ObjectName = Catalina:type=Host,host=localhost:
停止启动服务器
Catalina:j2eeType=WebModule,name=…
停止启动web程序
Catalina:type=Service,serviceName=Catalina
这个可以停止整个Tomcat,但是停止了这个MBean也就消失了,那就谈不上用它来启动了
Continue reading Tomcat JMX操作
这个问题我还是转载一下这位律师的文章:
网络转载与合理使用
来源:赵虎律师博客 作者:赵虎
北京市汉卓律师事务所 赵虎
这个话题的引起是因为微博上一个朋友的问题:中国新闻网转载了《重庆晨报》的一篇文章《韩寒首度承认当爹 谈郭敬明:人各有志,不能强求》。《重庆晨报》上的该篇文章本人没有看过,但是只看转载的这篇文章至少可以发现两个问题:
1、网络是否可以任意转载报纸的文章?
2、转载的文章除了注明来源是否还需要写明作者?
我们知道作品是有著作权的,一般情况下使用他人作品必须经过著作权人的许可,否则构成侵犯著作权。那么为什么报纸、网络、电台、电视台可以转载、转播其他报纸、网络、电台、电视台的作品呢?这是由于我国著作权法规定了一个著作权保护的例外制度:合理使用制度。
合理使用制度即在法律规定的条件下,他人使用作品可以不经过著作权人的许可,也不向其支付报酬。合理使用制度设立的目的是为了保护公共利益,在确保不损害著作权人的根本利益的前提之下促进文化的传播、信息的流通。
一般来说,合理使用制度遵循以下四个原则:
1、仅限于已经发表的作品;
2、非商业性使用;
3、使用程度恰当,不超过必要程度;
4、其结果不会损害著作权人的根本利益。
合理使用比较常见的有:写书评、影评文章时引用其中的内容;转播其他电视台的新闻报道;义演时使用他人的作品(歌曲、小品)等。我国《著作权法》第二十二条规定了合理使用制度。该条第四款是关于媒体之间的转载、转播的规定:“报纸、期刊、广播电台、电视台等媒体刊登或者播放其他报纸、期刊、广播电台、电视台等媒体已经发表的关于政治、经济、宗教问题的时事性文章,但作者声明不许刊登、播放的除外。”根据该条规定,在符合以下条件下可以进行转播、转载:
1、发生在报纸、期刊、广播电台、电视台等媒体之间;一般认为,只有在同一种媒体之间才可以转载、转播,比如:报纸与报纸之间、广播电台与广播电台之间、电视台与电视台之间等。
2、主题仅限于政治、经济、宗教;其他类型主题不能适用该规定。
3、限于时事性文章;时事性,就要求是当前发生的事情,对历史或者过去事件的分析、评论不在其内。
4、已经发表;未发表的文章不适用该规定。
5、作者声明不许刊登、播放的除外;作者有权做出这样的声明。
6、应当指明作者的姓名、作品名称,并不得侵犯著作权人依法享有的其他权利。即用别人的东西不能损害别人的利益。
我们可以看到,这里面没有关于网络的规定。可能是因为著作权法制定和修订的时候,网络还没有像今天这么重要,也没有出现这么多的问题。在2006年国务院公布的《信息网络传播权保护条例》第六条规定了网络上的合理使用,其中第七项规定:“向公众提供在信息网络上已经发表的关于政治、经济问题的时事性文章”。可见,网络上转播、转载需要符合以下条件:
1、仅限于在网络上已经发表的文章,即只发生在网络与网络之间,不能发生在网络与报纸、期刊、电视台、广播电台之间;
2、主题限于政治、经济,和报纸、期刊等的合理使用相比,少了宗教;
其他跟报纸、期刊等的合理使用是一样的。
另外,有的媒体在转载的时候还对文章进行了删减、修改。转载时可否对文章进行删减与修改,这个问题也是有争论的。如果是合理使用(不通知、不付报酬),本文的意见是不可以。因为法律规定了不能损害著作权人其他权利,如果没有经过著作权人同意就对转载文章进行删减、修改则会损害著作权人的修改权和保护作品完整权,违反了法律的规定。当然,如果不是适用合理使用,而是适用法定许可制度,即支付著作权人报酬,可以刊登文摘或者资料。
以上是因为这个博友的问题引起的思索,具体到这篇文章,发现至少有这么几个不符合法律规定的地方:
1、网络转载报纸文章,不属于法律规定范围;
2、娱乐性文章而非政治、经济类文章,超出法律规定;
3、非时事性文章;
4、没有写明作者。
通过这个分析我们可以发现,现在不符合法律规定的情况太多了。但是这种违法情况的大量存在不能说明那样就是合法的,而是因为目前我们对于知识产权违法的容忍度比较高,权利人保护自己知识产权的意识还不高,知识还不具备。从尊重创造、遵守法律规定的角度来说,当我们进行转载的时候,也应该思索一下是否超越了法律的界限
这个话题的引起是因为微博上一个朋友的问题:中国新闻网转载了《重庆晨报》的一篇文章《韩寒首度承认当爹 谈郭敬明:人各有志,不能强求》。《重庆晨报》上的该篇文章本人没有看过,但是只看转载的这篇文章至少可以发现两个问题:
1、网络是否可以任意转载报纸的文章?
2、转载的文章除了注明来源是否还需要写明作者?
我们知道作品是有著作权的,一般情况下使用他人作品必须经过著作权人的许可,否则构成侵犯著作权。那么为什么报纸、网络、电台、电视台可以转载、转播其他报纸、网络、电台、电视台的作品呢?这是由于我国著作权法规定了一个著作权保护的例外制度:合理使用制度。
合理使用制度即在法律规定的条件下,他人使用作品可以不经过著作权人的许可,也不向其支付报酬。合理使用制度设立的目的是为了保护公共利益,在确保不损害著作权人的根本利益的前提之下促进文化的传播、信息的流通。
一般来说,合理使用制度遵循以下四个原则:
1、仅限于已经发表的作品;
2、非商业性使用;
3、使用程度恰当,不超过必要程度;
4、其结果不会损害著作权人的根本利益。
合理使用比较常见的有:写书评、影评文章时引用其中的内容;转播其他电视台的新闻报道;义演时使用他人的作品(歌曲、小品)等。我国《著作权法》第二十二条规定了合理使用制度。该条第四款是关于媒体之间的转载、转播的规定:“报纸、期刊、广播电台、电视台等媒体刊登或者播放其他报纸、期刊、广播电台、电视台等媒体已经发表的关于政治、经济、宗教问题的时事性文章,但作者声明不许刊登、播放的除外。”根据该条规定,在符合以下条件下可以进行转播、转载:
1、发生在报纸、期刊、广播电台、电视台等媒体之间;一般认为,只有在同一种媒体之间才可以转载、转播,比如:报纸与报纸之间、广播电台与广播电台之间、电视台与电视台之间等。
2、主题仅限于政治、经济、宗教;其他类型主题不能适用该规定。
3、限于时事性文章;时事性,就要求是当前发生的事情,对历史或者过去事件的分析、评论不在其内。
4、已经发表;未发表的文章不适用该规定。
5、作者声明不许刊登、播放的除外;作者有权做出这样的声明。
6、应当指明作者的姓名、作品名称,并不得侵犯著作权人依法享有的其他权利。即用别人的东西不能损害别人的利益。
我们可以看到,这里面没有关于网络的规定。可能是因为著作权法制定和修订的时候,网络还没有像今天这么重要,也没有出现这么多的问题。在2006年国务院公布的《信息网络传播权保护条例》第六条规定了网络上的合理使用,其中第七项规定:“向公众提供在信息网络上已经发表的关于政治、经济问题的时事性文章”。可见,网络上转播、转载需要符合以下条件:
1、仅限于在网络上已经发表的文章,即只发生在网络与网络之间,不能发生在网络与报纸、期刊、电视台、广播电台之间;
2、主题限于政治、经济,和报纸、期刊等的合理使用相比,少了宗教;
3、其他跟报纸、期刊等的合理使用是一样的。
另外,有的媒体在转载的时候还对文章进行了删减、修改。转载时可否对文章进行删减与修改,这个问题也是有争论的。如果是合理使用(不通知、不付报酬),本文的意见是不可以。因为法律规定了不能损害著作权人其他权利,如果没有经过著作权人同意就对转载文章进行删减、修改则会损害著作权人的修改权和保护作品完整权,违反了法律的规定。当然,如果不是适用合理使用,而是适用法定许可制度,即支付著作权人报酬,可以刊登文摘或者资料。
以上是因为这个博友的问题引起的思索,具体到这篇文章,发现至少有这么几个不符合法律规定的地方:
1、网络转载报纸文章,不属于法律规定范围;
2、娱乐性文章而非政治、经济类文章,超出法律规定;
3、非时事性文章;
4、没有写明作者。
通过这个分析我们可以发现,现在不符合法律规定的情况太多了。但是这种违法情况的大量存在不能说明那样就是合法的,而是因为目前我们对于知识产权违法的容忍度比较高,权利人保护自己知识产权的意识还不高,知识还不具备。从尊重创造、遵守法律规定的角度来说,当我们进行转载的时候,也应该思索一下是否超越了法律的界限。
再看看这个案例,http://www.chinawriter.com.cn/zjqy/2011/2011-07-04/99558.html
所以,转载别人的文章
1: 先要看看 文章是否说明不允许转载,如果说了,那就不能。如果说未经允许不能转载,那你就要向作者讨得一份允许文件了。
2:不管是引用片段还是整篇转载,都要注明原文作者及出处。
3:至于原作者是否有权索取报酬,这个我就说不清楚了,这个要看具体情况,那要法官来判!
Continue reading 网络文章转载涉及到的著作权法问题
IBM dev文章 http://www.ibm.com/developerworks/cn/java/underhood/index.html
画的图很明了,文章不错。
网络
如果将话题深入一点,将发现许多都值得探讨,但又很简单。我们简单的计算器服务器设计成被远程调用,CORBA 专门确保让我们不必担心客户机环境和服务器环境之间的差异。客户机对服务器的远程调用是根据远程过程调用 (RPC) 协议生成的,该协议自 20 世纪 80 年代就存在。RPC 是由各种通信模型经过多年测试得到的结果 -- 这是已经在产品环境中测试过的可靠且真实的技术。我们现在使用的 CORBA 模型就基于该模型。
图 1. 网络

回页首
可互操作对象引用 (IOR)
让我们跟踪方法调用。客户机必须首先获得计算器的实例。它通过使用 calculatorHelper.java narrow() 方法来达到这一目的。 ior 是可互操作对象引用 (IOR) 的字符串表示,是从文件 calcref.ior 中检索到的。这个文件是由服务器写的,以便客户机可以定位并连接到它。对 orb string_to_object() 的方法调用只取得 ior 字符串,并将它转换成对象引用。以下是客户机中的代码, SimpleCalcClient.java :
calculator calc = calculatorHelper.narrow(orb.string_to_object(ior));
System.out.println("Calling into the server");
System.out.println( calc.add(2,3) );
IOR 中有什么?IOR 是一个数据结构,它提供了关于类型、协议支持和可用 ORB 服务的信息。ORB 创建、使用并维护该 IOR。许多 ORB 供应商提供了一个实用程序来窥视 IOR 的内部。OOC (Object Oriented Concepts, Inc.) 的 Orbacus(请参阅 参考资料) 附带 IORDump.exe,如果您使用 Visibroker,它为您提供了 PrintIOR.exe。也有一些网站为您分析 IOR;可在 Xerox Parc 站点(请参阅 参考资料)上找到我使用的一个实用程序。因为正在使用 Orbacus,我将对在 SimpleCalc 示例中创建的 IOR 运行 IORDump。得到以下输出:
C:\_work\corbasem\_sources\calcsimpl>iordump -f calcref.ior
IOR #1:
byteorder: big endian
type_id: IDL:corbasem/gen/calcsimpl/calculator:1.0
IIOP profile #1:
iiop_version: 1.2host: 192.168.0.10
port: 4545
object_key: (36)
171 172 171 49 57 54 49 48 "1/2 1/4 1/2 9610"
48 53 56 49 54 0 95 82 "05816._R"
111 111 116 80 79 65 0 0 "ootPOA.."
202 254 186 190 57 71 200 248 ".?.9G.."
0 0 0 0 "...."
Native char codeset:
"ISO 8859-1:1987; Latin Alphabet No. 1"
Char conversion codesets:
"X/Open UTF-8; UCS Transformation Format 8 (UTF-8)"
"ISO 646:1991 IRV (International Reference Version)"
Native wchar codeset:
"ISO/IEC 10646-1:1993; UTF-16, UCS Transformation Format 16-bit form"
Wchar conversion codesets:
"ISO/IEC 10646-1:1993; UCS-2, Level 1"
"ISO 8859-1:1987; Latin Alphabet No. 1"
"X/Open UTF-8; UCS Transformation Format 8 (UTF-8)"
"ISO 646:1991 IRV (International Reference Version)"
IOR 中嵌入的是 type_id、IIOP 版本、主机地址和端口号,以及对象键。type_id 字符串是接口类型,众所周知,它是 资源库标识格式。基本上,资源库标识是接口唯一的标识。这个标识可以是 DCE UUID 格式(COM 程序员比较熟悉它)或者是您指定的本地格式。IIOP 版本将帮助 IOR 阅读器(通常是 ORB)正确了解 IOR 是哪种格式,因为 OMG 总是改进规范,每个版本的阅读方法都与以前版本略有不同 ;-)。主机地址和端口号将让我们接触到与期望的对象通信的 ORB。对象键和许多其它资料都是按特定于服务的信息的 OMG 标准构建的。这是帮助 OTB 支持服务器的特定于服务的数据。例如,这些专用 IOR 组件可以编码 ORB 类型和版本,或者帮助支持 OMG 安全服务的 ORB 实现。以上大多数信息指定了字符代码集转换,这样客户机和服务器就能够互相理解。
如果通过 Xerox Parc IOR 语法分析器运行 IOR,将得到以下输出:
IIOP_ParseCDR: byte order BigEndian,
repository id,
1 profile
_IIOP_ParseCDR: profile 1 is 124 bytes,
tag 0 (INTERNET),
BigEndian byte order
(iiop.c:parse_IIOP_Profile): bo=BigEndian,
version=1.2,
hostname=192.168.165.142,
port=4545,
object_key=<...1961005816._RootPOA......9G......>
(iiop.c:parse_IIOP_Profile): encoded object key is
<
(iiop.c:parse_IIOP_Profile):?non-native cinfo is object key is
<#AB#AC#AB196100
5816#00_RootPOA
#00#00#CA#FE#BA
#BE9G#C8#F8#00#
00#00#00>;
no trustworthy most-specific-type info;
unrecognized ORB;
reachable with IIOP 1.2 at host "192.168.165.142", port 4545
IOR 中最主要的部分是帮助客户机连接到服务器的那些部分。可以在 Xerox Parc IOR 阅读器(请参阅 参考资料)的输出中看到这些部分。但是,其它许多信息是 Orbacus 专有的,其它 IOR 阅读器不能解释它。这些专用部分是作为附加到 IOR 的数据序列出现的,并且只有构建 IOR 的 ORB 才懂得这些数据。
回页首
存根
现在,我们知道 IOR 带来了什么功能。IOR 的目的就是使客户机能够连接到服务器,以便它能够完成方法调用。客户机必须用 Add 方法将 IOR 转换成它可以调用的实际对象。这是通过使用从 IDL 编译器中生成的两个 Java 文件来完成的。客户机将首先使用 calculatorHelper 对象将 IOR 的范围缩小到 _calculatorStub 代理对象。
以下是 Orbacus 附带的 jidl 编译器生成的 narrow() 方法:
public static calculator narrow(org.omg.CORBA.Object _ob_v) {
if(_ob_v != null) {
try {
return (calculator)_ob_v;
} catch(ClassCastException ex) {
}
if(_ob_v._is_a(id())) {
org.omg.CORBA.portable.ObjectImpl _ob_impl;
_calculatorStub _ob_stub = new _calculatorStub();
_ob_impl = (org.omg.CORBA.portable.ObjectImpl)_ob_v;
_ob_stub._set_delegate(_ob_impl._get_delegate());
return _ob_stub;
}
throw new org.omg.CORBA.BAD_PARAM();
}
return null;
}
可以看到,它最主要的任务是创建一个新的 _calculatorStub 对象。 _calculatorStub 充当驻留在服务器上的实际计算器对象的代理对象。如果您不了解代理模式,我将非常乐意向您介绍“四人组” Design Patterns一书(请参阅 参考资料)。实际上,代理模式无非是创建一个代表或充当另一个实际对象的替身的对象,另一个对象将最终将调用或执行服务。代理模式是一种重要且常用的模式。在所有分布式设计中都会用到它。我敢打赌,您肯定用过这种模式,只不过从没有称您的设计为代理模式。
一旦创建了 _calculatorStub ,它就代表客户机的计算器接口。add 方法在服务器中实现,而该服务器在 IOR 中定义的地址上的电脑空间中运行。至此,这就所调用的 add() 方法。这里,需要注意两点:首先,我们必须以 _calculatorStub 的形式调用 add 方法。其次,请注意客户机将中断直到调用返回,就像其它同步方法调用一样。这是一种请求响应协议,它模仿单进程应用程序。编程客户机,然后使用该请求响应协议执行客户机就像用库和 API 调用创建的常用编程开发环境一样普通自然。这并不表示您不能使用异步调用;您当然可以生成那种类型的调用。我将在以后的专栏文章中讨论那些话题。
回页首
打包:GIOP 和 CDR
至此,在体系结构中,我们已成功欺骗了客户机,使它相信服务与它在一起。但事实并为如此,并且在以后几步中,我们必须将数据和方法调用铸造成一种形式,它允许在网络上继续该调用,并且可以在另一端使用该调用。这并不是无关重要的,且这种模型已经问世好几年了。您也许已经多次见过 OSI 模型了,在图 2 中,您将看到 OSI 模型,旁边就是 OMG 所使用的模型。
图 2. OSI 的结构 vs. GIOP 协议堆栈
客户机调用接口操作时,它必须将操作数据(in 和 inout 参数)发送到服务器。此时的困难在于将数据转换成公共格式,这样服务器抽取操作数据时不会误解或错误对齐数据。因为服务器可以是任意数量不同的平台,我们应该预计到客户机和服务器之间的体系结构差异。CORBA 通过严格定义如何将数据转换或打包成公共格式来处理这种问题。然后在连接的另一端重新组成或解包数据。这是通过用最基本的结构表示数据来完成的,最基本的结构就是字节流,也就是八位元流。
CORBA 规范将八位元流定义成“一种抽象表示法,通常对应于要通过 IPC 机制或网络传输来发送到另一个进程或另一台机器的内存缓冲区”。IDL 八位元准确映射成 Java 字节。它们都是 8 位值,客户机或服务器都不打包这种值。将这些参数转换成八位元序列的根本目的是产生用于信息交换的基本结构。
现在,我们应当窥视 _calculatorStub 生成的代码的内部信息。请记住这不是由我编写的 -- 它是由 Orbacus 附带的 IDL-到-Java 编译器 jidl 生成的。
//
// IDL:corbasem/gen/calcsimpl/calculator/add:1.0
//
public int add(int _ob_a0, int _ob_a1) {
System.out.println("Inside _calculatorStub.add()");
while(true) {
if(!this._is_local()) {
org.omg.CORBA.portable.OutputStream out = null;
org.omg.CORBA.portable.InputStream in = null;
try {
out = _request("add", true);
out.write_long(_ob_a0);
out.write_long(_ob_a1);
in = _invoke(out);
int _ob_r = in.read_long();
return _ob_r;
} catch(org.omg.CORBA.portable.RemarshalException _ob_ex) {
continue;
} catch(org.omg.CORBA.portable.ApplicationException _ob_aex) {
final String _ob_id = _ob_aex.getId();
in = _ob_aex.getInputStream();
throw new org.omg.CORBA.UNKNOWN("Unexpected User Exception: " + _ob_id);
} finally {
_releaseReply(in);
}
} else {
org.omg.CORBA.portable.ServantObject _ob_so = _servant_preinvoke
("add", _ob_opsClass);
if(_ob_so == null)
continue;
calculatorOperations _ob_self = (calculatorOperations)_ob_so.servant;
try {
return _ob_self.add(_ob_a0, _ob_a1);
} finally {
_servant_postinvoke(_ob_so);
}
}
}
}
要注意的部分是包含 _request() 、 write_long() 调用,和 _invoke() 及随后的 read_long() 。对 _request() 的调用使用要调用的方法名称,和显示是否需要响应的布尔 (boolean) 值。它返回 CORBA 规范指定的 org.omg.CORBA.portable.OutputStream 对象。对于可移植性,这是必要的,因为 Java 经常被下载,并且依赖于它运行的机器上的公共库。对于 ORB 是这样,对于 IO 也是这样。因此,CORBA 规范为 Java 语言定义了比其它语言更广泛的可移植类型集合。
通用 ORB 间协议 (GIOP)
通用 ORB 间协议 (GIOP) 用来为这个由不同计算机及其各种体系结构组成的凌乱世界中传送消息定义结构和格式。如果使用 GIOP 的结构和格式,并将它们应用于 TCP/IP,那么就得到 IIOP。GIOP 有两个版本:1.0 和 1.1。这就意味着我们的消息根据其符合的 GIOP 版本可能有不同的格式。
至此,我们必须看一下 GIOP 以了解请求在变成正确格式化的 CORBA 请求时所要经历的操作。尽管我们将仔细研究请求,响应只是请求的镜像图像。如果您知道请求的工作原理,那么您就能了解响应。
GIOP 请求消息分成三部分:GIOP 消息头、GIOP 请求头和请求主体。GIOP 消息头表示这就是一条 GIOP 消息。它包含 GIOP 版本、消息类型、消息大小,然后根据您是使用 1.0、1.1 还是 1.2,包含字节次序 (GIOP 1.0) 或一个位标志字段,该字段包括字节次序以及一些保留位标志。GIOP 1.1 添加了对消息存储碎片的支持,GIOP 1.2 添加了双向通信支持。更新的版本都是向下兼容的。
公共数据表示 (CDR)公共数据表示 (CDR) 是 CORBA 调用中将使用的数据类型的正式映射。客户机生成请求时,它不必知道请求要发送到什么地方,或者哪一台服务器将响应该请求。CORBA(作为规范)和 GIOP(作为规范的一部分,定义消息结构和传送)被设计成允许实现一个接口的可能的多种不同服务器之一来响应请求。规范必须定义如何打包操作中的数据,这样所有可能的服务器都可以抽取参数并调用远程操作,并且数据转换不会产生多义性。这种转换问题的典型示例就是指针。客户机中的指针对于在另一台机器上运行另一个进程的服务器意味着什么?毫无意义。或者,变量如何在使用不同寻址方案(大尾数法,小尾数法)的机器间发送?这些数据类型必须转换成服务器能够理解并使用的流。显然,CORBA 规范在公共数据表示方面是十分详细的。这是我们不必涉足的细节层次,但如果您想要了解详细信息,请阅读规范或 Ruh、Herron 和 Klinkeron 合著的 IIOP Complete一书(请参阅
参考资料)。
一旦包装了所有数据,就将使用 IOR 中的信息来创建连接。您可以区别 IOR 的结构,通常必须使用 TCP 作为传送机制。但是,也可以使用其它传送(再次提醒,请参阅 CORBA 规范以获取详细信息)。ORB 守护程序负责查找 IOR 指定的对象实现,以及建立客户机和服务器之间的连接。一旦建立了连接,GIOP 将定义一组由客户机用于请求或服务器用于响应的消息。客户机将发送消息类型 Request、LocateRequest、CancelRequest、Fragment 和 MessageError。服务器可以发送消息类型 Reply、LocateReply、CloseConnection、Fragment 和 MessageError。
如果我们扯开 GIOP 消息,它看上去就像:
0x47 0x49 0x4f 0x50 -> GIOP, the key
0x01 0x00 -> GIOP_version
0x00 -> Byte order (big endian)
0x00 -> Message type (Request message)
0x00 0x00 0x00 0x2c -> Message size (44)
0x00 0x00 0x00 0x00 -> Service context
0x00 0x00 0x00 0x01 -> Request ID
0x01 -> Response expected
0x00 0x00 0x00 0x24 -> Object key length in octets (36)
0xab 0xac 0xab 0x31 0x39 0x36 0x31 0x30
0x30 0x35 0x38 0x31 0x36 0x00 0x5f 0x52
0x6f 0x6f 0x74 0x50 0x4f 0x41 0x00 0x00
0xca 0xfe 0xba 0xbe 0x39 0x47 0xc8 0xf8
0x00 0x00 0x00 0x00 -> Object key defined by vendor
0x00 0x00 0x00 0x04 -> Operation name length (4 octets long)
0x61 0x64 0x64 0x00 -> Value of operation name ("add")
0x20 -> Padding bytes to align next value
您应该了解大概情况了。这种消息流是高度结构化的。它也必须是,为了客户机可以创建服务器可以转换成实现的消息 -- 不管实现如何运行,或在哪里运行。服务器也必须为在响应客户机时使用的返回值和参数执行相同操作。此消息格式在 OMG 成就中非常重要,因为它可以实现可移植性和互操作性目标。这种可移植性将给予您我们在第一篇专栏文章中谈到的自由。您无需关心硬件、数据库或编程语言。只要关心您的信息就行了。
回页首
IIOP
我们还没有彻底结束。GIOP 是 CORBA 方法调用的核心部分。GIOP 不基于任何特别的网络协议,如 IPX 或 TCP/IP。为了确保互操作性,OMG 必须将 GIOP 定义在所有供应商都支持的特定传输之上。如果有详细和简洁的消息规范,则不会提供互操作性,因为所有供应商使用不同的传送机制来实现这个互操作性。因此,OMG 在最广泛使用的通信传输平台 -- TCP/IP 上标准化 GIOP。GIOP 加 TCP/IP 等于 IIOP!就这么简单。
需要使用已发布对象服务的客户机将使用 IOR 中的值来启动与对象的连接。我们已经绕了一个圈子,又回到了 IOR。IOR 对于 IIOP 是至关重要的,任何要对某个对象调用方法的客户机都要将“请求”消息发送到 IOR 中详细说明的主机和端口地址。在主机上,服务器进程在请求进入时会侦听端口,并将那些消息发送到对象。这就要求服务器主动侦听请求。
生活有阴阳两面,每件事都有缺点,互操作性和 IIOP 也不例外。OMG 推出和运行了 IIOP,对比 ORB 供应商它们自己的服务器上实现此功能,并且没有服务器方可移植性的年代,这是一大改进。但如果要求服务器是位置无关的,我们应该做什么?如果主机和端口值嵌入 IOR 中,每当您将对象从一个服务器移到另一个服务器,以均衡负载时,这个问题就会突然出现。可喜的是这个问题已经解决了;但又有一条坏消息,每家供应商的解决方法都不同。
回页首
结束语
现在,将负载均衡话题留到将来讨论。如果您在几年前有 CORBA“经验”(也就是说在一段时期内),而现在从事另一项研究,我相信您将感到惊喜。CORBA 规范已经获得很大进步,可以确保您为一个 ORB 编写的服务器代码可以移植到运行另一个 ORB 的另一台服务器上。解决方案非常简单,并且以经典的协议为基础。客户机和服务器间的标准交换语法基于某些 OMG 详细说明的需求。OMG 通过使用网络寻址协议 (IIOP) 独立于消息传递协议 (GIOP),为其规范创建了更多功能。这也确保随着信息工业的变动(的确发展很快),CORBA 仍能跟上它的步伐。我最喜欢的是,对于我们刚讨论的关于如何使之成功完成的 CORBA 对象调用,我不必编写代码!在 ORB 中和用 IDL 标准化接口的功能中已经概括了网络测量和打包的详细信息。下个月,我们将讨论 IDL。
参考资料
Continue reading 【转】接触 CORBA 内幕: IOR、GIOP 和 IIOP
见维基百科:http://zh.wikipedia.org/wiki/%E9%9C%8D%E5%A4%AB%E6%9B%BC%E7%BC%96%E7%A0%81
这个还是比较好理解的:
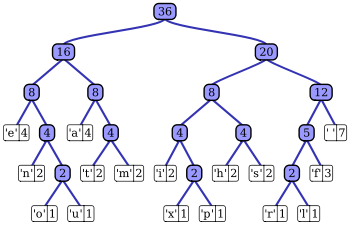

这个句子“this is an example of a huffman tree”中得到的字母频率来建构霍夫曼树。句中字母的编码和频率如下。编码此句子句子需要135 bit(不包括保存树所用的空间)
我来解释一下:
先从扫描表中找到最小的两个权值字母o,u,加权得2.
从剩下找出最小的权值两个字母x,p加权得2
任然有两个比2小的权值r,l加权得2。
再找剩下最小的两个是n,和上三次相加的权值2
重复上面的步骤最终得到顶点。
当然上面图中o也可以和权值同为1的x加权,对算法没有影响!
曼彻斯特编码和差分曼彻斯特编码
这个涉及的数学概念不多,倒是有些物理概念。指的是数据的传输方式,以电压跳变来表示0,1。
百度百科上:
在一些国外的网站有明确的表示方法。由右图可见曼彻斯特编码在网络应用中和科学家G.E.Thomas定义的不一样。由低电平到高电平是“0”,由高电平到低电平是“1”才是网络上的通俗用法。
教科书上说这两种都算正确!
Continue reading 霍夫曼/赫夫曼编码 曼彻斯特编码
看了七八篇,就这篇看懂了!
1 最短路径算法
在日常生活中,我们如果需要常常往返A地区和B地区之间,我们最希望知道的可能是从A地区到B地区间的众多路径中,那一条路径的路途最短。最短路径问题是图论研究中的一个经典算法问题, 旨在寻找图(由结点和路径组成的)中两结点之间的最短路径。 算法具体的形式包括:
(1)确定起点的最短路径问题:即已知起始结点,求最短路径的问题。
(2)确定终点的最短路径问题:与确定起点的问题相反,该问题是已知终结结点,求最短路径的问题。在无向图中该问题与确定起点的问题完全等同,在有向图中该问题等同于把所有路径方向反转的确定起点的问题。
(3)确定起点终点的最短路径问题:即已知起点和终点,求两结点之间的最短路径。
(4)全局最短路径问题:求图中所有的最短路径。
用于解决最短路径问题的算法被称做“最短路径算法”, 有时被简称作“路径算法”。 最常用的路径算法有:Dijkstra算法、A*算法、Bellman-Ford算法、Floyd-Warshall算法、Johnson算法。
本文主要研究Dijkstra算法的单源算法。
2 Dijkstra算法
2.1 Dijkstra算法
Dijkstra算法是典型最短路算法,用于计算一个节点到其他所有节点的最短路径。主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。Dijkstra算法能得出最短路径的最优解,但由于它遍历计算的节点很多,所以效率低。
Dijkstra算法是很有代表性的最短路算法,在很多专业课程中都作为基本内容有详细的介绍,如数据结构,图论,运筹学等等。
2.2 Dijkstra算法思想
Dijkstra算法思想为:设G=(V,E)是一个带权有向图,把图中顶点集合V分成两组,第一组为已求出最短路径的顶点集合(用S表示,初始时S中只有一个源点,以后每求得一条最短路径 , 就将 加入到集合S中,直到全部顶点都加入到S中,算法就结束了),第二组为其余未确定最短路径的顶点集合(用U表示),按最短路径长度的递增次序依次把第二组的顶点加入S中。在加入的过程中,总保持从源点v到S中各顶点的最短路径长度不大于从源点v到U中任何顶点的最短路径长度。此外,每个顶点对应一个距离,S中的顶点的距离就是从v到此顶点的最短路径长度,U中的顶点的距离,是从v到此顶点只包括S中的顶点为中间顶点的当前最短路径长度。
2.3 Dijkstra算法具体步骤
(1)初始时,S只包含源点,即S=,v的距离为0。U包含除v外的其他顶点,U中顶点u距离为边上的权(若v与u有边)或 )(若u不是v的出边邻接点)。
(2)从U中选取一个距离v最小的顶点k,把k,加入S中(该选定的距离就是v到k的最短路径长度)。
(3)以k为新考虑的中间点,修改U中各顶点的距离;若从源点v到顶点u(u U)的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,修改后的距离值的顶点k的距离加上边上的权。
(4)重复步骤(2)和(3)直到所有顶点都包含在S中。
2.4 Dijkstra算法举例说明
如下图,设A为源点,求A到其他各顶点(B、C、D、E、F)的最短路径。线上所标注为相邻线段之间的距离,即权值。(注:此图为随意所画,其相邻顶点间的距离与图中的目视长度不能一一对等)
图一:Dijkstra无向图

算法执行步骤如下表:【注:图片要是看不到请到“相册--日志相册”中,名为“Dijkstra算法过程”的图就是了】

参考文献
[1] 黄国瑜、叶乃菁,数据结构,清华大学出版社,2001年8月第1版
[2] 最短路径,http://baike.baidu.com/view/349189.htm?func=retitle
[3] 李春葆,数据结构教程,清华大学出版社,2005年1月第1版
[3] Dijkstra算法,http://baike.baidu.com/view/7839.htm
----------------------------------------------------------------------------------------------------------------------------
再讲讲直观一点的标号法处理如下的较复杂的图:

这个图很容易让人看昏,漏掉了较短路径,从a点到z点最短路径为13。
步骤,从途中列出所有点从近到远到a的最短距离,这样可以基于之前的点找到余下的点。
a-----b/d[2]------e[3]-----h[5]-----f[6]-----c[7]------g[9]-----j[10]-----i[11]------z[13]
这里面f点是个比较容易忽视的点,使用标号法就不容易出错!
Continue reading 最短路径解法






