinstructions)必须直接在 Ring0 执行.但是Paravirtualization使用了另一种方式,修改虚拟化作业系统(GuestOS)的核心,让虚拟的作业系统(GuestOS)可以直接将不能虚拟化的指令(nonvirtualizableinstructions)自动转换成 VMM可以执行的指令(hypercall),再由VMM 去向硬件提出请求.所以像是(Windows2000/XP)不能去修改它的核心(Microsoft也不愿意让别人来修改它的核心),所以无缘使用Paravirtualization.而所谓的hypercall 就像是 OSkernel 的 syscall 只不过hypercall 是针对hypvisor(VMM)的.
当前采用这种方式的有 Xen,KVM,HyperV
3 -Paravirtualization + Intel VT 或者AMD-V
在没有VT 的时代 VMM是直接装入在 Ring 0里面,Dom0 的kernel 则是被放在Ring1(Dom0 是第一个在Xen 底下运行的虚拟机器).后来产生出的DomU 也是存放在Ring1(需为Para-Virtualized,没有VT 的支持 Xen不支持 full-Virtualized).不过一般的AP 还是运行在 Ring3.也正因为如此 Para-Mode的 Guest OS 必须知道VMM 的存在.此时是不支持Full-Mode 的.后来有了VT 这一项技术.VMM和GuestOS(Para/Full-Mode)都可以直接执行在 Ring0运行.不过 VMM是存在比 Guest OS还要低的一层.
RootMode Privilege Levels.不能虚拟化的指令(nonvirtualizableinstructions)会自动被 hypervisor截取不需要再经过 binarytranslation 或 paravirtualization的模式转换.
Continue reading 浅谈Hypervisor Type 1
SGA的区域信息
SGA(system global area)系统全局区跟一些必须的后台进程合进来称为实例(Instance).说它是全局区是包含了全局变量和数据结构,是系统区是包含了进入整个Oracle Instance的数据结构而不是特定的进程结构。
SGA区域:
SGA大概包括下面四到五种区域:
The fixed area;
The variable area;
The database blocks area;
The log buffer;
The instance lock database(for parallel server instances)----OPS&RAC。
根据内存的大小,我们可以把The fixed area和The log buffer设为很小。
The fixed area:
SGA中的The fixed area包含了数千个原子变量,以及如latches和指向SGA中其它区域的pointers(指针)等小的数据结构.通过对fixed table内表X$KSMFSV查询(如下)可以获得这些变量的名字,变量类型,大小和在内存中的地址.
SQL> select ksmfsnam, ksmfstyp, ksmfssiz, ksmfsadr
2> from x$ksmfsv;
这些SGA变量的名字是隐藏的而且几乎完全不需要去知道.但是我们可以通过结合fixed table内表X$KSMMEM获得这些变量的值或者检查它们所指向的数据结构.
SQL>select a.ksmmmval from x$ksmmem a
where addr=(select addr from x$ksmfsv where ksmfsnam=’kcrfal_’);
SGA中的fixed area的每个组成部分的大小是固定的.也就是说它们是不依靠于其它的初始化参数的设置来进行调整的.fixed area中的所以组成部分的大小相加就是fixed area的大小。
The variable area:
SGA中的the variable area是由large pool和shared pool组成的.large pool的内存大小是动态分配的,而shared pool的内存大小即包含了动态管理的内存又包含了永久性的(已经分配的)内存.实际上,初始化参数shared_pool_size的大小设置是指定 shared pool中动态分配的那部分内存的一个大概的SIZES而不是整个shared pool的SIZES
Continue reading SGA的区域信息--数据库调优

