可重入锁ReentrantLock
今天学习一下可重入锁ReentrantLock:
先来借别人的例子来看它怎么用:
这是java DelayQueue的take方法:
public E take() throws InterruptedException {
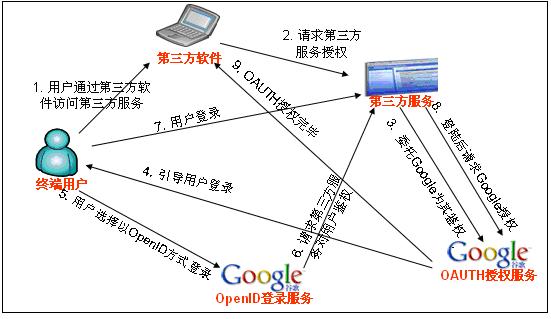
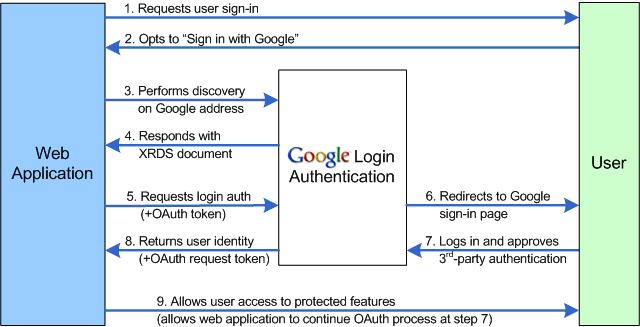
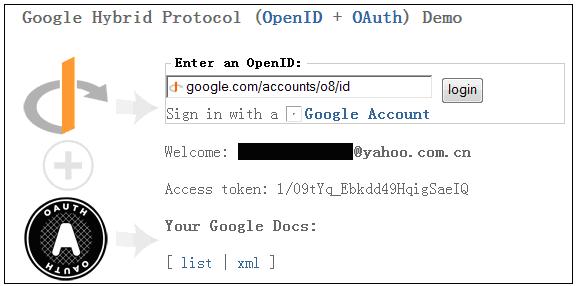
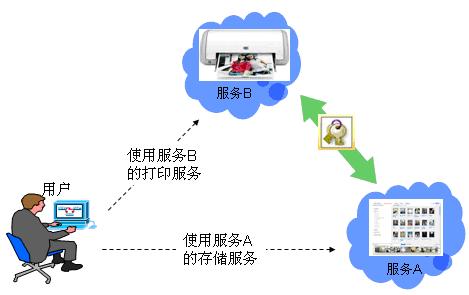
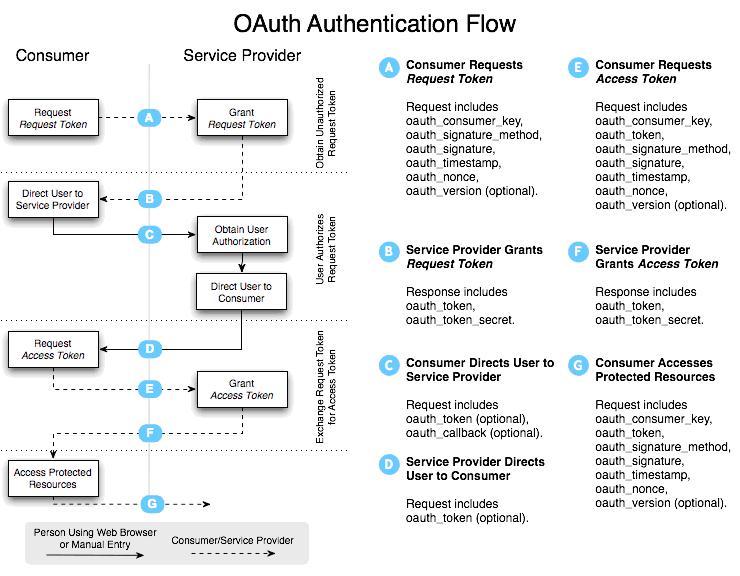
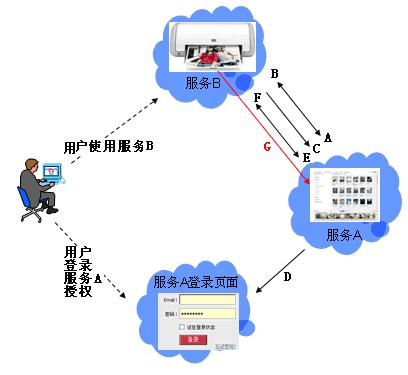
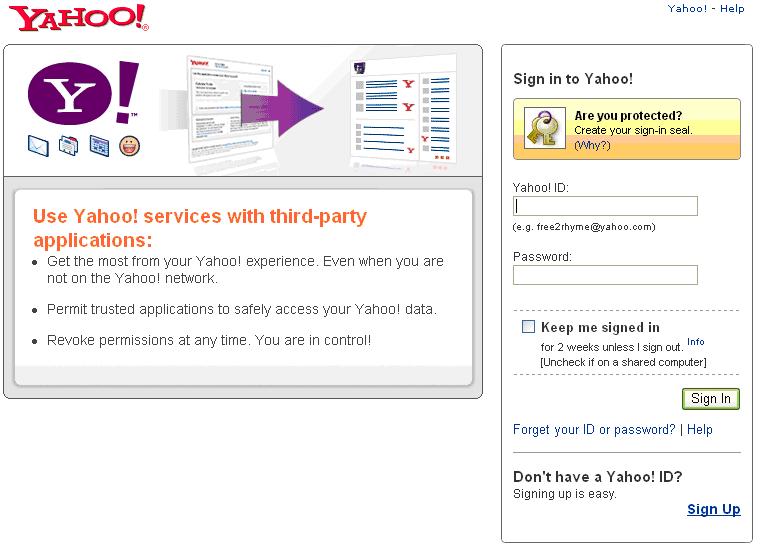
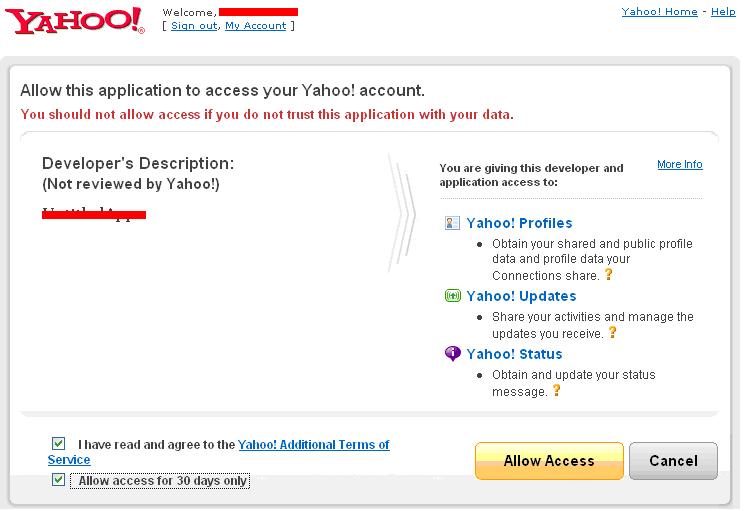
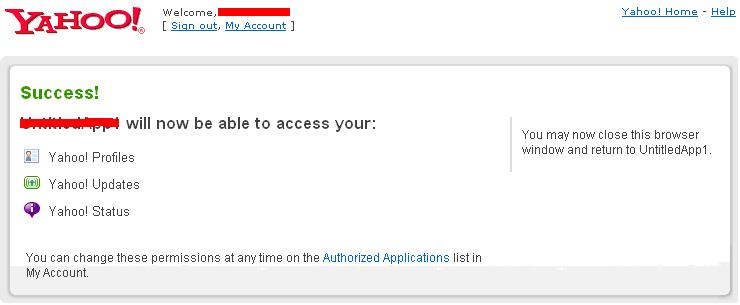
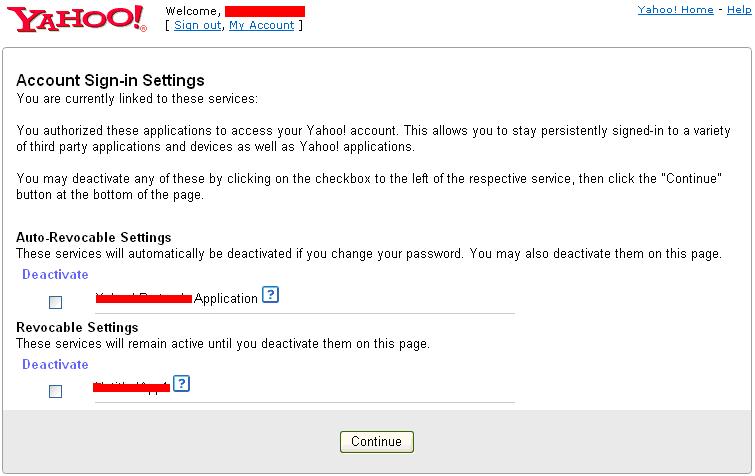
Continue reading 可重入锁ReentrantLock openfire最好依据目标操作系统选择版本,linux上就应该选择RPM版,这样就省却很多麻烦。比如与其他xmpp服务商的通信。openfire server上有个server to server配置,据我的经验,选择好了版本,安装好了,根本就不需要配置这个就可以和gtalk,jabber等通信,即本服务器上的用户user1@mydomail.com发送给abc@gmail.com的消息会发送给abc@gmail.com, abc@gmail.com的发送给user1@mydomail.com消息user1@mydomail.com也收的到。 另外http://sourceforge.net/projects/kraken-gateway这个插件是提供其他流行的xmpp server的登陆的,比如gtalk,yahoo,甚至QQ。 openfire是提供离线消息的,默认这个配置也是开启的,在Server/Server Settings/Offline Message 中配置 Continue reading openfire配置杂记 xmpphp对于注册新用户,添加好友等功能暂时还没有,以下是我在网上找到的补丁: Continue reading xmpphp 的一些补丁 in php windows上运行的好好的,传到服务器上就遇到"Cannot modify header information” 问题,看报错的行数也是文不对题,这种情况一般是编码格式问题,检查一下<?php ... ?> 后面没有空白行,删除即可。 参见: http://www.bytea.net/content/view/229/40.html Continue reading "Cannot modify header information" php 的恼火问题 web开发有时需要用到抓包工具分析请求与返回,通常,firefox的firebug已经够用。但是对于跨页面的请求则不行,如unload事件中的请求。这时可使用httpfox这个插件来监视,它的菜单在tools/web developer中,我开始还找半天。 其余的如果不是监视到本机服务器的请求,可以使用wireshark,但是我发现有时貌似不准,Fiddler更不行了。 它们两个都不好监视对本机服务器的http请求,像rawcap这样的更是不靠谱,输入到文件,用notepad++打开全是乱码。 Continue reading http抓包分析工具 window的unload事件,用起来不靠谱,为什么呢? 我做个测试来说明,在页面unload事件中做一个同步ajax请求,然后刷新页面,我来比较刷新时unload事件和get新页面请求发生的时间顺序,结果如下: FF: unload在get之后 Chrome: unload在get之后 IE: unload在get之前 Safari: unload在get之后 Opera: 没有unload事件 结果是FF,Safari,Chrome竟然unload请求在get请求之后。就只IE符合正常逻辑unload完了再get。Opera索性不支持unload事件。 通过HTTP抓包分析FF是先获得新页面的html然后执行上页面的unload事件,然后开始请求新页面的资源。 如果某些处理依赖unload事件而又讲究顺序的话,那就可能对我们的程序造成问题,所以,unload事件还是尽量不用为好,不靠谱啊! beforeubload也存在这个情况。 Continue reading unload事件,刷新,顺序,不靠谱 同系列文章,转载自 Google OAUTH + OpenID解决方案, 蓝色字是我加的注解或是着重提示。 在前面已经介绍过OAuth与OpenID,这两种服务,Google都实现了。我们可以通过Google OAuth服务为Google 用户的资源进行授权,如用户通过第三方软件调用Google Open API操作用户的资源时,就需要用户对第三方软件授权;通过Google OpenID服务可以打通Google与其他支持OpenID服务网站之间的用户体系。现在假如有另外一个网站,也想开放自己的Open API服务,但是又不想实现OAuth服务(毕竟实现OAUTH服务还是需要一些成本的),那该怎么办?它可不可以使用Google提供的OAuth服务,授权认证交给Google来处理?可以!但是OAuth授权也是基于用户登录来实现的,Google OAuth用户体系只是Google的用户体系,那又怎么办了?OpenID!对,将网站的用户体系与Google用户体系打通,并且使用Google OAuth服务来实现授权,即Google提出的OpenID + OAUTH的解决方案。 一、 OAUTH与OpenID 前面两篇文章对OAUTH与OpenID均做过介绍,且Google均提供了这两种服务,在此我们先简要的回顾这两种服务,具体介绍请参见相关文章。 OAUTH是一种开放的,基于用户登录的授权认证方式。如当用户使用第三方软件调用Google Open API去操作自己的Google服务资源时,用户就要先对该软件授权。授权过程中,第三方软件会引导用户登录Google,进行用户鉴权,用户通过Google身份鉴权后才能对第三方软件授权。显然,Google OAUTH只能对Google用户进行鉴权,其他用户体系的用户不能直接鉴权。 OpenID是一种开放的,去用户中心的,用于打通各网站之间的用户体系的服务。在支持OpenID的网站间,你可以使用任何一个网站的帐号或者Open ID去登录任何一个网站。OpenID提供了类似单点登录的用户体验,并且用户无需在各个网站上注册就可以使用该网站的资源,将用户从繁重的帐号注册与管理工作中解脱出来。当用户使用OpenID登录没注册的网站过程中,网站会引导用户登录OP(用户OpenID注册的网站),请求OP对用户身份鉴权,用户通过OP鉴权,网站才会容许用户登录。 若将OpenID与Google OAUTH结合,OpenID将第三方网站的用户体系与Google用户体系打通后,第三方网站便可使用Google OAUTH服务,对自己的用户进行授权!交互示意图如下图所示: 二、 Google OAUTH + OpenID解决方案 Google提出了OpenID + OAUTH的解决方案,将两者揉合在一起,具体流程如下图所示: 1. Web应用请求用户登录; 2. 用户选择使用Google OpenID进行登录; 3. Web应用请求发现Google认证服务URL; 4. Google向Web应用返回XRDS信息,其中包含Google认证服务URL; 5. Web应用请求用户登录Google服务,通过请求用户授权; 6. Google引导用户登录; 7. 用户输入用户名密码进行登录,同时确认是否对第三方软件授权; 8. Google认证中心返回用户ID与授权的Request Token给Web应用; 9. 用户可以访问受保护的资源,同时可以继续第七部中Oauth认证余下的环节; 从上面的流程第五步可以看出,Google解决方案中,将OAUTH与OpenID的登录操作合并在一起、并且在登录的同时向Google发送Oauth请求,请求用户授权。这样一来,在第五步中,用户登录Google(OpenID中Google对用户鉴权),同时请求对用户授权(OAUTH中对用户授权,同时无需再次登陆,因为前面OpenID已经登录过了)。 三、Google OAUTH+OpenID Demo Google提供了OAUTH + OpenID的DEMO,Demo演示地址如下:http://googlecodesamples.com/hybrid/ 刚开始,用户既没OpenID登录也没OAUTH授权,如下图所示: 接着,点击上图中login按钮请求以Google提供的OpenID登录,如下图所示: 输入用户名与密码登录后,Google提醒您即将登陆到外部网站,外部网站申请对您的资源进行授权,您是否同意,如下图所示: 点击继续登录后,登录成功,并且返回授权的Token,如下图所示: 参见: http://blog.ureshika.com/archives/765.html http://blog.ureshika.com/archives/496.html Continue reading 【转】Google OAUTH + OpenID解决方案 好文,忍不住转载了,转自http://blog.csdn.net/hereweare2009/article/details/3968582 ,蓝色字是我加的注解或是着重提示。 摘要:OAUTH协议为用户资源的授权提供了一个安全的、开放而又简易的标准。与以往的授权方式不同之处是OAUTH的授权不会使第三方触及到用户的帐号信息(如用户名与密码),即第三方无需使用用户的用户名与密码就可以申请获得该用户资源的授权,因此OAUTH是安全的。同时,任何第三方都可以使用OAUTH认证服务,任何服务提供商都可以实现自身的OAUTH认证服务,因而OAUTH是开放的。业界提供了OAUTH的多种实现如PHP,JavaScript,Java,Ruby等各种语言开发包,大大节约了程序员的时间,因而OAUTH是简易的。目前互联网很多服务如Open API,很多大头公司如Google,Yahoo,Microsoft等都提供了OAUTH认证服务,这些都足以说明OAUTH标准逐渐成为开放资源授权的标准。 一、OAUTH产生的背景 典型案例:如果一个用户拥有两项服务:一项服务是图片在线存储服务A,另一个是图片在线打印服务B。如下图所示。由于服务A与服务B是由两家不同的服务提供商提供的,所以用户在这两家服务提供商的网站上各自注册了两个用户,假设这两个用户名各不相同,密码也各不相同。当用户要使用服务B打印存储在服务A上的图片时,用户该如何处理?法一:用户可能先将待打印的图片从服务A上下载下来并上传到服务B上打印,这种方式安全但处理比较繁琐,效率低下;法二:用户将在服务A上注册的用户名与密码提供给服务B,服务B使用用户的帐号再去服务A处下载待打印的图片,这种方式效率是提高了,但是安全性大大降低了,服务B可以使用用户的用户名与密码去服务A上查看甚至篡改用户的资源。 很多公司和个人都尝试解决这类问题,包括Google、Yahoo、Microsoft,这也促使OAUTH项目组的产生。OAuth是由Blaine Cook、Chris Messina、Larry Halff 及David Recordon共同发起的,目的在于为API访问授权提供一个开放的标准。OAuth规范的1.0版于2007年12月4日发布。通过官方网址:http://oauth.net可以阅读更多的相关信息。 二、OAUTH简介 在官方网站的首页,可以看到下面这段简介: An open protocol to allow secure API authorization in a simple and standard method from desktop and web applications. 大概意思是说OAUTH是一种开放的协议,为桌面程序或者基于BS的web应用提供了一种简单的,标准的方式去访问需要用户授权的API服务。OAUTH类似于Flickr Auth、Google's AuthSub、Yahoo's BBAuth、 Facebook Auth等。OAUTH认证授权具有以下特点: 1. 简单:不管是OAUTH服务提供者还是应用开发者,都很容易于理解与使用; 2. 安全:没有涉及到用户密钥等信息,更安全更灵活; 3. 开放:任何服务提供商都可以实现OAUTH,任何软件开发商都可以使用OAUTH; 三、OAUTH相关术语 在弄清楚OAUTH流程之前,我们先了解下OAUTH的一些术语的定义: OAUTH HTTP响应代码: 四、OAUTH认证授权流程 在弄清楚了OAUTH的术语后,我们可以对OAUTH认证授权的流程进行初步认识。其实,简单的来说,OAUTH认证授权就三个步骤,三句话可以概括: 1. 获取未授权的Request Token 2. 获取用户授权的Request Token 3. 用授权的Request Token换取Access Token 当应用拿到Access Token后,就可以有权访问用户授权的资源了。大家肯能看出来了,这三个步骤不就是对应OAUTH的三个URL服务地址嘛。一点没错,上面的三个步骤中,每个步骤分别请求一个URL,并且收到相关信息,并且拿到上步的相关信息去请求接下来的URL直到拿到Access Token。具体的步骤如下图所示: 具体每步执行信息如下: A. 使用者(第三方软件)向OAUTH服务提供商请求未授权的Request Token。向Request Token URL发起请求,请求需要带上的参数见上图。 B. OAUTH服务提供商同意使用者的请求,并向其颁发未经用户授权的oauth_token与对应的oauth_token_secret,并返回给使用者。 C. 使用者向OAUTH服务提供商请求用户授权的Request Token。向User Authorization URL发起请求,请求带上上步拿到的未授权的token与其密钥。 D. OAUTH服务提供商将引导用户授权。该过程可能会提示用户,你想将哪些受保护的资源授权给该应用。此步可能会返回授权的Request Token也可能不返回。如Yahoo OAUTH就不会返回任何信息给使用者。 E. Request Token 授权后,使用者将向Access Token URL发起请求,将上步授权的Request Token换取成Access Token。请求的参数见上图,这个比第一步A多了一个参数就是Request Token。 F. OAUTH服务提供商同意使用者的请求,并向其颁发Access Token与对应的密钥,并返回给使用者。 G. 使用者以后就可以使用上步返回的Access Token访问用户授权的资源。 从上面的步骤可以看出,用户始终没有将其用户名与密码等信息提供给使用者(第三方软件),从而更安全。用OAUTH实现背景一节中的典型案例:当服务B(打印服务)要访问用户的服务A(图片服务)时,通过OAUTH机制,服务B向服务A请求未经用户授权的Request Token后,服务A将引导用户在服务A的网站上登录,并询问用户是否将图片服务授权给服务B。用户同意后,服务B就可以访问用户在服务A上的图片服务。整个过程服务B没有触及到用户在服务A的帐号信息。如下图所示,图中的字母对应OAUTH流程中的字母: 五、OAUTH服务提供商 OAUTH标准提出到现在不到两年,但取得了很大成功。不仅提供了各种语言的版本库,甚至Google,Yahoo,Microsoft等等互联网大头都实现了OAUTH协议。由于OAUTH的client包有很多,所以我们就没有必要在去自己写,避免重复造轮子,直接拿过来用就行了。我使用了这些库去访问Yahoo OAUTH服务,很不错哦!下面就贴出一些图片跟大家一起分享下! 下图是OAUTH服务提供商引导用户登录(若用户开始没有登录) 下图是提示用户将要授权给第三方应用,是否同意授权的页面 下图提示用户已授权成功的信息 一些服务提供商不仅仅仅实现了OAUTH协议上的功能,还提供了一些更友好的服务,比如管理第三方软件的授权服务。下图就是YAHOO管理软件授权的页面,用户可以取消都某些应用的授权。 参见: http://blog.ureshika.com/archives/765.html http://blog.ureshika.com/archives/496.html Continue reading 【转】OAUTH协议简介 转自 http://blog.sina.com.cn/s/blog_5f53615f0100qdxc.html ,原文不知出处。 蓝色字是我的加重或是注解。 今天看完了日本人mixi写的“memcached全面剖析”的系列文章,结合我在项目中使用memcache的经验,再谈谈memcache在大型网站中的应用策略。 【部署策略】 基于memcached的slab和dump的内存管理方式,它产生的内存碎片比较少,不需要OS去做繁杂的内存回收,所以它对CPU的占用率那是相当的低。所以建议将它跟占用CPU较高的WEB服务器一起使用来节省成本。当然如果你有大量的廉价PC,那用来专门做memcached服务器也不错。由于32位操作系统中,每个进程最多只能使用2GB内存,所以如果你有大内存的话,可以以daemon的方式启动两个以上的memcached服务,或者干脆用64位的CPU和OS。 【服务监控】 memcached支持分布式机制,php通过memcache::addserver来实现该机制,它实现了如果服务器列表中的一台down掉的时候在参数retry_interval指定的时间就不会再连接该服务器的机制。所以只要你在该时间段内重启或者修复了该服务器,则不会对前端造成太大的影响。当然了,如果你一直不去重启该服务器的话,我测试过addserver再次连接一台down掉的服务器的时间将比平时延长了1秒的时间。可以通过addserver的最后一个参数failure_callback定义一个回调函数来实现邮件通知或者短信通知管理员的功能。 如果是手工重启,我建议将该值设置为20分钟。不过对于memcached进程死掉的服务器,只要重新启动memcached,就可以正常运行,所以采用了监视memcached进程并自动启动的方法的效果最好。mixi推荐的工具:nagios,daemontool 【应用策略】 memcached主要的作用是为减轻大访问量对数据库的冲击,所以一般的逻辑是首先从memcached中读取数据,如果没有就从数据库中读取数据写入到memcache中,等下一次读取的时候就可以从memcached中读取了。但在项目中的具体应用策略(也就是哪些数据应该缓存?怎么样缓存?过期策略?)就是个问题了。它的一个总原则是将经常需要从数据库读取的数据缓存在memcached中。这些数据也分为几类: 一、经常被读取并且实时性要求不强可以等到自动过期的数据。例如网站首页最新文章列表、某某排行等数据。也就是虽然新数据产生了,但对用户体验不会产生任何影响的场景。 二、经常被读取并且实时性要求强的数据。比如用户的好友列表,用户文章列表,用户阅读记录等。 三、统计类缓存,比如文章浏览数、网站PV等 四、活跃用户的基本信息或者某篇热门文章。 [PS:第五点哪去了?] 六、session数据 【总结】 【后记】 二、memcached不支持检索的功能,在实际使用中比如我们想把一个IP表放在memcached中,来检索某一个IP属于那个地区的话,有了检索功能就方便多了。希望他在以后的版本中能提供该功能。暂时可以通过排序存储和二分法在客户端实现。 三、memcached1.2.2版本确实有不稳定的情况,有时候会出现DOWN机,强烈建议升级至1.2.6的版本。见官方说明:Version 1.2.6 released. Major crash fixes, DTrace support, minor updates. If you have stability issues with any previous release, please upgrade to this one. Continue reading 【转】memcache在大型网站的应用策略 现在我一个javascript文件里面写的代码一般就有一千多行,原因主要是用闭包啊,不想搞太多的变量空间引用麻烦。一般来说eclipse的outline视图很好用,将所有函数都列出来了,但是有几次原本好好地outline结构什么都没有了,让我切换函数非常麻烦,查找一下原因,原来对于函数中return 一个json对象的写法造成outline失效了: 解决办法: function a(){ } 这个问题对EXTJS的源码很头疼,因为里面一堆的return {}; 估计他们不是用eclipse开发的吧,也许牛人既不需要outline视图,LOL. Continue reading eclipse outline视图对于javascript的bug openfire配置杂记
xmpphp 的一些补丁
"Cannot modify header information" php 的恼火问题
http抓包分析工具
unload事件,刷新,顺序,不靠谱
16:13:48 445766772 get
16:13:48 445766787 unload
16:36:13 447111240 get
16:36:13 447111274 unload
16:33:08 446926865 get
16:33:08 446926842 unload
16:38:08 447226350 get
16:38:08 447226386 unload
16:39:39 447317584 get 【转】Google OAUTH + OpenID解决方案

【转】OAUTH协议简介
【转】memcache在大型网站的应用策略
这类数据就使用典型的缓存策略,设置一过合理的过期时间,当数据过期以后再从数据库中读取。当然你得制定一个缓存清除策略,便于编辑或者其它人员能马上看到效果。
这类数据首先被载入到memcached中,当发生更改(添加、修改、删除)时就清除缓存。在缓存的时候,我将查询的SQL语句md5()得到它的hash值作为key,结果数组作为值写入memcached,并且将该SQL涉及的table_name以及hash值配对存入memcached中。当更改了这个表时,我就将与此表相配对的key的缓存全部删除。
此类缓存是将在数据库的中来累加的数据放在memcached来累加。获取也通过memcached来获取。但这样就产生了一个问题,如果memcached服务器down掉的话这些数据就有可能丢失,所以一般使用memcached的永固性存储,这方面我们新浪使用memcachedb。[PS:这是nosql的地盘了]
此类数据的一个特点就是数据都是一行,也就是一个一维数组,当数据被update时(比如修改昵称、文章的评论数),在更改数据库数据的同时,使用Memcache::replace替换掉缓存里的数据。这样就有效了避免了再次查询数据库。
使用memcached来存储session的效率是最高的。memcached本身也是非常稳定的,不太用担心它会突然down掉引起session数据的丢失,即使丢失就重新登录了,也没啥。见[多服务器session共享之memcache共享]
通过以上的策略数据库的压力将会被大大减轻。检验你使用memcached是否得当的方法是查看memcached的命中率。有些策略好的网站的命中率可以到达到90%以上。
一、memcached暂时还不支持故障转移,希望在以后的版本中能支持该功能。当然你可以使用日本人平林幹雄的Tokyo Tyrant 来代替memcached,它支持memcached协议,支持永固性存储和故障转移[这个似乎并不是memcached本身语义该做的事情吧]。但我没有在生产环境中使用过,也没有相关的性能测试数据。以后会试用一下这个东东。 eclipse outline视图对于javascript的bug
function a(){
return {}; //这里会造成outline问题
}
var o = {};
return o;Pagination

