好文章,转载以备份。原文出自这里。
session 的管理對網站應用程式非常的重要,不適當或不夠嚴謹的管理也會造成安全上的問題,以下針對 session 管理相關的安全問題分項探討。
藉由 session 限制與維護使用者的行為是網路安全很重要的一環。大多數的人會使用網站應用程式框架內建的 session 管理,有些人會使用 Perl CGI。網站開發者應盡量避免自行開發 session 管理,因為自行開發常常會藏有許多漏洞,而框架內建的 session 管理經過多次測試與修復相對上較為安全。此外這些框架會持續維護其安全性,因此要確保做好更新與安裝修補程式的動作。
密碼強度
Session handler 的一個重點是 session token 或 session ID 的密碼強度,Session handler 產生的 token 必須是無法預知並且長度夠長讓人無法猜測的到。Session tokens 必須每個使用者都不同、無法預測、能抵抗反向工程。
適當的 Key Space
一個加密的演算法也可能因為 Key space 不夠大造成攻擊者使用暴力解來取得內容。因此 token 的 Key space 必須足夠大來防禦暴力攻擊法,並且注意電腦計算能力與寬頻能力已隨著時代進步。
Session Identifier(session ID)
Session Identifier 應該使用最大可用的 character set,如果一個 session ID 要由 8 characters of 7 bits 組成,有效密鑰長度為56位,但如果使用的 character set 只有整數可用 4 bits表示,有效密鑰長度就只有32位。因此一個好的 session ID 應盡量使用越多 characters 越好,但一些特殊字元有轉譯的麻煩,所以大多的 frameworks 採用 A-Z 和 0-9 有些還添加了小寫 a-z。
所有由客戶端傳來的資料都必須經過編碼和驗證,許多 frameworks 會驗證和編碼從 GET 和 POST 而來的 input,但未充分編碼從客戶端 cookie 傳來的 session ID 值。下面的 ESAPI code 片段使用 ESAPI 中的 method 來驗證 session ID 的值:
public String getRequestedSessionId() {
String id = request.getRequestedSessionId();
String clean = " ";
try {
clean = ESAPI.validator().getValidInput( "Requested cookie: " + id, id, "HTTPJSESSIONID", 50, false );
} catch (ValidationException e ) {
// already logged
}
return clean;
}
根據業務需求和安全性的考量,session 必須有一有限的壽命,在一定時間後過期。網站應用程式必須將靜止一段時間的 session 設為過期,刪除此 session 並一併更改 session cookie 的內容。
當使用者登出後網站應用程式需讓 session 無效或者移除此 session,並且如果隨後有別的使用者登入必須取得不同的 session ID。要做到這樣的機制,當使用者 logout 時必須改寫 session cookies 註明已過期並銷毀 session。以下是 ESAPI code 的例子:
public void logout() {
ESAPI.httpUtilities().killCookie( ESAPI.currentRequest(), ESAPI.currentResponse(), HTTPUtilities.REMEMBER_TOKEN_COOKIE_NAME );
HttpSession session = ESAPI.currentRequest().getSession(false);
if (session != null) {
session.invalidate();
}
ESAPI.httpUtilities().killCookie(ESAPI.currentRequest(), ESAPI.currentResponse(), "JSESSIONID");
loggedIn = false;
logger.info(Logger.SECURITY, "Logout successful" );
ESAPI.authenticator().setCurrentUser(User.ANONYMOUS);
}
public void killCookie(HttpServletRequest request, HttpServletResponse response, String name) {
String path = "//";
String domain=" ";
Cookie cookie = ESAPI.httpUtilities().getCookie(request, name);
if ( cookie != null ) {
path = cookie.getPath();
domain = cookie.getDomain();
}
SafeResponse safeResponse = new SafeResponse( response );
safeResponse.addCookie(name, "deleted", 0, domain, path);
}
對於高安全性網站,網站應用程式在處理重要的程序之前,或是經過某一段時間和幾次 requests 後,必須重新產生 session ID。中等或低等的網站,在使用者權限改變時也應該重新產生 session ID ,例如從訪客變成登入的會員或從登入者變成管理者。以下是 ESAPI code 重新產生 Session ID 的例子:
public HttpSession changeSessionIdentifier(HttpServletRequest request) throws AuthenticationException {
// get the current session
HttpSession session = request.getSession();
// make a copy of the session content
Map temp = new HashMap();
Enumeration e = session.getAttributeNames();
while (e != null && e.hasMoreElements()) {
String name = (String) e.nextElement();
Object value = session.getAttribute(name);
temp.put(name, value);
}
// kill the old session and create a new one
session.invalidate();
HttpSession newSession = request.getSession();
// copy back the session content
Iterator i = temp.entrySet().iterator();
while (i.hasNext()) {
Map.Entry entry = (Map.Entry) i.next();
newSession.setAttribute((String) entry.getKey(), entry.getValue());
}
return newSession;
}
如果可以的話,網站應用程式應該都以 HTTPS 的方式傳輸。如果無法,至少包含敏感性資料的頁面或處理程序要使用 HTTPS; 如果 HTTPS 無法保護整個網站的 session,在 HTTPS 傳輸時必須搭配 session ID,將此 session ID 和網站伺服器的 session 做配對檢查。
如果必須藉由 URL 參數來傳遞 session ID 時,必須使用 POST。如果 cookies 用來儲存並由 HTTPS 傳送 session ID 時,必須被設為”安全”這樣就不會經過 non-SSL 的管道。
網站應用程式必須提供登出的機制,並確保登出後此 session 過期和被銷毀。
PS:
ESAPI的站点都访问不了?
Continue reading 【转】安全的session管理
http://book.51cto.com/art/201004/196350.htm
Lustre[5]文件系统是一个基于对象存储的分布式文件系统,并且与PVFS一样,Lustre也是一个开源项目。Lustre项目与1999 年在Carnegie Mellon University启动,现在已经发展成为应用最广泛的分布式文件系统。Lustre已经运行在当今世界上最快的集群系统里面,比如Bule Gene,Red Storm等计算机系统,用来进行核武器相关的模拟,以及分子动力学模拟等等非常关键的领域。
Lustre的组织结构在其官方文档中有详细的介绍,如图 5.5所示,Lustre集群组件包含了MDS(元数据服务器)、MDT(元数据存储节点)、OSS(对象存储服务器)、OST(对象存储节点)、Client(客户端),以及连接这些组件的高速网络。
1)元数据存储与管理。MDS负责管理元数据,提供一个全局的命名空间,Client可以通过MDS读取到保存于MDT之上的元数据。在 Lustre中MDS可以有2个,采用了Active-Standby的容错机制,当其中一个MDS不能正常工作时,另外一个后备MDS可以启动服务。 MDT只能有1个,不同MDS之间共享访问同一个MDT。
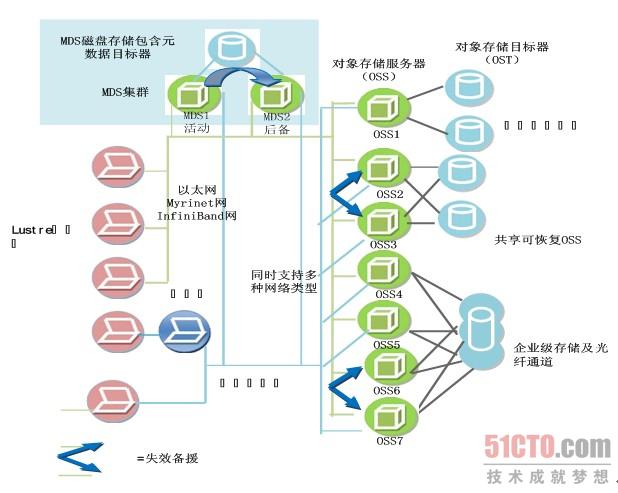
(点击查看大图)图 5.5 Lustre集群架构
2)文件数据存储与管理。OSS负载提供I/O服务,接受并服务来自网络的请求。通过OSS,可以访问到保存在OST上的文件数据。一个OSS对应 2到8个OST,其存储空间可以高达8TB。OST上的文件数据是以分条的形式保存的,文件的分条可以在一个OSS之中,也可以保存在多个OSS中。 Lustre的特色之一是其数据是基于对象的职能存储的,跟传统的基于块的存储方式有所不同。
3)Lustre系统访问入口。Lustre通过Client端来访问系统,Client为挂载了Lustre文件系统的任意节点。Client提供了Linux下VFS(虚拟文件系统)与Lustre系统之间的接口,通过Client,用户可访问操作Lustre系统中的文件。
Lustre集群中的各个节点通过高速的以太网或Quadrics Elan、Myrinet等多种网络连接起来。
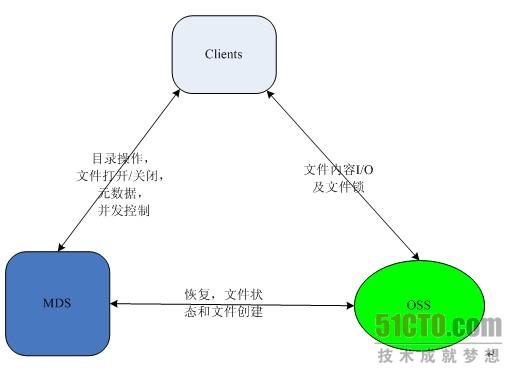
(点击查看大图)图 5.6 Lustre文件系统架构
在Lustre官方手册中给出了Lustre文件系统的架构,如图 5.6所示。Lustre文件系统也是一个3方架构,包括了MDS、OSS和Client这3个模块。文件的打开(open)和关闭(close)、元数据以及并发访问控制都在Client和MDS之间进行;文件I/O操作以及文件锁在OSS和Client之间进行;文件备份,文件状态获取以及文件创建等在MDS和OSS之间进行。目前Lustre文件系统最多可以支持100000个Client,1000个OSS 和2个MDS节点。
同PVFS类似,Lustre系统中既可以运行一个功能模块,也可以同时运行2个或3个功能模块,这取决于系统的规模。不过Lustre一般运行于高性能计算机系统之上,为了提高Lustre文件系统的性能,通常MDS、OSS和Client是分开运行在Lustre不同的节点之上的。
实验与应用已经证明,Lustre文件系统的性能和可扩展性都不错。不仅如此,Lustre文件系统还拥有基于对象的智能化存储、安全的认证机制、比较完善的容错机制等优点,值得注意的是,Lustre还实现了部分文件锁。Lustre确保从不同Client端挂载的Lustre文件系统看到的都是一个单一的、同步的、一致的命名空间。由于Lustre部分锁机制的存在,多个Client端在同一时间点可以写同一文件的不同区域,其它Client则可以读取文件的其它区域。由于部分文件锁的存在,极大的提高了多用户对同一文件进行并发访问时系统的性能,对同一文件并发访问这在像数据库这种应用里是极为常见的。
相对于PVFS,Lustre的可用性和扩展性以及性能上都有较大的提高。然而,Lustre需要特殊设备的支持,并且Lustre目前还没实现 MDS的集群管理,虽然相比PVFS的单MDS,Lustre的双MDS在可用性上还是提高不少,但是当系统达到一定的规模之后,MDS还是很有可能成为 Lustre系统中的瓶颈。
Continue reading 【转】Lustre 介绍
作者 Srini Penchikala 译者 王丽娟 发布于 2010年11月29日
Ehcache的BigMemory提供了一个进程内的堆外缓存,用来存储应用相关的大批量数据。Terracotta上周发布了BigMemory模块的GA版本,该模块支持Ehcache企业版。BigMemory是Ehcache标准API的一部分,为cache定义两个新属性(overflowToOffHeap和maxMemoryOffHeap)就可以使用了,代码片段如下所示:
<cache name="sample-offheap-cache"
maxElementsInMemory="10000"
eternal="true"
memoryStoreEvictionPolicy="LRU"
overflowToOffHeap="true"
maxMemoryOffHeap="1G"/>BigMemory在内存存储策略上有别于传统的缓存解决方案。它不把数据存储在Java堆里,从而避免了JVM的GC问题。BigMemory这种特别的存储被称为堆外(Off-Heap)存储。传统的缓存解决方案为了规避这些问题,都将数据分布在缓存节点组成的集群上。BigMemory提供了一种新的架构选择方案,允许应用运行在堆小于1G的JVM上,利用堆外的内存来加快数据访问的速度。
InfoQ有幸采访了Terracotta的CTO Ari Zilka,请他谈了Ehcache框架里的BigMemory新特性、BigMemory有助于应用性能提升的用例场景,以及BigMemory的局限性。
InfoQ:为Ehcache框架添加BigMemory特性的主要动机是什么?
主要动机是为了解决我们在Terracotta服务器里遇到的GC问题。服务器里的GC会引起响应时间和大规模GC事件出现变化,可能会致使(一级缓存L1的)缓存客户端故障转移到备份的Terracotta服务器上去。我们意识到这个解决方案的好处后就立即扩大了它的应用范围,包括为独立Ehcache追加一个内存存储,这个内存存储后来就发展成了BigMemory——Ehcache企业版的一个插件。
InfoQ:BigMemory堆外存储提供的方式能避免Java GC的复杂性,你能谈一谈实现的具体细节么?
BigMemory把缓存对象存储在Java堆之外,但仍然在操作系统的Java进程里。所以它仍然是个进程内的缓存,具备所有与此相关的高性能,但它不使用堆,这样就可以给应用配置很小的堆空间,从而避免GC问题。BigMemory使用了JDK 1.4引入的DirectByteBuffers。所有的Java实现都可以运行BigMemory,所以任何人都可以使用BigMemory,而不用更换JDK。
操作系统内存管理器的功能差不多就要完成了。届时我们会在放入数据时分配内存、移除数据时释放内存,我们能做这些事情是因为BigMemory是个缓存,而不是一般用途的Java程序。DirectByteBuffers分配内存很慢,但用起来非常快。所以我们会在启动的时候就从操作系统获取所有需要的内存。
BigMemory的关键之处在于,怎样判断某个对象不再被使用、关联的内存被释放了,这也是很多人一开始最难理解的地方。对缓存来说,这其实非常简单。Map主要涉及put、get和remove操作。我们在放入数据的时候分配内存(malloc),移除数据的时候释放内存(free)。我们实现了一个内存管理器,它使用的是很好理解的计算机科学算法,还有我们专门为此实现的增强。
在被问及BigMemory什么情况下能提升应用性能时(从只读、经常读、读写操作来说),Ari回答说,在“90%读/10%写”的常见情况和“50%读/50%写”的写操作过多的情况下,他们都见过比较好的性能结果。这是因为缓存是进程内的。只读操作会受到分布式缓存的影响。读取活跃数据集要比读取其它数据快很多,那些不活跃的数据必须通过网络获取。
InfoQ:BigMemory解决方案有什么局限性?
鉴于BigMemory是纯Java的、进程内的,而且和常见的JVM、容器兼容,所以它没有明显的局限性。我们找到的最大的内存盒有384GB内存,我们在上面测试的结果显示,在BigMemory始终有350GB内存的空闲情况下,性能都是线性的,没有明显的增长。
我们要向用户强调的限制只有一个,那就是使用堆外存储的话,放置在BigMemory中的对象必须进行序列化。对通常就存储在缓存里的那些数据来说,这并不是什么问题。
一旦对象被序列化,在返回Java堆的时候必需反序列化才可以使用。这确实是一笔性能开销。因此在没有GC的时候,BigMemory会比堆内存储慢。但BigMemory还是要比底层可用的存储快很多,不论是本地磁盘、网络存储,还是RDBMS等原本记录数据的系统。
还应指出的是,序列化/反序列化的性能开销远没有很多用户想象的那么大。BigMemory已经针对字节缓冲区做了优化,本身也包含一些优化机制,可以对使用标准Java序列化的对象进行优化。举例来说,测试版发布之后添加的那些优化机制能使复杂Java对象的性能提升两倍,使byte数组的性能提升四倍。Terracotta Server Array正是用byte数组存储数据的。用自定义的序列化则能进一步减少性能开销。
InfoQ问Ari,架构师和开发人员在应用中使用BigMemory时应该注意哪些最佳实践和问题。Ari回答说,任何成功的商业应用都要处理伸缩性问题。缓存是最稳妥、最容易实现的解决方案之一。现在比较新颖的是,不用非得引入缓存集群了。
最好的做法就是用新眼光来审视一下你的性能架构,看你能否从大型的进程内缓存获益。BigMemory可以让架构师对服务器和进程密度进行优化,以满足特定的需求,而不用受制于Java的局限性。
最大的问题则是大多数人已经针对Java本身的局限性做了优化。比如说,大多数Ehcache用户会运行32位的JVM。根据OS的不同,32位 Java的地址空间会是2到4GB不等。所以这些用户在用Java时就放弃了使用很多内存。应用目前可能都运行在RAM很小的硬件上。所以用户要是想使用 BigMemory来运行100GB的进程内缓存,可能就意味着要更换新的硬件,即便现在硬件很便宜。
InfoQ:Ehcache框架以后的路线图是怎样的?BigMemory有什么特殊的么?
我们正在开发Ehcache和Terracotta的下一个版本(代码以澳大利亚弗里曼特尔的别称Freo命名),计划本月发布测试版。我们计划在这个版本中添加一系列功能特性和性能增强。比如Ehcache Search,它能让Ehcache用户在缓存里进行搜索,就像使用数据库一样。Ehcache Search已经发布了测试版,文档也已经全部可用了。
至于BigMemory,我们还在继续提升性能,同时会增加一系列比较实用的增强,例如提供更多的工具,帮助人们更好地理解最适合他们用例的设置。
查看英文原文:Ari Zilka on Ehcache BigMemory
---------------------------------------
PS:
另外一篇:http://www.infoq.com/interviews/zilka-bigmemory
Terracotta是一款由美国Terracotta公司开发的著名开源Java集群平台。
参见:http://blog.csdn.net/ansonchan/article/details/1873001
这有个人问的问题:
请教老马,这个产品在当前有没有成功又稳定的项目中使用的经验,由于该项目中使用大量自旋竞争锁操作,导致cpu偏高,所以带来的稳定性一直是个问题
问的有水平。哪些人用了?
Continue reading 【转】Ari Zilka谈Ehcache的进程内堆外缓存BigMemory
教科书上说,并口一次传多位,速度快。但是实际上为什么SATA硬盘比IDE/PATA硬盘要快?
两方面的原因:
1:数据同步问题
网上有个例子很形象:
并口啊
举个很切合实际的例子
有10个人走一个门,如果门大可以同时通过,门小要单一同过
大门=并口,小门=串口
10个人排一列不容易跟丢,说明串口适合远距离
10个人排一行,可能会走丢,适合近距离,但是走大门能一下通过,速度快,并口的特点
这是说多个位同时传送,长时间传送后,有些位先到,有些位后到,这就要取决于最后到的那位了,还要加上数据校验的时间(比特流传输的速度必须减缓以纠正错误)。
2:干扰问题
10个人并排走,这个人把那个人推一下,几个人交头接耳说笑话,-----这说的是互相之间的干扰。
目前并行总线没有能解决好数据干扰问题,所以还要校错。
对于长距离传输,问题一影响较大,对于硬盘,问题二影响较大。
Continue reading 串口为什么比并口快以及IDE容量





{kind=link}