转自: http://www.liuzm.com/article/java/100318.htm
最近看一些关于JAVA的面试题,都是关于内存泄露与溢出。当时看到这个题目时,我自己也感觉有点糊。
然后查了下资料。结合自己总结下关于内存泄露与溢出的区别
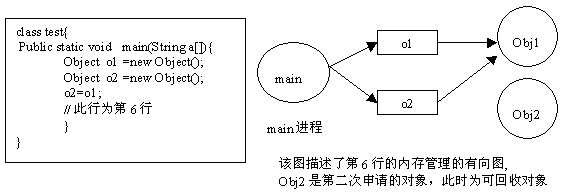
内存溢出就是你要求分配的内存超出了系统能给你的,系统不能满足需求,于是产生溢出。
内存泄漏就是没有及时清理内存垃圾,导致系统无法再给你提供内存资源(内存资源耗尽)。
看到上面的解释,可能有些朋友还是不太理解吧。没问题,看以下例子
1.内存泄露是说程序逻辑问题,造成申请的内存无法释放.这样的话无论多少内存,早晚都会被占用光的.
最简单的例子就是死循环了.由于程序判断错误导经常发生此事
2.内存泄漏是指在堆上分配的内存没有被释放,从而失去对其控制。这样会造成程序能使用的内存越来越少,导致系统运行速度减慢,严重情况会使程序当掉。
3.关于内存溢出有点出入。比如说你申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。
举个现实中的例子
4.比如有一个桶,装满了水.你丢个苹果进去。桶的水正常。
如果你放个大石头。水就出溢出,内存溢出也就是这个原理
区别:内存溢出,提供的内存不够;内存泄漏,无法再提供内存资源
可能大家会问内存泄露与溢出是考JAVA哪方面?考这个有什么用?
我个人觉的是考大家对JAVA是怎么管理内存这一块的知识?对下是对Java是如何管理内存的解释
Java是如何管理内存
为了判断Java中是否有内存泄露,我们首先必须了解Java是如何管理内存的。Java的内存管理就是对象的分配和释放问题。在Java中,内存的分配是由程序完成的,而内存的释放是由垃圾收集器(Garbage Collection,GC)完成的,程序员不需要通过调用函数来释放内存,但它只能回收无用并且不再被其它对象引用的那些对象所占用的空间。
Java的内存垃圾回收机制是从程序的主要运行对象开始检查引用链,当遍历一遍后发现没有被引用的孤立对象就作为垃圾回收。GC为了能够正确释放对象,必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC都需要进行监控。监视对象状态是为了更加准确地、及时地释放对象,而释放对象的根本原则就是该对象不再被引用。
在Java中,这些无用的对象都由GC负责回收,因此程序员不需要考虑这部分的内存泄露。虽然,我们有几个函数可以访问GC,例如运行GC的函数System.gc(),但是根据Java语言规范定义,该函数不保证JVM的垃圾收集器一定会执行。因为不同的JVM实现者可能使用不同的算法管理GC。通常GC的线程的优先级别较低。JVM调用GC的策略也有很多种,有的是内存使用到达一定程度时,GC才开始工作,也有定时执行的,有的是平缓执行GC,有的是中断式执行GC。但通常来说,我们不需要关心这些。
Continue reading 【转】Java内存泄露与溢出的区别
转自http://developer.51cto.com/art/201009/227691.htm
垃圾收集GC(Garbage Collection)是Java语言的核心技术之一,之前我们曾专门探讨过Java 7新增的垃圾回收器G1的新特性,但在JVM的内部运行机制上看,Java的垃圾回收原理与机制并未改变。垃圾收集的目的在于清除不再使用的对象。GC通过确定对象是否被活动对象引用来确定是否收集该对象。GC首先要判断该对象是否是时候可以收集。两种常用的方法是引用计数和对象引用遍历。
引用计数收集器
引用计数是垃圾收集器中的早期策略。在这种方法中,堆中每个对象(不是引用)都有一个引用计数。当一个对象被创建时,且将该对象分配给一个变量,该变量计数设置为1。当任何其它变量被赋值为这个对象的引用时,计数加1(a = b,则b引用的对象+1),但当一个对象的某个引用超过了生命周期或者被设置为一个新值时,对象的引用计数减1。任何引用计数为0的对象可以被当作垃圾收集。当一个对象被垃圾收集时,它引用的任何对象计数减1。
优点:引用计数收集器可以很快的执行,交织在程序运行中。对程序不被长时间打断的实时环境比较有利。
缺点: 无法检测出循环引用。如父对象有一个对子对象的引用,子对象反过来引用父对象。这样,他们的引用计数永远不可能为0.
跟踪收集器
早期的JVM使用引用计数,现在大多数JVM采用对象引用遍历。对象引用遍历从一组对象开始,沿着整个对象图上的每条链接,递归确定可到达(reachable)的对象。如果某对象不能从这些根对象的一个(至少一个)到达,则将它作为垃圾收集。在对象遍历阶段,GC必须记住哪些对象可以到达,以便删除不可到达的对象,这称为标记(marking)对象。
下一步,GC要删除不可到达的对象。删除时,有些GC只是简单的扫描堆栈,删除未标记的未标记的对象,并释放它们的内存以生成新的对象,这叫做清除(sweeping)。这种方法的问题在于内存会分成好多小段,而它们不足以用于新的对象,但是组合起来却很大。因此,许多GC可以重新组织内存中的对象,并进行压缩(compact),形成可利用的空间。
为此,GC需要停止其他的活动活动。这种方法意味着所有与应用程序相关的工作停止,只有GC运行。结果,在响应期间增减了许多混杂请求。另外,更复杂的 GC不断增加或同时运行以减少或者清除应用程序的中断。有的GC使用单线程完成这项工作,有的则采用多线程以增加效率。
一些常用的垃圾收集器
◆标记-清除收集器
这种收集器首先遍历对象图并标记可到达的对象,然后扫描堆栈以寻找未标记对象并释放它们的内存。这种收集器一般使用单线程工作并停止其他操作。并且,由于它只是清除了那些未标记的对象,而并没有对标记对象进行压缩,导致会产生大量内存碎片,从而浪费内存。
◆标记-压缩收集器
有时也叫标记-清除-压缩收集器,与标记-清除收集器有相同的标记阶段。在第二阶段,则把标记对象复制到堆栈的新域中以便压缩堆栈。这种收集器也停止其他操作。
复制收集器
这种收集器将堆栈分为两个域,常称为半空间。每次仅使用一半的空间,JVM生成的新对象则放在另一半空间中。GC运行时,它把可到达对象复制到另一半空间,从而压缩了堆栈。这种方法适用于短生存期的对象,持续复制长生存期的对象则导致效率降低。并且对于指定大小堆来说,需要两倍大小的内存,因为任何时候都只使用其中的一半。
增量收集器
增量收集器把堆栈分为多个域,每次仅从一个域收集垃圾,也可理解为把堆栈分成一小块一小块,每次仅对某一个块进行垃圾收集。这会造成较小的应用程序中断时间,使得用户一般不能觉察到垃圾收集器正在工作。
分代收集器
复制收集器的缺点是:每次收集时,所有的标记对象都要被拷贝,从而导致一些生命周期很长的对象被来回拷贝多次,消耗大量的时间。而分代收集器则可解决这个问题,分代收集器把堆栈分为两个或多个域,用以存放不同寿命的对象。JVM生成的新对象一般放在其中的某个域中。过一段时间,继续存在的对象(非短命对象)将获得使用期并转入更长寿命的域中。分代收集器对不同的域使用不同的算法以优化性能。
并行收集器
并行收集器使用某种传统的算法并使用多线程并行的执行它们的工作。在多CPU机器上使用多线程技术可以显著的提高java应用程序的可扩展性。
最后,贴出一个非常简单的跟踪收集器的例图,以便大家加深对收集器的理解:
跟踪收集器图例
使用垃圾收集器要注意的地方
下面将提出一些有关垃圾收集器要注意的地方,垃圾收集器知识很多,下面只列出一部分必要的知识:
◆每个对象只能调用finalize( )方法一次。如果在finalize( )方法执行时产生异常(exception),则该对象仍可以被垃圾收集器收集。
◆垃圾收集器跟踪每一个对象,收集那些不可触及的对象(即该对象不再被程序引用 了),回收其占有的内存空间。但在进行垃圾收集的时候,垃圾收集器会调用该对象的finalize( )方法(如果有)。如果在finalize()方法中,又使得该对象被程序引用(俗称复活了),则该对象就变成了可触及的对象,暂时不会被垃圾收集了。但是由于每个对象只能调用一次finalize( )方法,所以每个对象也只可能 "复活 "一次。
◆Java语言允许程序员为任何方法添加finalize( )方法,该方法会在垃圾收集器交换回收对象之前被调用。但不要过分依赖该方法对系统资源进行回收和再利用,因为该方法调用后的执行结果是不可预知的。
◆垃圾收集器不可以被强制执行,但程序员可以通过调研System.gc方法来建议执行垃圾收集。记住,只是建议。一般不建议自己写System.gc,因为会加大垃圾收集工作量。
【编辑推荐】
- 深入Java核心 Java中多态的实现机制
- 深入Java核心 Java内存分配原理精讲
- Java程序员必须了解GC的工作原理
- 简单理解Java GC与幽灵引用
Continue reading 【转】深入Java核心 探秘Java垃圾回收机制
转自 http://www.iteye.com/topic/484934
目录
基本预备相关知识
对象的销毁过程
对象重生的例子
对象的finalize的执行顺序
何时及如何使用finalize
参考
基本预备相关知识
1 java的GC只负责内存相关的清理,所有其它资源的清理必须由程序员手工完成。要不然会引起资源泄露,有可能导致程序崩溃。
2 调用GC并不保证GC实际执行。
3 finalize抛出的未捕获异常只会导致该对象的finalize执行退出。
4 用户可以自己调用对象的finalize方法,但是这种调用是正常的方法调用,和对象的销毁过程无关。
5 JVM保证在一个对象所占用的内存被回收之前,如果它实现了finalize方法,则该方法一定会被调用。Object的默认finalize什么都不做,为了效率,GC可以认为一个什么都不做的finalize不存在。
6 对象的finalize调用链和clone调用链一样,必须手工构造。
如
Java代码 
- protected void finalize() throws Throwable {
- super.finalize();
- }
对象的销毁过程
在对象的销毁过程中,按照对象的finalize的执行情况,可以分为以下几种,系统会记录对象的对应状态:
unfinalized 没有执行finalize,系统也不准备执行。
finalizable 可以执行finalize了,系统会在随后的某个时间执行finalize。
finalized 该对象的finalize已经被执行了。
GC怎么来保持对finalizable的对象的追踪呢。GC有一个Queue,叫做F-Queue,所有对象在变为finalizable的时候会加入到该Queue,然后等待GC执行它的finalize方法。
这时我们引入了对对象的另外一种记录分类,系统可以检查到一个对象属于哪一种。
reachable 从活动的对象引用链可以到达的对象。包括所有线程当前栈的局部变量,所有的静态变量等等。
finalizer-reachable 除了reachable外,从F-Queue可以通过引用到达的对象。
unreachable 其它的对象。
来看看对象的状态转换图。

好大,好晕,慢慢看。
1 首先,所有的对象都是从Reachable+Unfinalized走向死亡之路的。
2 当从当前活动集到对象不可达时,对象可以从Reachable状态变到F-Reachable或者Unreachable状态。
3 当对象为非Reachable+Unfinalized时,GC会把它移入F-Queue,状态变为F-Reachable+Finalizable。
4 好了,关键的来了,任何时候,GC都可以从F-Queue中拿到一个Finalizable的对象,标记它为Finalized,然后执行它的finalize方法,由于该对象在这个线程中又可达了,于是该对象变成Reachable了(并且Finalized)。而finalize方法执行时,又有可能把其它的F-Reachable的对象变为一个Reachable的,这个叫做对象再生。
5 当一个对象在Unreachable+Unfinalized时,如果该对象使用的是默认的Object的finalize,或者虽然重写了,但是新的实现什么也不干。为了性能,GC可以把该对象之间变到Reclaimed状态直接销毁,而不用加入到F-Queue等待GC做进一步处理。
6 从状态图看出,不管怎么折腾,任意一个对象的finalize只至多执行一次,一旦对象变为Finalized,就怎么也不会在回到F-Queue去了。当然没有机会再执行finalize了。
7 当对象处于Unreachable+Finalized时,该对象离真正的死亡不远了。GC可以安全的回收该对象的内存了。进入Reclaimed。
对象重生的例子
Java代码
- class C {
- static A a;
- }
- class A {
- B b;
- public A(B b) {
- this.b = b;
- }
- @Override
- public void finalize() {
- System.out.println("A finalize");
- C.a = this;
- }
- }
- class B {
- String name;
- int age;
- public B(String name, int age) {
- this.name = name;
- this.age = age;
- }
- @Override
- public void finalize() {
- System.out.println("B finalize");
- }
- @Override
- public String toString() {
- return name + " is " + age;
- }
- }
- public class Main {
- public static void main(String[] args) throws Exception {
- A a = new A(new B("allen", 20));
- a = null;
- System.gc();
- Thread.sleep(5000);
- System.out.println(C.a.b);
- }
- }
期待输出
Java代码
- A finalize
- B finalize
- allen is 20
但是有可能失败,源于GC的不确定性以及时序问题,多跑几次应该可以有成功的。详细解释见文末的参考文档。
对象的finalize的执行顺序
所有finalizable的对象的finalize的执行是不确定的,既不确定由哪个线程执行,也不确定执行的顺序。
考虑以下情况就明白为什么了,实例a,b,c是一组相互循环引用的finalizable对象。
何时及如何使用finalize
从以上的分析得出,以下结论。
1 最重要的,尽量不要用finalize,太复杂了,还是让系统照管比较好。可以定义其它的方法来释放非内存资源。
2 如果用,尽量简单。
3 如果用,避免对象再生,这个是自己给自己找麻烦。
4 可以用来保护非内存资源被释放。即使我们定义了其它的方法来释放非内存资源,但是其它人未必会调用该方法来释放。在finalize里面可以检查一下,如果没有释放就释放好了,晚释放总比不释放好。
5 即使对象的finalize已经运行了,不能保证该对象被销毁。要实现一些保证对象彻底被销毁时的动作,只能依赖于java.lang.ref里面的类和GC交互了。
参考
关于引用类型,GC,finalize的相互交互可以参考ReferenceQueue GC finalize Reference 测试及相关问题
Continue reading 【转】深入理解java的finalize
转自 http://www.williamlong.info/archives/484.html
页面永久性移走(301重定向)是一种非常重要的“自动转向”技术。
301重定向可促进搜索引擎优化效果
从搜索引擎优化角度出发,301重定向是网址重定向最为可行的一种办法。当网站的域名发生变更后,搜索引擎只对新网址进行索引,同时又会把旧地址下原有的外部链接如数转移到新地址下,从而不会让网站的排名因为网址变更而收到丝毫影响。同样,在使用301永久性重定向命令让多个域名指向网站主域时,亦不会对网站的排名产生任何负面影响。
302重定向可影响搜索引擎优化效果
迄今为止,能够对302重定向具备优异处理能力的只有Google。也就是说,在网站使用302重定向命令将其它域名指向主域时,只有Google会把其它域名的链接成绩计入主域,而其它搜索引擎只会把链接成绩向多个域名分摊,从而削弱主站的链接总量。既然作为网站排名关键因素之一的外链数量受到了影响,网站排名降低也是很自然的事情了。
综上所述,在众多重定向技术中,301永久性重定向是最为安全的一种途径,也是极为理想的一款解决方案。
对于正确实施301重定向,有这样几个方法可供大家参考:
1.在.htaccess文件中增加301重定向指令
采用“mod_rewrite”技术,形如:
RewriteEngine on
RewriteRule ^(.*)$ http://www.williamlong.info/$1 [R=301,L]
2.适用于使用Unix网络服务器的用户
通过此指令通知搜索引擎的spider你的站点文件不在此地址下。这是较为常用的办法。
形如:Redirect 301 / http://www.williamlong.info/
3.在服务器软件的系统管理员配置区完成301重定向
适用于使用Window网络服务器的用户
4.绑定/本地DNS
如果具有对本地DNS记录进行编辑修改的权限,则只要添加一个记录就可以解决此问题。若无此权限,则可要求网站托管服务商对DNS服务器进行相应设置。
DNS服务器的设置
若要将blog.williamlong.info指向www.williamlong.info,则只需在DNS服务中应增加一个别名记录,可写成:blog IN CNAME www.williamlong.info。
如需配置大量的虚拟域名,则可写成:* IN CNAME www.williamlong.info.
这样就可将所有未设置的以williamlong.info结尾的记录全部重定向到www.williamlong.info上。
5.用ASP/PHP实现301重定向:
ASP:
Response.Status="301 Moved Permanently"
Response.AddHeader "Location","http://www.williamlong.info/"
Response.End
PHP:
header("HTTP/1.1 301 Moved Permanently");
header("Location:http://www.williamlong.info/");
exit();
参见:
http://www.51testing.com/?uid-43487-action-viewspace-itemid-191187 HTTP 301 跳转和302跳转的区别
Continue reading 【转】http 301 302跳转
习惯使用outlook的人也想在gamil里面常见规则,gmail当然有这个功能,但是它是叫“过滤器”。
最常见的方法:点击某封邮件点击更多操作/过滤此类邮件
这样你会发现条件选项,按照你的规则来吧,填完之后点击根据此搜索条件创建过滤器 »
选中应用标签,可在右边选择或是创建标签,一般我还会选择跳过“收件箱” (将其存档)和同时将此过滤器应用于 n 个匹配的会话。然后点击创建过滤器就可以了。之后你会发现符合条件的邮件都在刚刚建立的标签文件夹下,是不适合outlook一样呢!
如果你要隐藏你不会用到的标签,可在标签管理中相应标签项上点击隐藏标签
Continue reading gmail的规则功能
我的方法是基于自己编程实现的,故不适合普通用户。
但是思路大体和 http://www.syncoo.com/register-google-voice.htm 差不多。
即使用一个虚拟的美国号码来转到gtalk上来验证。
在最后一步使用gvoice输入验证码时需要注意:
输入验证号码的时候,要一个一个数字的输入,每输入一个数字就回车一下。
这是从上面的连接文章中得到的窍门。
gvoice绑定好后,可将电话转接到google chat上,但是一般应该使用gmail来进行电话操作,而不是真正的gtalk,因为我发现我登陆gtalk客户端,呼叫gvoice美国电话号码的电话并没有转接到gtalk上,而是转到gmail的聊天模块上了。而且我还没找到gtalk上有什么电话呼叫的按钮,+_+。
gvoice注意的选项:
setting/calls/Call Screening 应该选off,否则gvoice需要匿名呼叫者留言而不是直接接通--这个是用于屏蔽机器人呼叫者的。
参考:
http://hi.baidu.com/wodingdong/blog/item/d51bb1ce35667530b700c8d4.html
Continue reading gvoice 绑定
http://www.411.com/reverse_phone
http://www.allareacodes.com
可通过电话号码查归属地,电话公司等
当然也提供黄页,白页查询
Continue reading 美国411电话查询详细信息
phono是tropo的jquery脚本库,使得你可以轻松地整合语音,IM服务到你的网站上去。
官网http://www.phono.com
文档http://www.phono.com/docs
它的功能很强大:
tropo支持的它都支持,而且还更强大:
每个匿名session都有唯一的sessionid,可以作为匿名sip账号,因此它可以接收呼叫包括实际电话和sip电话。
同样它可以接收发送sms短信。这个不是本身提供的。
它可以接收发送xmpp消息。
当初始化好phono时,会得到一个唯一sessionid类似a95df60a-31c6-42ed-b56e-74a1baa1b9e5@gw114.phono.com
这是一个可以合法的sip地址。
dial方法:
呼叫电话号码:(不能带区号+1),其实质是通过tropo使用一个号码TELA转接到目标电话。如果直接回call这个号码TELA,则告知此号码不可用。
this.phone.dial("774-271-7100")
呼叫sip:
this.phone.dial("sip:9991443046@sip.voxeo.net")
呼叫tropo app:
$.phono({
onReady: function(event, phone) {
var text = prompt("Enter some text you'd like to hear in Spanish");
phone.dial("app:9991442945", {
headers: [
{
name:"x-source",
value:"en"
},
{
name:"x-target",
value:"es"
},
{
name:"x-text",
value:text
}
]
});
}
});
详细call api:http://www.phono.com/docs#call-reference
接收电话:
$.phono({
onReady: function(event) {
alert("My SIP address is sip:" + this.sessionId);
},
phone: {
onIncomingCall: function(event) {
var call = event.call;
alert("Incoming call");
}
}
});
发送xmpp消息:
$.phono({
onReady: function() {
this.messaging.send("phono-echo@tropo.im","Hello");
}
});
对于gtalk来说,是不接受非联系人消息的,除非gtalk用户手动将这个匿名账户添加到联系人再聊条。---所以,这个临时xmpp账户基本对gtalk没有什么实际意义。
接收xmpp消息: session可作为xmpp消息address
$.phono({
onReady: function(event) {
alert("My XMPP address is " + this.sessionId);
},
messaging: {
onMessage: function(event) {
var message = event.message;
alert("Message from: " + message.from + "\n" + message.body);
}
}
})
发送sms见http://blog.phono.com/2010/12/07/web-based-im-to-sms-gateway/ 原理是通过发送到tropo app的jabber账号由app来通过tropo的sms接口转发的。这样存在一个问题,因为多个phono用户给同一个sms用户发短信时,sms用户无法区分phono用户,因为app使用同一个电话号码,sms手机上就显示的是同一个号码的来自不同phono用户的消息?
Continue reading phono使用入门
首先最容易出错的是换行符的不同,windows 上写shell脚本放到linux上运行就不行。因为linux不认windows换行符,所以应该在notepad++这样的编辑器中修改一下 :编辑->档案格式转换->转为UNIX格式。
再一个windows bat变量使用%变量名%来替换,而在linux中需要将变量放在引号中替换如:
::windows:
set JVM_OPS=%JVM_OPS% -Djava.rmi.server.hostname=127.0.0.1
#shell:
JVM_OPS="$JVM_OPS -Djava.rmi.server.hostname=127.0.0.1"
Continue reading linux shell脚本和windows bat脚本的区别造成的问题
转自 http://blog.doyoe.com/article.asp?id=177
相信会进来看这篇文章的人,都对CSS选择符这个名词不陌生了。CSS为我们提供了很多选择符,这使得我们可以根据自己的需要选择适合的选择符来进行样式的构造。
在众多的选择符里,相信大家用的最多,最熟悉的就是ID选择符,类选择符及包含选择符等常用的选择符。然后对于一些如属性选择符,相邻选择符,子对象选择符可能就稍微有点陌生了,这当然也是有原因的,因为IE6及以下的浏览器并不支持这几个选择符,而大多数从事这方面工作的技术人员,多数时候还是主要考虑占据着浏览器市场大半壁江山的IE6,于是对这些IE6的非亲派不熟悉也成了一个没办法的必然。
在IE7,甚至是IE8,Firefox,Opera,Safari等慢慢蚕食IE6市场的今天,那些以往不大常用的选择符也逐渐开始被应用起来。比如呆会要讲到的子对象选择符。
要讲子对象选择符,当然得顺带讲一下包含选择符,因为这两者之间有着共同之处:
如以下一段简单的包含选择符例子:
body p{
color:#f00;
}
这是一个最简单的包含选择符,它表达的意思是所有body里面的p都将以红色的字显示。
我们再来看一个子对象选择符的例子:
body>p{
color:#f00;
}
这是一个子对象选择符,意思是所有body里面的“子对象”p都将以红色的字显示。
以同一段html为例,分别应用以上两段样式:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<meta http-equiv="Content-Language" content="gb2312" />
<title>em test</title>
<meta name="Author" content="Doyoe(飘零雾雨), dooyoe@gmail.com" />
</head>
<body>
<p>传说中的测试</p>
<div><p>传说中的测试</p></div>
<p>传说中的测试</p>
<div><p>传说中的测试</p></div>
</body>
</html>
包含选择符的效果为:
 (图一)
(图一)
子对象选择符的效果:
 (图二)
(图二)
从图一和图二上我们可以看出,包含选择符定义的样式应用到了body下的所有p元素上;而子对象选择符定义的样式只应用到body下的第一和第三个p元素上,这是因为第二和第四个p元素并非body的儿子,而是它的孙子。
由此可以见包含选择符的深度和广度超过子对象选择符;而子对象选择符的针对性和唯一性比包含选择符强。大家可以根据实际情况选择选择何种选择符来达到自己的目的。
Continue reading 【转】包含选择与子对象选择符的区别
Pagination



