之前写过httpclient 在android上的问题(http://blog.ureshika.com/archives/947.html),后来曾想过完全抛弃httpclient,但是这次使用jvm上的httpurlconnection又碰到个问题。
httpurlconnection的问题:
当请求返回的是400之类的错误码时,则直接抛异常,得不到返回体。这个对于RESTFul请求就不太好了,因为它的返回体有时也包含了具体错误信息,客户端是要用的。而httpclient则没这个问题。
httpclient主要是在android上的问题:
google不推荐使用,版本保持在4.0.1不再更新,可想之后前途。
总结下:
jvm上还是用httpclient吧,Dalvik VM上Android2.3(Gingerbread)之后建议httpurlconnection。
Continue reading apache httpclient及httpurlconnection的问题
以前解决8小时问题通过设置不起作用,后来使用poxool池就可以
这次发现dbcp还是好些,可能还是配置问题:
http://stackoverflow.com/questions/8535433/spring-app-losing-connection-to-mysql-after-8-hours-how-to-properly-configure
从其答案中说是需要配置:
testWhileIdle, validationQuery and timeBetweenEvictionRunsMillis
这里有个例子
validationQuery = "SELECT 1"
testWhileIdle = "true"
timeBetweenEvictionRunsMillis = "3600000"
minEvictableIdleTimeMillis = "18000000"
testOnBorrow = "true"
有人说
timeBetweenEvictionRunsMillis
这个值不能设置>time_out
但http://stackoverflow.com/questions/15949/javatomcat-dying-database-connection
几个例子都比它大,所以应该是要设置testWhileIdle=true
dbcp文档:
http://commons.apache.org/dbcp/configuration.html
Continue reading mysql 8小时解决
今天又遇到maven问题:cannot be read or is not a valid ZIP file
工程是导入的,在别的机器上好好地,导入到我的机器上就出了问题。
我的是maven3,仓库是默认的。
打开报错的jar文件,好好地,没什么问题。
最后发现在eclipse里面打开这些包里的类却是报错。
看来还是包没有正确下下来。没办法只好将包从本地仓库中删掉,再更新maven 依赖。终于解决了。解决一个包的问题又出现另外的包同样的错,一个一个同样的解决办法,要是想爽快,干脆将整个本地仓库删掉再更新maven依赖。
你还得感谢它还报了个错,等我运行时,还是发现这类没找到,那类没找到,同样,删吧,更新……
就这样弄环境就花了两个小时,maven就是强。
导入maven工程很容易出现这种情况。
但最终都是maven这个怪物的问题,
Continue reading cannot be read or is not a valid ZIP file问题
注意:这里的int是mysql整形统称, 因为datetime是8字节,所以对应是应由mysql bigint代替,timestamp是4字节,可由mysql int代替,一般java,php时间戳应该是由mysql bigint才能完全存储,mysql int长度不够。
今天又纠结数据库里时间存储的问题,以往的经验,时区问题很繁琐,而mysql的date,datetime,timestamp都是和时区设置有关系的。(当然)
我认为一般设计数据库,时间存储的应该是UTC时间,这样便于物理和逻辑上的移植,对于国际化功能的应用更是如此。可以省去许多时区转换的麻烦,可以维持一致性。
网上也有这方面的讨论,大部分赞同int
例如:
对于性能,
下面的这篇文章的测试我认为具有片面性
其测试认为int 比datetime慢,但是其测试语句使用了相当多的mysql 日期函数,我们根本就不需要这样做,我们不需要使用数据库的日期函数,只要保证传入数据库的参数是int,像日期比较直接用int比较实际是比datetime要快的。
参照openfire的mysql设计,发现它根本就没有使用任何datetime,timestamp类型。而是用bigint或是char。
我的观点:
对于应用型数据库,不应该使用datetime。
对于需要在sql中嵌入逻辑的例如分析型数据仓库,数据管理员可能会倾向于使用datetime。
参见:
http://billauer.co.il/blog/2009/03/mysql-datetime-epoch-unix-time/
http://gpshumano.blogs.dri.pt/2009/07/06/mysql-datetime-vs-timestamp-vs-int-performance-and-benchmarking-with-myisam/
Continue reading mysql 时间字段使用int还是datetime …
今天才发现原来还有 p6spy http://sourceforge.net/projects/p6spy 这么个东东,相见恨晚,想当年为自己基于jdbc手写了整个数据访问层的时候,还得意可提供完整的sql日志 。
。
这里记一下spring配置:
Maven
首先maven 见http://mvnrepository.com/artifact/p6spy/p6spy/1.3
<dependency>
<groupId>p6spy</groupId>
<artifactId>p6spy</artifactId>
<version>1.3</version>
</dependency>
配置spring:
<bean id="orginDataSource"
class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="${database.jdbc.driverClassName}"/>
<property name="url" value="${database.jdbc.url}"/>
<property name="username" value="${database.jdbc.username}"/>
<property name="password" value="${database.jdbc.password}"/>
<property name="testWhileIdle" value="true"/>
<property name="timeBetweenEvictionRunsMillis" value="3600000"/>
<property name="validationQuery" value="SELECT 1"/>
<property name="minEvictableIdleTimeMillis" value="18000000"/>
<property name="testOnBorrow" value="true"/>
</bean>
<bean id="dataSource" class="com.p6spy.engine.spy.P6DataSource" >
<constructor-arg>
<ref local="orginDataSource"/>
</constructor-arg>
</bean>
我用的dbcp连接池,加入p6spy还是比较方便的。注意dataSource这个bean才是被注入到程序中的bean,它只是包装了orginDataSource这个bean。另外网上的配置都有destroy-method="close"这个,我看了下的包,p6spyDataSource这个类根本就没有close方法,不知是版本问题还是怎的。
最后配置spy.properties
https://code.google.com/p/p6spy-mvn/downloads/list 这里有例子,直接下下来放在/src/main/resources文件夹中
针对你的实际情况修改,这里我需要使用log4j日志
不需要realdriver这个配置,都可以注释掉,因为使用的是包装方式
#realdriver=oracle.jdbc.driver.OracleDriver
需要下面的配置
module.log=com.p6spy.engine.logging.P6LogFactory
appender=com.p6spy.engine.logging.appender.Log4jLogger
#这些配置和log4j是一样的
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4j.appender.STDOUT.layout=org.apache.log4j.PatternLayout
log4j.appender.STDOUT.layout.ConversionPattern=p6spy - %m%n
#可以使用系统变量的
log4j.appender.ROLLING_FILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLING_FILE.File=${conf}/xxx.log
log4j.appender.ROLLING_FILE.Append=true
log4j.appender.ROLLING_FILE.MaxFileSize=10000KB
log4j.appender.ROLLING_FILE.MaxBackupIndex=10
log4j.appender.ROLLING_FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.ROLLING_FILE.layout.ConversionPattern=%5p [%d{yy-MM-dd HH:mm:ss,SSS}] [%t] - %m%n
log4j.logger.p6spy=INFO,STDOUT,ROLLING_FILE
好了,运行后就会发现类似输出:
INFO [13-02-21 14:30:50,906] [main] - 1361428250906|0|0|statement|select * from tbl_xxx where 1=1 and rpt = ? and id = ? and active = ?|select * from tbl_xxx where 1=1 and rpt = 'false' and id = '0' and active = 'true'
可见最后一个是实际的sql语句,不过这样有点麻烦,需要拖动横向滚动条才能看到,还是我的显示屏不够宽哈, 。
。
另外可以使用工具来分析作为性能参考。
参见:
http://swik.net/Spring/Spring%27s+corner/Integrate+P6Spy+with+Spring/vq6
http://www.mkyong.com/hibernate/how-to-display-hibernate-sql-parameter-values-solution/
http://www.iteye.com/topic/28880
Continue reading java中使用P6Spy 打印sql
原文不知出处,这是转自http://wenku.baidu.com/view/1ecebb1db7360b4c2e3f6438.html 我做了些排版便于阅读,蓝色字是我的注解。
最近用spring,整理了一下对它的事务的认识,找到这篇文章,正好可作为参照。其实用惯了java,很多东西都被它搞复杂了,认识事务还需要看我的其他文章:
三级封锁协议两段锁以及隔离级别
spring ejb3 jta 事务泛谈 (原来已经整理过一回)
数据库同步–可别忘记了
JDBC事务和JTA (XA)事务
事务简介
一般情况下,J2EE应用服务器支持JDBC事务、JTA(Java Transaction API)事务(一般由容器来进行管理)。通常,最好不要在程序中同时使用上述三种事务类型,比如在JTA事务中嵌套JDBC事务。第二方面,事务要在尽可能短的时间内完成,不要在不同方法中实现事务的使用(事务的嵌套要求更加良好的设计)。
JDBC事务
在JDBC中怎样将多个SQL语句组合成一个事务呢?在JDBC中,打开一个连接对象Connection时,缺省是auto-commit模式,每个SQL语句都被当作一个事务,即每次执行一个语句,都会自动的得到事务确认。为了能将多个SQL语句组合成一个事务,要将auto-commit模式屏蔽掉。在auto-commit模式屏蔽掉之后,如果不调用commit()方法,SQL语句不会得到事务确认。在最近一次commit()方法调用之后的所有SQL会在方法commit()调用时得到确认。例如下面的代码:
/**
* 测试Jboss中的JDBC事务
*
@author javer QQ:84831612
* @date 2005
*/
jjava.sql.Connection conn = null;
try{
javax.sql.DataSource ds = (javax.sql.DataSource) context.lookup("java:/OracleDS");
conn = ds.getConnection();
conn.setAutoCommit(false);
java.sql.Statement statement = conn.createStatement();
/**
*
* 数据库操作
*
*/
conn.commit();
} catch (Exception e) {
if(conn!=null)
try{conn.rollback();}catch(Exception e1){out.println("catch:事务回滚失败!
");}
out.println("catch:" + e.getClass() + ";" + e.getMessage()+"
");
}finally{
if(conn!=null)
try{conn.close();}catch(Exception e1){out.println("finally:关闭数据库连接失败!
");}
}
毕竟JDBC事务大多数程序员可能经常使用,而且比较相对简单,就不作过多的描述了
JTA (XA)事务
Java 事务 API(JTA) 及其同门兄弟 Java 事务服务(Java Transaction Service JTS)为 J2EE 平台提供了分布式事务服务。一个分布式的事务涉及一个事务管理器和一个或者多个资源管理器。一个资源管理器是任何类型的持久性的数据存储。事务管理器负责协调所有事务参与者之间的通信。
与本地事务相比,XA 协议的系统开销相当大,因而应当慎重考虑是否确实需要分布式事务。只有支持 XA 协议的资源才能参与分布式事务。如果事务须登记一个以上的资源,则需要实现和配置所涉及的资源(适配器、JMS 或 JDBC 连接池)以支持 XA。
JTA事务工作流程
WEB服务器(比如:WebLogic Server)将根据以下条件返回不同种类的包装器:
1、所使用的 JDBC 驱动程序类是否支持 XA
2、是从 DataSource 还是从 TxDataSource 获得连接
3、调用 getConnection() 时是否在事务内运行
4、是否通过 RMI 从远程获得连接
决定返回哪种包装器的算法的工作方式如下:
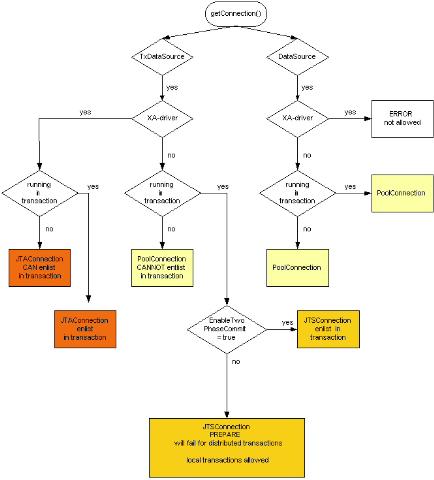
JTA实例代码
/**
* 测试Jboss中的JTA事务
*
@author javer QQ:84831612
* @date 2005
*/
javax.transaction.UserTransaction tx = null;
java.sql.Connection conn = null;
try{
tx = (javax.transaction.UserTransaction) context.lookup("java:comp/UserTransaction"); //取得JTA事务,本例中是由Jboss容器管理
javax.sql.DataSource ds = (javax.sql.DataSource) context.lookup("java:/XAOracleDS"); //取得数据库连接池,必须有支持XA的数据库、驱动程序
tx.begin();
conn = ds.getConnection();
//conn.setAutoCommit(false);
java.sql.Statement statement = conn.createStatement();
String sql = "insert into testtable (cell1,cell2,cell3,cell4) values('"+System.currentTimeMillis()+"','','','')";
int insert = statement.executeUpdate(sql);
//conn.commit(); //JTA事务中不要嵌套JDBC事务啦!!!重要,切记,否则会抛出异常!!!
out.println("插入了" + insert + "行记录!
");
if(true)throw new Exception("故意抛出的异常!");
int num = statement.executeUpdate("delete testtable");
out.println("删除了" + num + "行记录!
");
tx.commit();
} catch (Exception e) {
if(tx!=null)
try{tx.rollback();}catch(Exception e1){out.println("catch:事务回滚失败!
");}
out.println("catch:" + e.getClass() + ";" + e.getMessage()+"
");
}finally{
if(conn!=null)
try{conn.close();}catch(Exception e1){out.println("finally:关闭数据库连接失败!
");}
}
===========原文:http://blog.csdn.net/muzijie927/archive/2006/10/27/1353307.aspx
__________________________________________________________________________________________________________
JTA初级研究
JTA和JDBC事务
一般情况下,J2EE应用服务器支持JDBC事务、JTA事务、容器管理事务。这里讨论JTA和JDBC事务的区别。这2个是常用的DAO模式事务界定方式。
JDBC 事务
JDBC 事务是用 Connection 对象控制的。JDBC Connection 接口( java.sql.Connection )提供了两种事务模式:自动提交和手工提交。
★ 在jdbc中,事务操作缺省是自动提交。也就是说,一条对数据库的更新表达式代表一项事务操作,操作成功后,系统将自动调用commit()来提交,否则将调用rollback()来回滚。
★ 在jdbc中,可以通过调用setAutoCommit(false)来禁止自动提交。之后就可以把多个数据库操作的表达式作为一个事务,在操作完成后调 用commit()来进行整体提交,倘若其中一个表达式操作失败,都不会执行到commit(),并且将产生响应的异常;此时就可以在异常捕获时调用 rollback()进行回滚。这样做可以保持多次更新操作后,相关数据的一致性,示例如下:
try {
conn =
DriverManager.getConnection
("jdbc:oracle:thin:@host:1521:SID","username","userpwd";
conn.setAutoCommit(false);//禁止自动提交,设置回滚点
stmt = conn.createStatement();
stmt.executeUpdate(“alter table …”); //数据库更新操作1
stmt.executeUpdate(“insert into table …”); //数据库更新操作2
conn.commit(); //事务提交
}catch(Exception ex) {
ex.printStackTrace();
try {
conn.rollback(); //操作不成功则回滚
}catch(Exception e) {
e.printStackTrace();
}
}
JDBC 事务的一个缺点是事务的范围局限于一个数据库连接。一个 JDBC 事务不能跨越多个数据库。
JTA事务
JTA(Java Transaction API) 为 J2EE 平台提供了分布式事务服务。
要用 JTA 进行事务界定,应用程序要调用 javax.transaction.UserTransaction 接口中的方法。例如:
utx.begin();
// ...
DataSource ds = obtainXADataSource();
Connection conn = ds.getConnection();
pstmt = conn.prepareStatement("UPDATE MOVIES ...");
pstmt.setString(1, "Spinal Tap");
pstmt.executeUpdate();
// ...
utx.commit();
让我们来关注下面的话:
“用 JTA 界定事务,那么就需要有一个实现 javax.sql.XADataSource 、 javax.sql.XAConnection 和 javax.sql.XAResource 接口的 JDBC 驱动程序。一个实现了这些接口的驱动程序将可以参与 JTA 事务。一个 XADataSource 对象就是一个 XAConnection 对象的工厂。 XAConnection s 是参与 JTA 事务的 JDBC 连接。”
要使用JTA事务,必须使用XADataSource来产生数据库连接,产生的连接为一个XA连接。
XA连接(javax.sql.XAConnection)和非XA(java.sql.Connection)连接的区别在于:XA可以参与JTA的事务,而且不支持自动提交。
Note:
Oracle, Sybase, DB2, SQL Server等大型数据库才支持XA, 支持分布事务。
My SQL 连本地都支持不好,更别说分布事务了。[PS:这么鄙视mysql?……]
JTA方式的实现过程:
用XADataSource产生的XAConnection它扩展了一个getXAResource()方法,事务通过这个方法把它加入到事务容器中进行 管理.对于调用者来说,根本看不到事务是如果管理的,你只要声明开始事务,告诉容器我下面的操作要求事务参与了,最后告诉事务说到这儿可以提交或回滚了, 别的都是黑箱操作。
在使用JTA之前,你必须首先实现一个Xid类用来标识事务(在普通情况下这将由事务管理程序来处理)。Xid包含三个元素:formatID、gtrid(全局事务标识符)和bqual(分支修饰词标识符)。
下面的例子说明Xid的实现:
import javax.transaction.xa.*;
public class MyXid implements Xid
{
protected int formatId;
protected byte gtrid[];
protected byte bqual[];
public MyXid()
{
}
public MyXid(int formatId, byte gtrid[], byte bqual[])
{
this.formatId = formatId;
this.gtrid = gtrid;
this.bqual = bqual;
}
public int getFormatId()
{
return formatId;
}
public byte[] getBranchQualifier()
{
return bqual;
}
public byte[] getGlobalTransactionId()
{
return gtrid;
}
}
其次,你需要创建一个你要使用的数据库的数据源:
public DataSource getDataSource()
throws SQLException
{
SQLServerDataSource xaDS = new
com.merant.datadirect.jdbcx.sqlserver.SQLServerDataSource();
xaDS.setDataSourceName("SQLServer");
xaDS.setServerName("server");
xaDS.setPortNumber(1433);
xaDS.setSelectMethod("cursor");
return xaDS;
}
例1?这个例子是用“两步提交协议”来提交一个事务分支:
XADataSource xaDS;
XAConnection xaCon;
XAResource xaRes;
Xid xid;
Connection con;
Statement stmt;
int ret;
xaDS = getDataSource();
xaCon = xaDS.getXAConnection("jdbc_user", "jdbc_password");
xaRes = xaCon.getXAResource();
con = xaCon.getConnection();
stmt = con.createStatement();
xid = new MyXid(100, new byte[]{0x01}, new byte[]{0x02});
try {
xaRes.start(xid, XAResource.TMNOFLAGS);
stmt.executeUpdate("insert into test_table values (100)");
xaRes.end(xid, XAResource.TMSUCCESS);
ret = xaRes.prepare(xid);
if (ret == XAResource.XA_OK) {
xaRes.commit(xid, false);
}
}
catch (XAException e) {
e.printStackTrace();
}
finally {
stmt.close();
con.close();
xaCon.close();
}
当然,实际过程中,我们不需要写这些代码,这些代码是JTA最终的实现代码。
(那么再往里面一层,它对于数据库是怎么实现的?jdbc对于数据库又是怎样实现事务的?还是调用各数据库提供的封锁协议以及两段锁实现来达到目的的。)
关于“两步提交协议”,可以参看下面的文章:(建议还是看三级封锁协议两段锁以及隔离级别)
http://www.ibm.com/developerworks/cn/db2/library/techarticles/dm-0505weber/index.html
两阶段提交(Two-Phase-Commit)协议
首先,两阶段提交(Two-Phase-Commit)事务的启动与常规的单阶段提交(One-Phase-Commit)事务类似。接着,应用程序/客 户机对该两阶段提交(Two-Phase-Commit)操作中所涉及的所有数据库执行其修改工作。现在,在最终提交该事务之前,客户机通知参与的数据库准备提交(第 1 阶段)。如果客户机从数据库收到一条“okay”,就发出命令向数据库提交该事务(第 2 阶段)。最后分布式事务(Distributed Transaction)结束。
本文中的例子演示了如何在 Java 中使用 JTA 实现两阶段提交(Two-Phase-Commit)协议。在该应用程序中,如果一个事务分支报告了错误,您就要负责进行错误处理。但是“两阶段提交协议 简介”小节中提到仍然存在一个问题,那就是如果第 2 阶段中一个事务分支发生故障,该怎么办呢?
如果再次查看程序代码,您可以看到在“第 1 阶段”和“第 2 阶段”之间有一个很小的时间间隔。在这一时间间隔中,出于某种理由,其中某一参与数据库可能崩溃。如果发生了,我们将陷入分布式事务已经部分提交的情形中。
假 定下列情形:在“第 1 阶段”之后,您从 DB2 和 IDS 数据库中都收到了“okay”。在下一步中,应用程序成功提交了 DB2 的事务分支。接着,应用程序通知 DB2 事务分支提交事务。现在,在应用程序可以通知 IDS 事务分支提交它这一部分之前,IDS 引擎由于断电发生崩溃。这就是一种部分提交全局事务的情形。您现在该怎么办呢?
在重启之后,DB2 和 IDS 都将尝试恢复打开的事务分支。该引擎等待来自应用程序的提示如何做。如果应用程序没有准备重新发送“第 2 阶段”的提交,该事务分支将被引擎所启动的试探性回滚中止。这是非常糟糕的,因为这将使该全局事务处于不一致状态。
一种解决方案是用一个小型应用程序连接引擎中打开的事务分支,并通知引擎提交或回滚这一打开的事务。如果您使用 IDS 作为后端,那么还有一个隐藏的 onmode 标志,允许您结束打开的事务分支。(onmode -Z xid)。
在 DB2 UDB 中,您可以发出 LIST INDOUBT TRANSACTIONS 来获得打开的 XA 事务的有关信息。您必须查看 DB2 Information Center 中的描述来解决该问题。
上面描述的情形是一个很好的例子,也是使用应用程序服务器(Application Server)或事务监控器(Transaction Monitor)的理由。在使用一个中间层服务器时,就由该服务器负责保持事情正常。
PS:针对java,spring层面的事务总结一下:
单数据源事务最终还是jdbc到数据库的连接事务,所以你要注意同步问题,数据库同步–可别忘记了。如果使用spring事务管理机制则不需要考虑这个问题。即使你将同一个数据源实例赋值给多个数据操作Bean,那也没关系,因为spring会保证同一个线程是同一个连接嘛(SingleConnectionDataSource除外),如果你的程序是多个线程共一个连接,例如使用SingleConnectionDataSource,那就不能不支持多线程了。
这篇文章 http://blog.sina.com.cn/s/blog_53dd74430100haaj.html 分析了spring事务管理实现。
多数据源那就有点麻烦,那就需要使用分布式事务管理,例如JTA. 你自己实现也可以,:)。
Continue reading 【转】JDBC事务和JTA (XA)事务
the following link explian how trapcall.com work.
http://askville.amazon.com/Trap-Call-work-unmask-blocked-caller-ID-numbers/AnswerViewer.do?requestId=40144836
And
I have had a investigation with the trapcall, I found it have some limitation to numbers, as I have test two number with me, all is said not supported. I think it maybe have coopration with the carrier.
As I think it need redirect the incomming call to the toll-free number and get its callerid, so if without a mobile app, it need the user to setup the redirect by themself, if with a mobile app, the redirect filter can be done by the mobile app.
Continue reading how trapcall work
有些东西试验了一下,虽不成体系,但是放在博客上还是方便查找,所以芝麻一堆枣一堆的放上来了。
facebook api虽据称”荣获”最差api之列,但是我使用一下似乎还可以。
主要是graphic api和fql
文档:
http://developers.facebook.com/docs/reference/apis/
好用的api浏览器工具:
http://developers.facebook.com/tools/explorer
fql查询某个文档(post,link,图片…)的评论:
SELECT text FROM comment WHERE object_id in (
SELECT id FROM object_url WHERE url = 'http://www.facebook.com/photo.php?fbid=505965652779699&set=a.456536471055951.101000.190638967645704&type=1'
)
上面的链接是随便选的,勿要深究,因为必须是个公开的链接,如果是不公开的链接,那么会返回空数据,你不知道到底是没有评论还是未公开的原因。
Continue reading facebook api笔记

